 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnearthing Gems from Stones: Policy Optimization with Negative Sample Augmentation for LLM Reasoning
May 20, 2025Recent advances in reasoning language models have witnessed a paradigm shift from short to long CoT pattern. Given the substantial computational cost of rollouts in long CoT models, maximizing the utility of fixed training datasets becomes crucial. Our analysis reveals that negative responses contain valuable components such as self-reflection and error-correction steps, yet primary existing methods either completely discard negative samples (RFT) or apply equal penalization across all tokens (RL), failing to leverage these potential learning signals. In light of this, we propose Behavior Constrained Policy Gradient with Negative Sample Augmentation (BCPG-NSA), a fine-grained offline RL framework that encompasses three stages: 1) sample segmentation, 2) consensus-based step correctness assessment combining LLM and PRM judgers, and 3) policy optimization with NSA designed to effectively mine positive steps within negative samples. Experimental results show that BCPG-NSA outperforms baselines on several challenging math/coding reasoning benchmarks using the same training dataset, achieving improved sample efficiency and demonstrating robustness and scalability when extended to multiple iterations.
Beyond the First Error: Process Reward Models for Reflective Mathematical Reasoning
May 20, 2025Many studies focus on data annotation techniques for training effective PRMs. However, current methods encounter a significant issue when applied to long CoT reasoning processes: they tend to focus solely on the first incorrect step and all preceding steps, assuming that all subsequent steps are incorrect. These methods overlook the unique self-correction and reflection mechanisms inherent in long CoT, where correct reasoning steps may still occur after initial reasoning mistakes. To address this issue, we propose a novel data annotation method for PRMs specifically designed to score the long CoT reasoning process. Given that under the reflection pattern, correct and incorrect steps often alternate, we introduce the concepts of Error Propagation and Error Cessation, enhancing PRMs' ability to identify both effective self-correction behaviors and reasoning based on erroneous steps. Leveraging an LLM-based judger for annotation, we collect 1.7 million data samples to train a 7B PRM and evaluate it at both solution and step levels. Experimental results demonstrate that compared to existing open-source PRMs and PRMs trained on open-source datasets, our PRM achieves superior performance across various metrics, including search guidance, BoN, and F1 scores. Compared to widely used MC-based annotation methods, our annotation approach not only achieves higher data efficiency but also delivers superior performance. Detailed analysis is also conducted to demonstrate the stability and generalizability of our method.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Mastering Strategy Card Game via End-to-End Policy and Optimistic Smooth Fictitious Play
Mar 07, 2023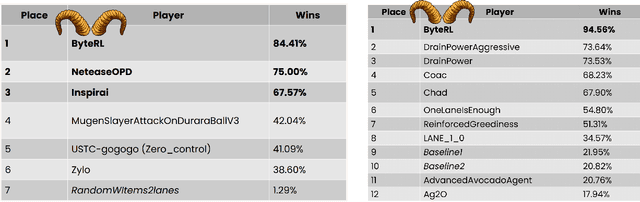
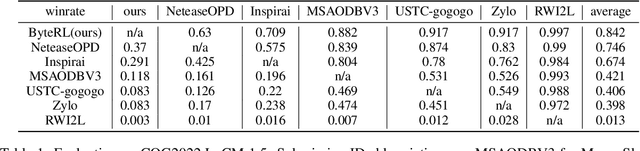

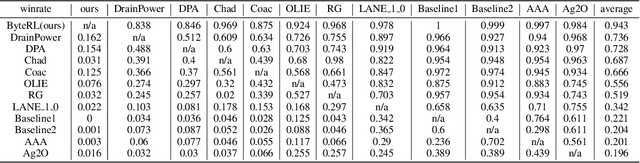
Deep Reinforcement Learning combined with Fictitious Play shows impressive results on many benchmark games, most of which are, however, single-stage. In contrast, real-world decision making problems may consist of multiple stages, where the observation spaces and the action spaces can be completely different across stages. We study a two-stage strategy card game Legends of Code and Magic and propose an end-to-end policy to address the difficulties that arise in multi-stage game. We also propose an optimistic smooth fictitious play algorithm to find the Nash Equilibrium for the two-player game. Our approach wins double championships of COG2022 competition. Extensive studies verify and show the advancement of our approach.
An Entropy Regularization Free Mechanism for Policy-based Reinforcement Learning
Jun 01, 2021



Policy-based reinforcement learning methods suffer from the policy collapse problem. We find valued-based reinforcement learning methods with {\epsilon}-greedy mechanism are capable of enjoying three characteristics, Closed-form Diversity, Objective-invariant Exploration and Adaptive Trade-off, which help value-based methods avoid the policy collapse problem. However, there does not exist a parallel mechanism for policy-based methods that achieves all three characteristics. In this paper, we propose an entropy regularization free mechanism that is designed for policy-based methods, which achieves Closed-form Diversity, Objective-invariant Exploration and Adaptive Trade-off. Our experiments show that our mechanism is super sample-efficient for policy-based methods and boosts a policy-based baseline to a new State-Of-The-Art on Arcade Learning Environment.
CASA: A Bridge Between Gradient of Policy Improvement and Policy Evaluation
May 27, 2021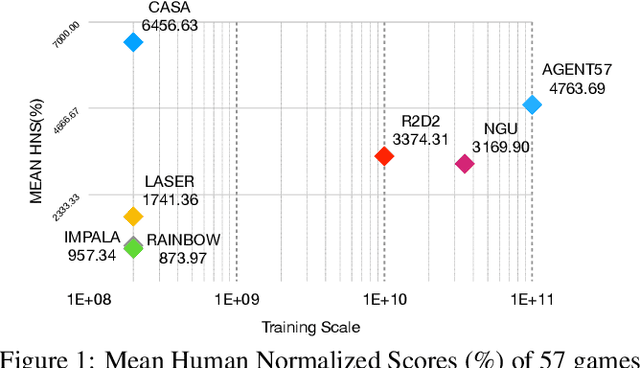
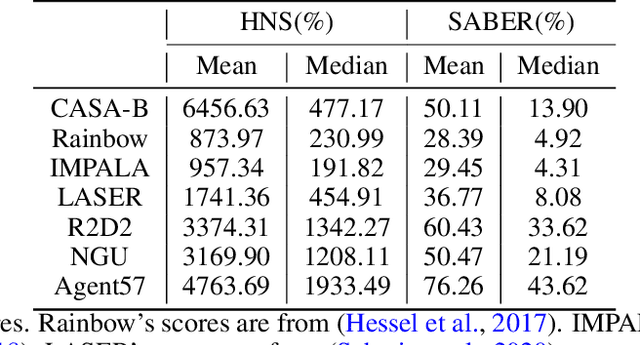
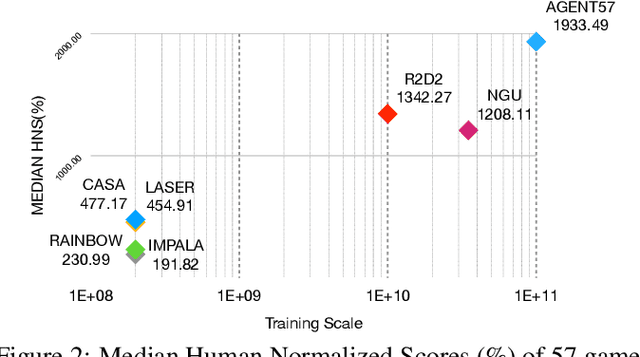

This paper introduces a novel design of model-free reinforcement learning, CASA, Critic AS an Actor. CASA follows the actor-critic framework that estimates state-value, state-action-value and policy simultaneously. We prove that CASA integrates a consistent path for the policy evaluation and the policy improvement, which completely eliminates the gradient conflict between the policy improvement and the policy evaluation. The policy evaluation is equivalent to a compensational policy improvement, which alleviates the function approximation error, and is also equivalent to an entropy-regularized policy improvement, which prevents the policy from being trapped into a suboptimal solution. Building on this design, an expectation-correct Doubly Robust Trace is introduced to learn state-value and state-action-value, and the convergence is guaranteed. Our experiments show that the design achieves State-Of-The-Art on Arcade Learning Environment.