Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Strategy Card Game via End-to-End Policy and Optimistic Smooth Fictitious Play
Mar 07, 2023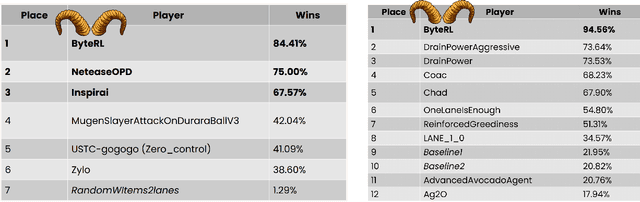
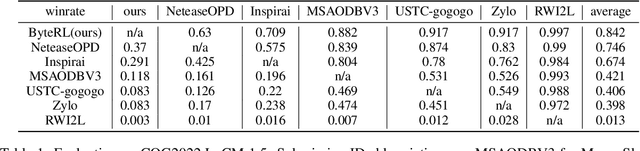

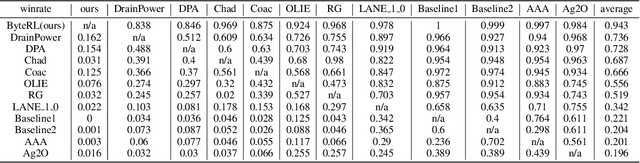
Deep Reinforcement Learning combined with Fictitious Play shows impressive results on many benchmark games, most of which are, however, single-stage. In contrast, real-world decision making problems may consist of multiple stages, where the observation spaces and the action spaces can be completely different across stages. We study a two-stage strategy card game Legends of Code and Magic and propose an end-to-end policy to address the difficulties that arise in multi-stage game. We also propose an optimistic smooth fictitious play algorithm to find the Nash Equilibrium for the two-player game. Our approach wins double championships of COG2022 competition. Extensive studies verify and show the advancement of our approach.
Via