 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Strategy Card Game (Hearthstone) with Improved Techniques
Mar 09, 2023Strategy card game is a well-known genre that is demanding on the intelligent game-play and can be an ideal test-bench for AI. Previous work combines an end-to-end policy function and an optimistic smooth fictitious play, which shows promising performances on the strategy card game Legend of Code and Magic. In this work, we apply such algorithms to Hearthstone, a famous commercial game that is more complicated in game rules and mechanisms. We further propose several improved techniques and consequently achieve significant progress. For a machine-vs-human test we invite a Hearthstone streamer whose best rank was top 10 of the official league in China region that is estimated to be of millions of players. Our models defeat the human player in all Best-of-5 tournaments of full games (including both deck building and battle), showing a strong capability of decision making.
Mastering Strategy Card Game via End-to-End Policy and Optimistic Smooth Fictitious Play
Mar 07, 2023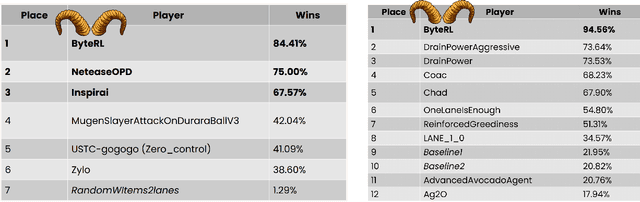
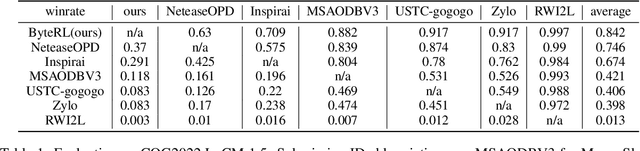

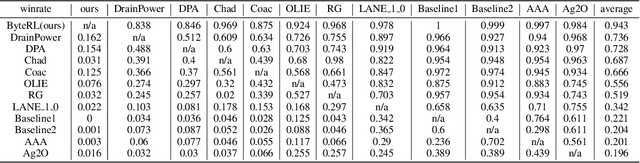
Deep Reinforcement Learning combined with Fictitious Play shows impressive results on many benchmark games, most of which are, however, single-stage. In contrast, real-world decision making problems may consist of multiple stages, where the observation spaces and the action spaces can be completely different across stages. We study a two-stage strategy card game Legends of Code and Magic and propose an end-to-end policy to address the difficulties that arise in multi-stage game. We also propose an optimistic smooth fictitious play algorithm to find the Nash Equilibrium for the two-player game. Our approach wins double championships of COG2022 competition. Extensive studies verify and show the advancement of our approach.