 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedIDM: Achieving Fast and Stable Convergence in Byzantine Federated Learning through Iterative Distribution Matching
Apr 16, 2026Most existing Byzantine-robust federated learning (FL) methods suffer from slow and unstable convergence. Moreover, when handling a substantial proportion of colluded malicious clients, achieving robustness typically entails compromising model utility. To address these issues, this work introduces FedIDM, which employs distribution matching to construct trustworthy condensed data for identifying and filtering abnormal clients. FedIDM consists of two main components: (1) attack-tolerant condensed data generation, and (2) robust aggregation with negative contribution-based rejection. These components exclude local updates that (1) deviate from the update direction derived from condensed data, or (2) cause a significant loss on the condensed dataset. Comprehensive evaluations on three benchmark datasets demonstrate that FedIDM achieves fast and stable convergence while maintaining acceptable model utility, under multiple state-of-the-art Byzantine attacks involving a large number of malicious clients.
InkDrop: Invisible Backdoor Attacks Against Dataset Condensation
Mar 30, 2026Dataset Condensation (DC) is a data-efficient learning paradigm that synthesizes small yet informative datasets, enabling models to match the performance of full-data training. However, recent work exposes a critical vulnerability of DC to backdoor attacks, where malicious patterns (\textit{e.g.}, triggers) are implanted into the condensation dataset, inducing targeted misclassification on specific inputs. Existing attacks always prioritize attack effectiveness and model utility, overlooking the crucial dimension of stealthiness. To bridge this gap, we propose InkDrop, which enhances the imperceptibility of malicious manipulation without degrading attack effectiveness and model utility. InkDrop leverages the inherent uncertainty near model decision boundaries, where minor input perturbations can induce semantic shifts, to construct a stealthy and effective backdoor attack. Specifically, InkDrop first selects candidate samples near the target decision boundary that exhibit latent semantic affinity to the target class. It then learns instance-dependent perturbations constrained by perceptual and spatial consistency, embedding targeted malicious behavior into the condensed dataset. Extensive experiments across diverse datasets validate the overall effectiveness of InkDrop, demonstrating its ability to integrate adversarial intent into condensed datasets while preserving model utility and minimizing detectability. Our code is available at https://github.com/lvdongyi/InkDrop.
SNEAKDOOR: Stealthy Backdoor Attacks against Distribution Matching-based Dataset Condensation
Mar 29, 2026Dataset condensation aims to synthesize compact yet informative datasets that retain the training efficacy of full-scale data, offering substantial gains in efficiency. Recent studies reveal that the condensation process can be vulnerable to backdoor attacks, where malicious triggers are injected into the condensation dataset, manipulating model behavior during inference. While prior approaches have made progress in balancing attack success rate and clean test accuracy, they often fall short in preserving stealthiness, especially in concealing the visual artifacts of condensed data or the perturbations introduced during inference. To address this challenge, we introduce Sneakdoor, which enhances stealthiness without compromising attack effectiveness. Sneakdoor exploits the inherent vulnerability of class decision boundaries and incorporates a generative module that constructs input-aware triggers aligned with local feature geometry, thereby minimizing detectability. This joint design enables the attack to remain imperceptible to both human inspection and statistical detection. Extensive experiments across multiple datasets demonstrate that Sneakdoor achieves a compelling balance among attack success rate, clean test accuracy, and stealthiness, substantially improving the invisibility of both the synthetic data and triggered samples while maintaining high attack efficacy. The code is available at https://github.com/XJTU-AI-Lab/SneakDoor.
VP-VAE: Rethinking Vector Quantization via Adaptive Vector Perturbation
Feb 19, 2026Vector Quantized Variational Autoencoders (VQ-VAEs) are fundamental to modern generative modeling, yet they often suffer from training instability and "codebook collapse" due to the inherent coupling of representation learning and discrete codebook optimization. In this paper, we propose VP-VAE (Vector Perturbation VAE), a novel paradigm that decouples representation learning from discretization by eliminating the need for an explicit codebook during training. Our key insight is that, from the neural network's viewpoint, performing quantization primarily manifests as injecting a structured perturbation in latent space. Accordingly, VP-VAE replaces the non-differentiable quantizer with distribution-consistent and scale-adaptive latent perturbations generated via Metropolis--Hastings sampling. This design enables stable training without a codebook while making the model robust to inference-time quantization error. Moreover, under the assumption of approximately uniform latent variables, we derive FSP (Finite Scalar Perturbation), a lightweight variant of VP-VAE that provides a unified theoretical explanation and a practical improvement for FSQ-style fixed quantizers. Extensive experiments on image and audio benchmarks demonstrate that VP-VAE and FSP improve reconstruction fidelity and achieve substantially more balanced token usage, while avoiding the instability inherent to coupled codebook training.
VeRPO: Verifiable Dense Reward Policy Optimization for Code Generation
Jan 07, 2026Effective reward design is a central challenge in Reinforcement Learning (RL) for code generation. Mainstream pass/fail outcome rewards enforce functional correctness via executing unit tests, but the resulting sparsity limits potential performance gains. While recent work has explored external Reward Models (RM) to generate richer, continuous rewards, the learned RMs suffer from reward misalignment and prohibitive computational cost. In this paper, we introduce \textbf{VeRPO} (\textbf{V}erifiable D\textbf{e}nse \textbf{R}eward \textbf{P}olicy \textbf{O}ptimization), a novel RL framework for code generation that synthesizes \textit{robust and dense rewards fully grounded in verifiable execution feedback}. The core idea of VeRPO is constructing dense rewards from weighted partial success: by dynamically estimating the difficulty weight of each unit test based on the execution statistics during training, a dense reward is derived from the sum of weights of the passed unit tests. To solidify the consistency between partial success and end-to-end functional correctness, VeRPO further integrates the dense signal with global execution outcomes, establishing a robust and dense reward paradigm relying solely on verifiable execution feedback. Extensive experiments across diverse benchmarks and settings demonstrate that VeRPO consistently outperforms outcome-driven and RM-based baselines, achieving up to +8.83\% gain in pass@1 with negligible time cost (< 0.02\%) and zero GPU memory overhead.
Efficient Reasoning via Thought-Training and Thought-Free Inference
Nov 05, 2025
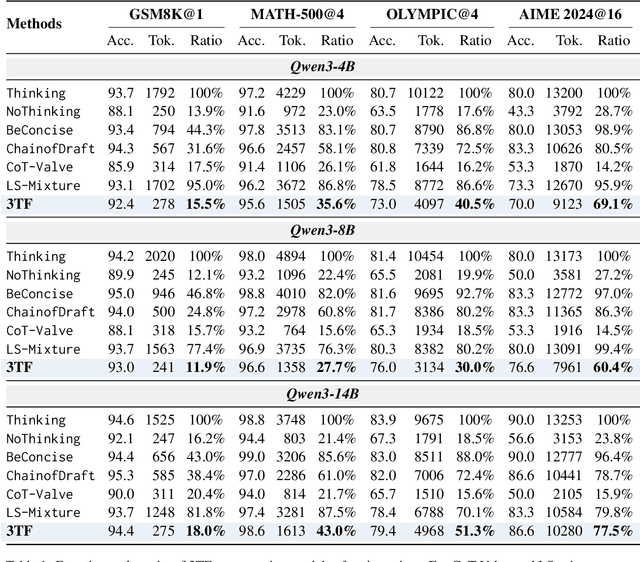
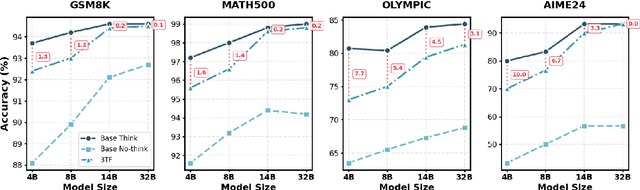
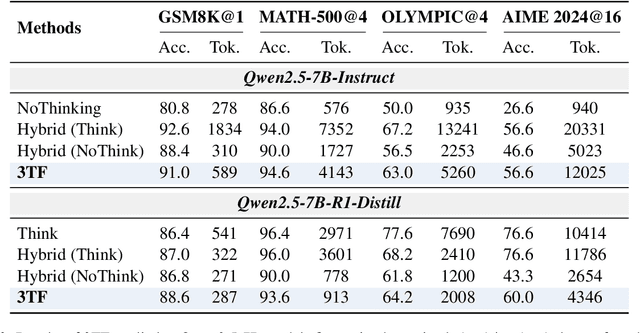
Recent advances in large language models (LLMs) have leveraged explicit Chain-of-Thought (CoT) prompting to improve reasoning accuracy. However, most existing methods primarily compress verbose reasoning outputs. These Long-to-Short transformations aim to improve efficiency, but still rely on explicit reasoning during inference. In this work, we introduce \textbf{3TF} (\textbf{T}hought-\textbf{T}raining and \textbf{T}hought-\textbf{F}ree inference), a framework for efficient reasoning that takes a Short-to-Long perspective. We first train a hybrid model that can operate in both reasoning and non-reasoning modes, and then further train it on CoT-annotated data to internalize structured reasoning, while enforcing concise, thought-free outputs at inference time using the no-reasoning mode. Unlike compression-based approaches, 3TF improves the reasoning quality of non-reasoning outputs, enabling models to perform rich internal reasoning implicitly while keeping external outputs short. Empirically, 3TF-trained models obtain large improvements on reasoning benchmarks under thought-free inference, demonstrating that high quality reasoning can be learned and executed implicitly without explicit step-by-step generation.
UniConvNet: Expanding Effective Receptive Field while Maintaining Asymptotically Gaussian Distribution for ConvNets of Any Scale
Aug 12, 2025Convolutional neural networks (ConvNets) with large effective receptive field (ERF), still in their early stages, have demonstrated promising effectiveness while constrained by high parameters and FLOPs costs and disrupted asymptotically Gaussian distribution (AGD) of ERF. This paper proposes an alternative paradigm: rather than merely employing extremely large ERF, it is more effective and efficient to expand the ERF while maintaining AGD of ERF by proper combination of smaller kernels, such as $7\times{7}$, $9\times{9}$, $11\times{11}$. This paper introduces a Three-layer Receptive Field Aggregator and designs a Layer Operator as the fundamental operator from the perspective of receptive field. The ERF can be expanded to the level of existing large-kernel ConvNets through the stack of proposed modules while maintaining AGD of ERF. Using these designs, we propose a universal model for ConvNet of any scale, termed UniConvNet. Extensive experiments on ImageNet-1K, COCO2017, and ADE20K demonstrate that UniConvNet outperforms state-of-the-art CNNs and ViTs across various vision recognition tasks for both lightweight and large-scale models with comparable throughput. Surprisingly, UniConvNet-T achieves $84.2\%$ ImageNet top-1 accuracy with $30M$ parameters and $5.1G$ FLOPs. UniConvNet-XL also shows competitive scalability to big data and large models, acquiring $88.4\%$ top-1 accuracy on ImageNet. Code and models are publicly available at https://github.com/ai-paperwithcode/UniConvNet.
One Quantizer is Enough: Toward a Lightweight Audio Codec
Apr 07, 2025Neural audio codecs have recently gained traction for their ability to compress high-fidelity audio and generate discrete tokens that can be utilized in downstream generative modeling tasks. However, leading approaches often rely on resource-intensive models and multi-quantizer architectures, resulting in considerable computational overhead and constrained real-world applicability. In this paper, we present SQCodec, a lightweight neural audio codec that leverages a single quantizer to address these limitations. SQCodec explores streamlined convolutional networks and local Transformer modules, alongside TConv, a novel mechanism designed to capture acoustic variations across multiple temporal scales, thereby enhancing reconstruction fidelity while reducing model complexity. Extensive experiments across diverse datasets show that SQCodec achieves audio quality comparable to multi-quantizer baselines, while its single-quantizer design offers enhanced adaptability and its lightweight architecture reduces resource consumption by an order of magnitude. The source code is publicly available at https://github.com/zhai-lw/SQCodec.
One Snapshot is All You Need: A Generalized Method for mmWave Signal Generation
Mar 27, 2025Wireless sensing systems, particularly those using mmWave technology, offer distinct advantages over traditional vision-based approaches, such as enhanced privacy and effectiveness in poor lighting conditions. These systems, leveraging FMCW signals, have shown success in human-centric applications like localization, gesture recognition, and so on. However, comprehensive mmWave datasets for diverse applications are scarce, often constrained by pre-processed signatures (e.g., point clouds or RA heatmaps) and inconsistent annotation formats. To overcome these limitations, we propose mmGen, a novel and generalized framework tailored for full-scene mmWave signal generation. By constructing physical signal transmission models, mmGen synthesizes human-reflected and environment-reflected mmWave signals from the constructed 3D meshes. Additionally, we incorporate methods to account for material properties, antenna gains, and multipath reflections, enhancing the realism of the synthesized signals. We conduct extensive experiments using a prototype system with commercial mmWave devices and Kinect sensors. The results show that the average similarity of Range-Angle and micro-Doppler signatures between the synthesized and real-captured signals across three different environments exceeds 0.91 and 0.89, respectively, demonstrating the effectiveness and practical applicability of mmGen.
Stereo-LiDAR Depth Estimation with Deformable Propagation and Learned Disparity-Depth Conversion
Apr 11, 2024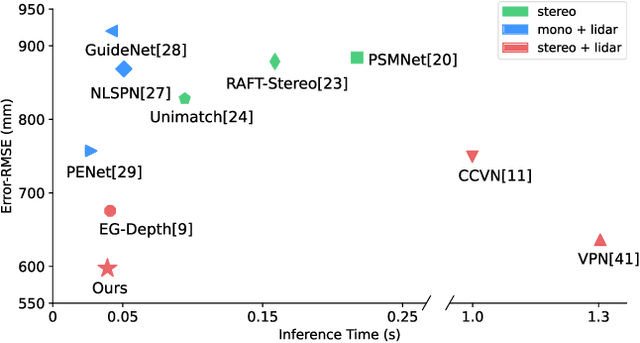
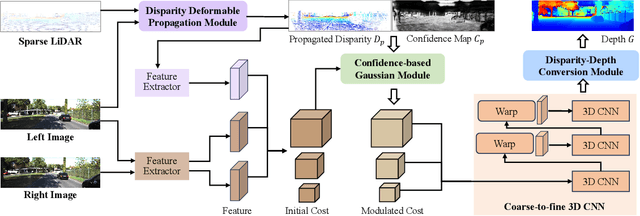
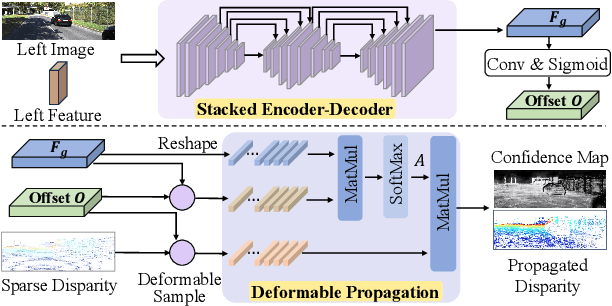
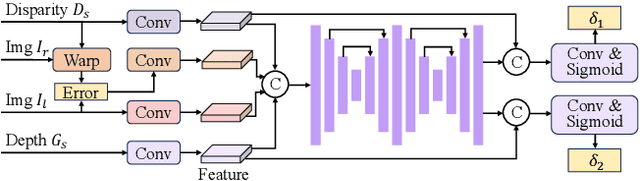
Accurate and dense depth estimation with stereo cameras and LiDAR is an important task for automatic driving and robotic perception. While sparse hints from LiDAR points have improved cost aggregation in stereo matching, their effectiveness is limited by the low density and non-uniform distribution. To address this issue, we propose a novel stereo-LiDAR depth estimation network with Semi-Dense hint Guidance, named SDG-Depth. Our network includes a deformable propagation module for generating a semi-dense hint map and a confidence map by propagating sparse hints using a learned deformable window. These maps then guide cost aggregation in stereo matching. To reduce the triangulation error in depth recovery from disparity, especially in distant regions, we introduce a disparity-depth conversion module. Our method is both accurate and efficient. The experimental results on benchmark tests show its superior performance. Our code is available at https://github.com/SJTU-ViSYS/SDG-Depth.