 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFDA: Universal Federated Domain Adaptation with Practical Assumptions
Nov 27, 2023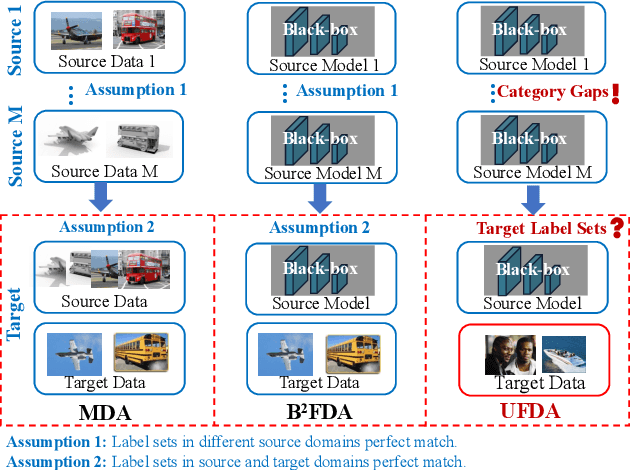
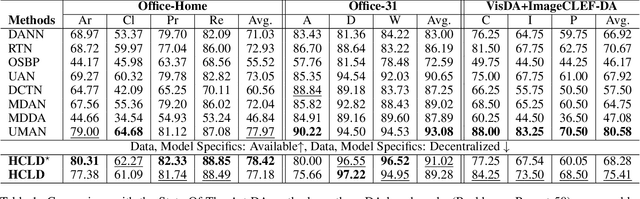
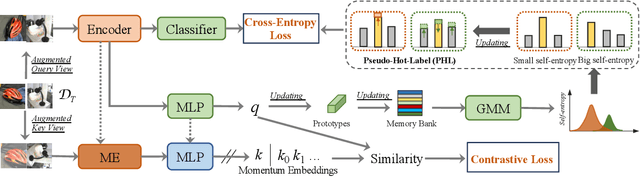
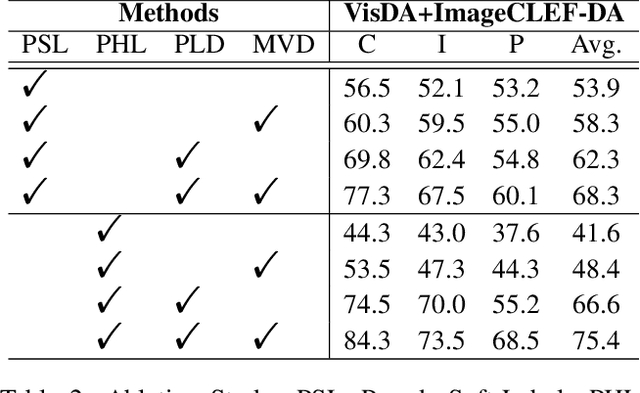
Conventional Federated Domain Adaptation (FDA) approaches usually demand an abundance of assumptions, such as label set consistency, which makes them significantly less feasible for real-world situations and introduces security hazards. In this work, we propose a more practical scenario named Universal Federated Domain Adaptation (UFDA). It only requires the black-box model and the label set information of each source domain, while the label sets of different source domains could be inconsistent and the target-domain label set is totally blind. This relaxes the assumptions made by FDA, which are often challenging to meet in real-world cases and diminish model security. To address the UFDA scenario, we propose a corresponding framework called Hot-Learning with Contrastive Label Disambiguation (HCLD), which tackles UFDA's domain shifts and category gaps problem by using one-hot outputs from the black-box models of various source domains. Moreover, to better distinguish the shared and unknown classes, we further present a cluster-level strategy named Mutual-Voting Decision (MVD) to extract robust consensus knowledge across peer classes from both source and target domains. The extensive experiments on three benchmarks demonstrate that our HCLD achieves comparable performance for our UFDA scenario with much fewer assumptions, compared to the previous methodologies with many additional assumptions.
Dual-Decoder Transformer For end-to-end Mandarin Chinese Speech Recognition with Pinyin and Character
Jan 26, 2022
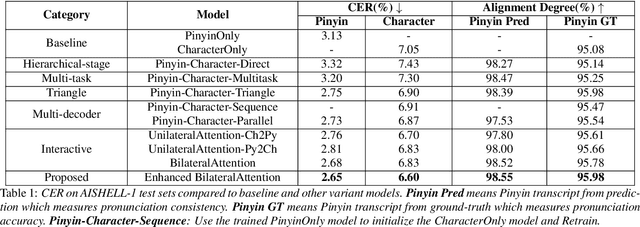
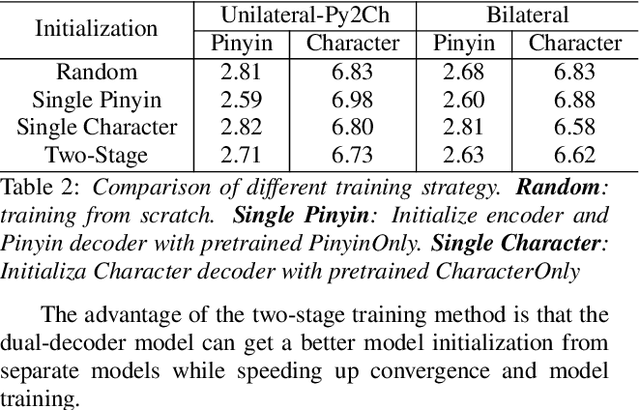
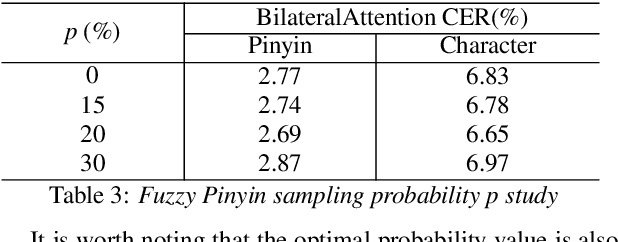
End-to-end automatic speech recognition (ASR) has achieved promising results. However, most existing end-to-end ASR methods neglect the use of specific language characteristics. For Mandarin Chinese ASR tasks, pinyin and character as writing and spelling systems respectively are mutual promotion in the Mandarin Chinese language. Based on the above intuition, we investigate types of related models that are suitable but not for joint pinyin-character ASR and propose a novel Mandarin Chinese ASR model with dual-decoder Transformer according to the characteristics of the pinyin transcripts and character transcripts. Specifically, the joint pinyin-character layer-wise linear interactive (LWLI) module and phonetic posteriorgrams adapter (PPGA) are proposed to achieve inter-layer multi-level interaction by adaptively fusing pinyin and character information. Furthermore, a two-stage training strategy is proposed to make training more stable and faster convergence. The results on the test sets of AISHELL-1 dataset show that the proposed Speech-Pinyin-Character-Interaction (SPCI) model without a language model achieves 9.85% character error rate (CER) on the test set, which is 17.71% relative reduction compared to baseline models based on Transformer.