 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnaCP: Toward Upper-Bound Continual Learning via Analytic Contrastive Projection
Nov 17, 2025



This paper studies the problem of class-incremental learning (CIL), a core setting within continual learning where a model learns a sequence of tasks, each containing a distinct set of classes. Traditional CIL methods, which do not leverage pre-trained models (PTMs), suffer from catastrophic forgetting (CF) due to the need to incrementally learn both feature representations and the classifier. The integration of PTMs into CIL has recently led to efficient approaches that treat the PTM as a fixed feature extractor combined with analytic classifiers, achieving state-of-the-art performance. However, they still face a major limitation: the inability to continually adapt feature representations to best suit the CIL tasks, leading to suboptimal performance. To address this, we propose AnaCP (Analytic Contrastive Projection), a novel method that preserves the efficiency of analytic classifiers while enabling incremental feature adaptation without gradient-based training, thereby eliminating the CF caused by gradient updates. Our experiments show that AnaCP not only outperforms existing baselines but also achieves the accuracy level of joint training, which is regarded as the upper bound of CIL.
A Theory for Length Generalization in Learning to Reason
Mar 31, 2024



Length generalization (LG) is a challenging problem in learning to reason. It refers to the phenomenon that when trained on reasoning problems of smaller lengths or sizes, the resulting model struggles with problems of larger sizes or lengths. Although LG has been studied by many researchers, the challenge remains. This paper proposes a theoretical study of LG for problems whose reasoning processes can be modeled as DAGs (directed acyclic graphs). The paper first identifies and proves the conditions under which LG can be achieved in learning to reason. It then designs problem representations based on the theory to learn to solve challenging reasoning problems like parity, addition, and multiplication, using a Transformer to achieve perfect LG.
Conditions for Length Generalization in Learning Reasoning Skills
Dec 06, 2023Reasoning is a fundamental capability of AI agents. Recently, large language models (LLMs) have shown remarkable abilities to perform reasoning tasks. However, numerous evaluations of the reasoning capabilities of LLMs have also showed some limitations. An outstanding limitation is length generalization, meaning that when trained on reasoning problems of smaller lengths or sizes, the resulting models struggle with problems of larger sizes or lengths. This potentially indicates some theoretical limitations of generalization in learning reasoning skills. These evaluations and their observations motivated us to perform a theoretical study of the length generalization problem. This work focuses on reasoning tasks that can be formulated as Markov dynamic processes (MDPs) and/or directed acyclic graphs (DAGs). It identifies and proves conditions that decide whether the length generalization problem can be solved or not for a reasoning task in a particular representation. Experiments are also conducted to verify the theoretical results.
Learnability and Algorithm for Continual Learning
Jun 22, 2023

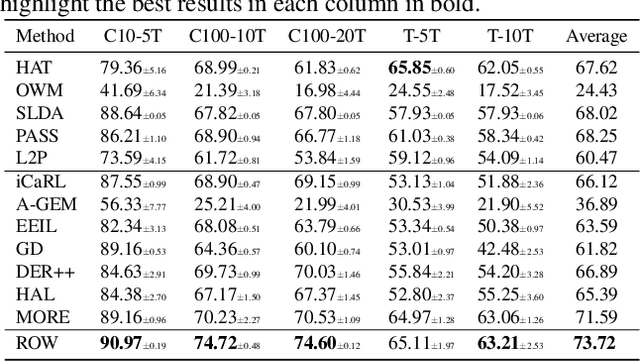

This paper studies the challenging continual learning (CL) setting of Class Incremental Learning (CIL). CIL learns a sequence of tasks consisting of disjoint sets of concepts or classes. At any time, a single model is built that can be applied to predict/classify test instances of any classes learned thus far without providing any task related information for each test instance. Although many techniques have been proposed for CIL, they are mostly empirical. It has been shown recently that a strong CIL system needs a strong within-task prediction (WP) and a strong out-of-distribution (OOD) detection for each task. However, it is still not known whether CIL is actually learnable. This paper shows that CIL is learnable. Based on the theory, a new CIL algorithm is also proposed. Experimental results demonstrate its effectiveness.
Open-World Continual Learning: Unifying Novelty Detection and Continual Learning
Apr 20, 2023



As AI agents are increasingly used in the real open world with unknowns or novelties, they need the ability to (1) recognize objects that (i) they have learned and (ii) detect items that they have not seen or learned before, and (2) learn the new items incrementally to become more and more knowledgeable and powerful. (1) is called novelty detection or out-of-distribution (OOD) detection and (2) is called class incremental learning (CIL), which is a setting of continual learning (CL). In existing research, OOD detection and CIL are regarded as two completely different problems. This paper theoretically proves that OOD detection actually is necessary for CIL. We first show that CIL can be decomposed into two sub-problems: within-task prediction (WP) and task-id prediction (TP). We then prove that TP is correlated with OOD detection. The key theoretical result is that regardless of whether WP and OOD detection (or TP) are defined explicitly or implicitly by a CIL algorithm, good WP and good OOD detection are necessary and sufficient conditions for good CIL, which unifies novelty or OOD detection and continual learning (CIL, in particular). A good CIL algorithm based on our theory can naturally be used in open world learning, which is able to perform both novelty/OOD detection and continual learning. Based on the theoretical result, new CIL methods are also designed, which outperform strong baselines in terms of CIL accuracy and its continual OOD detection by a large margin.
Mastering Strategy Card Game (Hearthstone) with Improved Techniques
Mar 09, 2023Strategy card game is a well-known genre that is demanding on the intelligent game-play and can be an ideal test-bench for AI. Previous work combines an end-to-end policy function and an optimistic smooth fictitious play, which shows promising performances on the strategy card game Legend of Code and Magic. In this work, we apply such algorithms to Hearthstone, a famous commercial game that is more complicated in game rules and mechanisms. We further propose several improved techniques and consequently achieve significant progress. For a machine-vs-human test we invite a Hearthstone streamer whose best rank was top 10 of the official league in China region that is estimated to be of millions of players. Our models defeat the human player in all Best-of-5 tournaments of full games (including both deck building and battle), showing a strong capability of decision making.
Mastering Strategy Card Game via End-to-End Policy and Optimistic Smooth Fictitious Play
Mar 07, 2023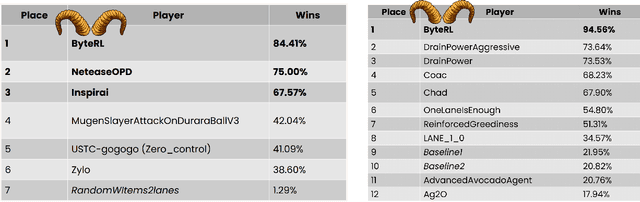
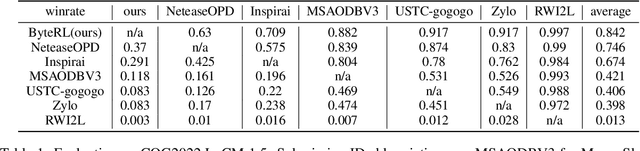

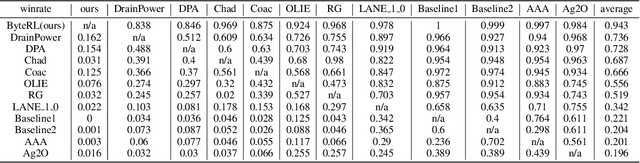
Deep Reinforcement Learning combined with Fictitious Play shows impressive results on many benchmark games, most of which are, however, single-stage. In contrast, real-world decision making problems may consist of multiple stages, where the observation spaces and the action spaces can be completely different across stages. We study a two-stage strategy card game Legends of Code and Magic and propose an end-to-end policy to address the difficulties that arise in multi-stage game. We also propose an optimistic smooth fictitious play algorithm to find the Nash Equilibrium for the two-player game. Our approach wins double championships of COG2022 competition. Extensive studies verify and show the advancement of our approach.
A Theoretical Study on Solving Continual Learning
Nov 04, 2022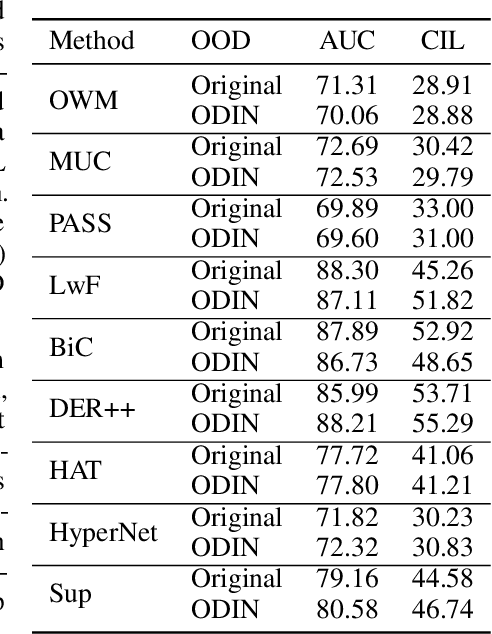
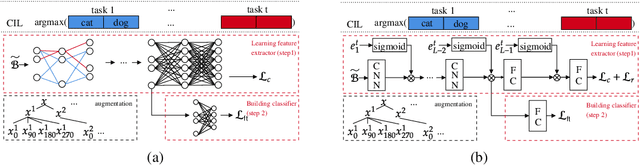

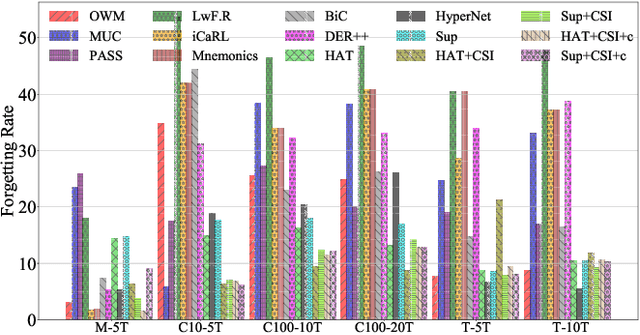
Continual learning (CL) learns a sequence of tasks incrementally. There are two popular CL settings, class incremental learning (CIL) and task incremental learning (TIL). A major challenge of CL is catastrophic forgetting (CF). While a number of techniques are already available to effectively overcome CF for TIL, CIL remains to be highly challenging. So far, little theoretical study has been done to provide a principled guidance on how to solve the CIL problem. This paper performs such a study. It first shows that probabilistically, the CIL problem can be decomposed into two sub-problems: Within-task Prediction (WP) and Task-id Prediction (TP). It further proves that TP is correlated with out-of-distribution (OOD) detection, which connects CIL and OOD detection. The key conclusion of this study is that regardless of whether WP and TP or OOD detection are defined explicitly or implicitly by a CIL algorithm, good WP and good TP or OOD detection are necessary and sufficient for good CIL performances. Additionally, TIL is simply WP. Based on the theoretical result, new CIL methods are also designed, which outperform strong baselines in both CIL and TIL settings by a large margin.
Generalized Data Distribution Iteration
Jun 20, 2022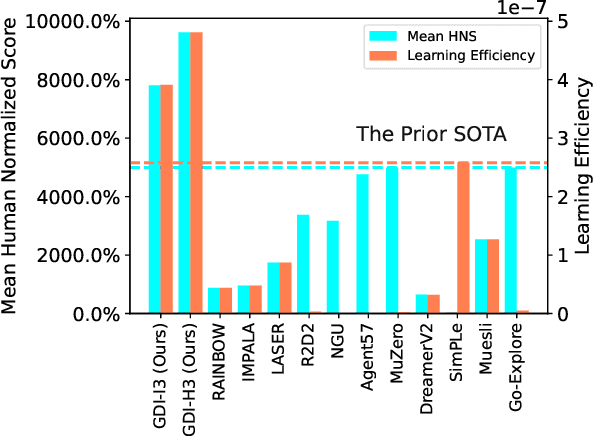
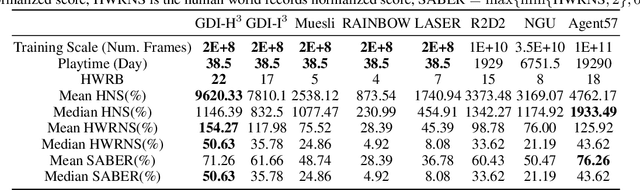
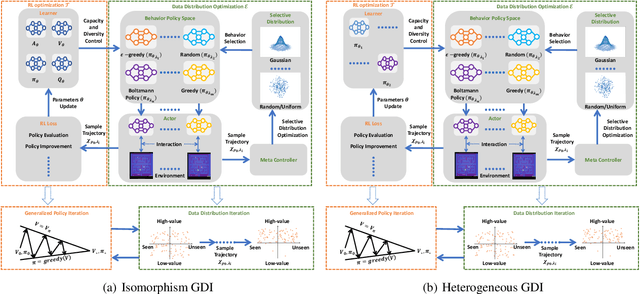
To obtain higher sample efficiency and superior final performance simultaneously has been one of the major challenges for deep reinforcement learning (DRL). Previous work could handle one of these challenges but typically failed to address them concurrently. In this paper, we try to tackle these two challenges simultaneously. To achieve this, we firstly decouple these challenges into two classic RL problems: data richness and exploration-exploitation trade-off. Then, we cast these two problems into the training data distribution optimization problem, namely to obtain desired training data within limited interactions, and address them concurrently via i) explicit modeling and control of the capacity and diversity of behavior policy and ii) more fine-grained and adaptive control of selective/sampling distribution of the behavior policy using a monotonic data distribution optimization. Finally, we integrate this process into Generalized Policy Iteration (GPI) and obtain a more general framework called Generalized Data Distribution Iteration (GDI). We use the GDI framework to introduce operator-based versions of well-known RL methods from DQN to Agent57. Theoretical guarantee of the superiority of GDI compared with GPI is concluded. We also demonstrate our state-of-the-art (SOTA) performance on Arcade Learning Environment (ALE), wherein our algorithm has achieved 9620.33% mean human normalized score (HNS), 1146.39% median HNS and surpassed 22 human world records using only 200M training frames. Our performance is comparable to Agent57's while we consume 500 times less data. We argue that there is still a long way to go before obtaining real superhuman agents in ALE.
Continual Learning Based on OOD Detection and Task Masking
Mar 17, 2022
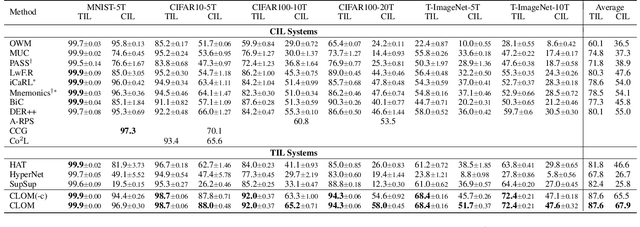
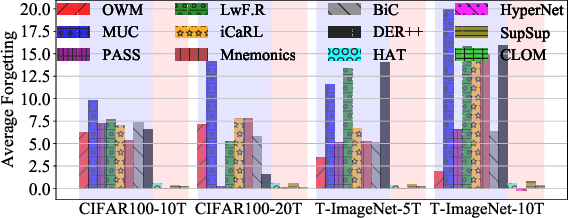
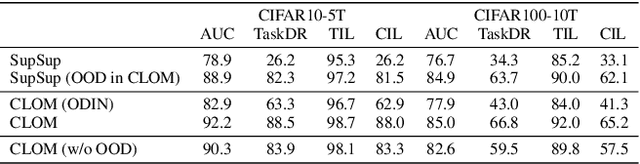
Existing continual learning techniques focus on either task incremental learning (TIL) or class incremental learning (CIL) problem, but not both. CIL and TIL differ mainly in that the task-id is provided for each test sample during testing for TIL, but not provided for CIL. Continual learning methods intended for one problem have limitations on the other problem. This paper proposes a novel unified approach based on out-of-distribution (OOD) detection and task masking, called CLOM, to solve both problems. The key novelty is that each task is trained as an OOD detection model rather than a traditional supervised learning model, and a task mask is trained to protect each task to prevent forgetting. Our evaluation shows that CLOM outperforms existing state-of-the-art baselines by large margins. The average TIL/CIL accuracy of CLOM over six experiments is 87.6/67.9% while that of the best baselines is only 82.4/55.0%.