 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-set Recognition via Augmentation-based Similarity Learning
Mar 24, 2022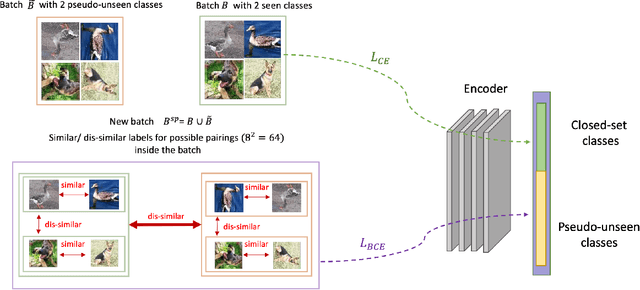
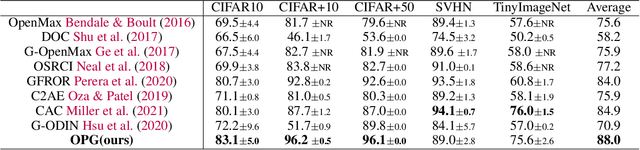
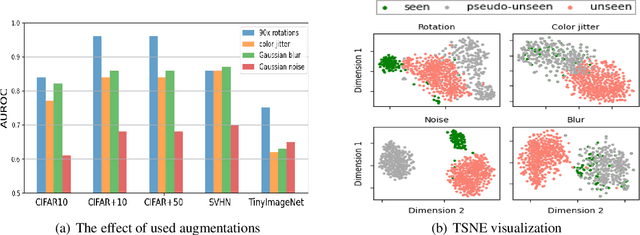
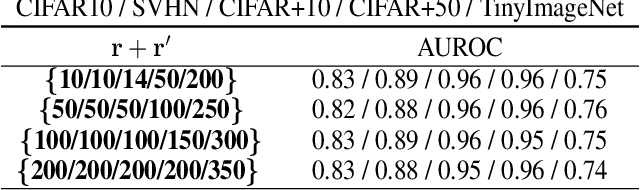
The primary assumption of conventional supervised learning or classification is that the test samples are drawn from the same distribution as the training samples, which is called closed set learning or classification. In many practical scenarios, this is not the case because there are unknowns or unseen class samples in the test data, which is called the open set scenario, and the unknowns need to be detected. This problem is referred to as the open set recognition problem and is important in safety-critical applications. We propose to detect unknowns (or unseen class samples) through learning pairwise similarities. The proposed method works in two steps. It first learns a closed set classifier using the seen classes that have appeared in training and then learns how to compare seen classes with pseudo-unseen (automatically generated unseen class samples). The pseudo-unseen generation is carried out by performing distribution shifting augmentations on the seen or training samples. We call our method OPG (Open set recognition based on Pseudo unseen data Generation). The experimental evaluation shows that the learned similarity-based features can successfully distinguish seen from unseen in benchmark datasets for open set recognition.
Continual Learning Based on OOD Detection and Task Masking
Mar 17, 2022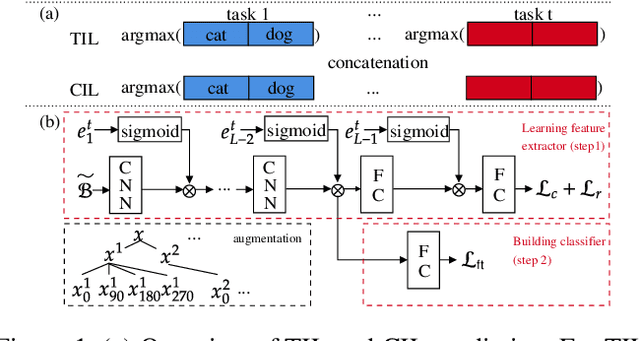
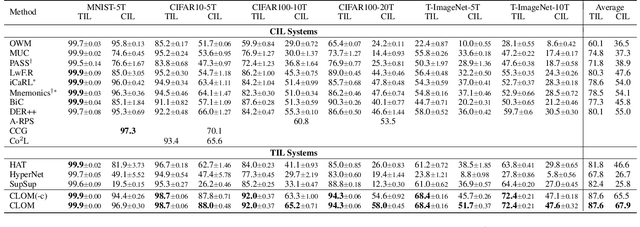
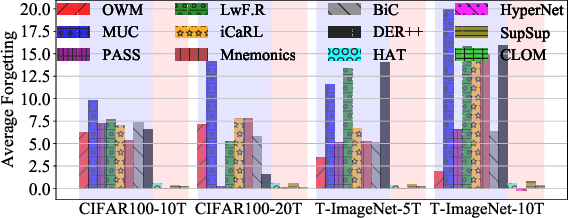
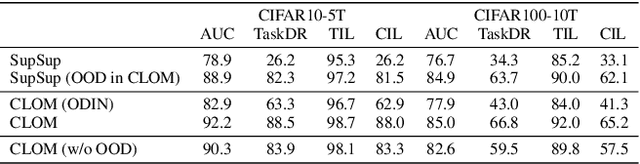
Existing continual learning techniques focus on either task incremental learning (TIL) or class incremental learning (CIL) problem, but not both. CIL and TIL differ mainly in that the task-id is provided for each test sample during testing for TIL, but not provided for CIL. Continual learning methods intended for one problem have limitations on the other problem. This paper proposes a novel unified approach based on out-of-distribution (OOD) detection and task masking, called CLOM, to solve both problems. The key novelty is that each task is trained as an OOD detection model rather than a traditional supervised learning model, and a task mask is trained to protect each task to prevent forgetting. Our evaluation shows that CLOM outperforms existing state-of-the-art baselines by large margins. The average TIL/CIL accuracy of CLOM over six experiments is 87.6/67.9% while that of the best baselines is only 82.4/55.0%.
Zero-Shot Open Set Detection by Extending CLIP
Sep 10, 2021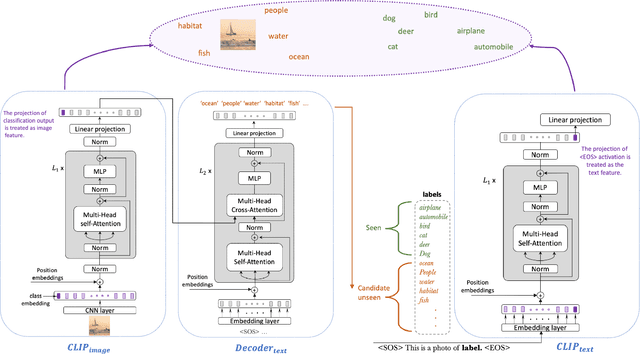
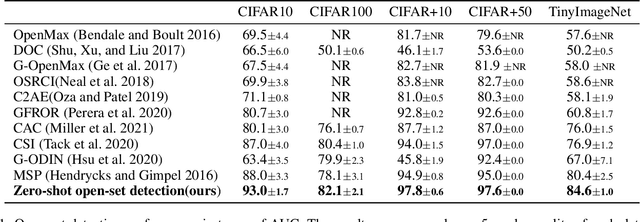
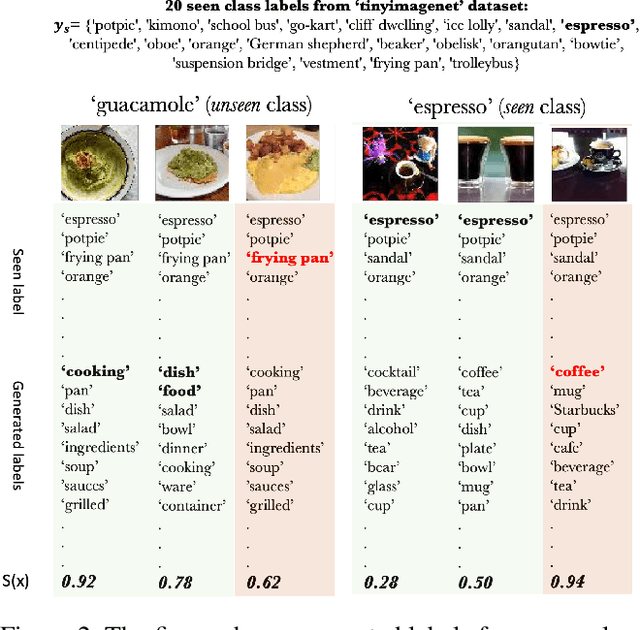
In a regular open set detection problem, samples of known classes (also called closed set classes) are used to train a special classifier. In testing, the classifier can (1) classify the test samples of known classes to their respective classes and (2) also detect samples that do not belong to any of the known classes (we say they belong to some unknown or open set classes). This paper studies the problem of zero-shot open-set detection, which still performs the same two tasks in testing but has no training except using the given known class names. This paper proposes a novel and yet simple method (called ZO-CLIP) to solve the problem. ZO-CLIP builds on top of the recent advances in zero-shot classification through multi-modal representation learning. It first extends the pre-trained multi-modal model CLIP by training a text-based image description generator on top of CLIP. In testing, it uses the extended model to generate some candidate unknown class names for each test sample and computes a confidence score based on both the known class names and candidate unknown class names for zero-shot open set detection. Experimental results on 5 benchmark datasets for open set detection confirm that ZO-CLIP outperforms the baselines by a large margin.
Building an Application Independent Natural Language Interface
Oct 30, 2019
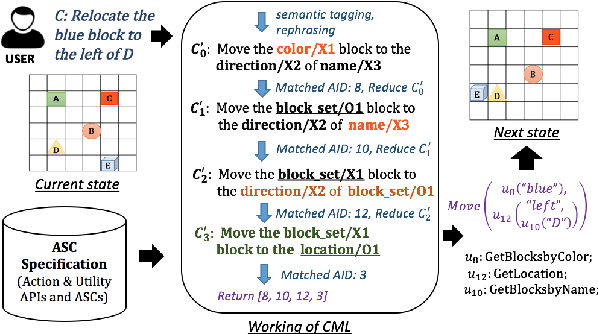


Traditional approaches to building natural language (NL) interfaces typically use a semantic parser to parse the user command and convert it to a logical form, which is then translated to an executable action in an application. However, it is still challenging for a semantic parser to correctly parse natural language. For a different domain, the parser may need to be retrained or tuned, and a new translator also needs to be written to convert the logical forms to executable actions. In this work, we propose a novel and application independent approach to building NL interfaces that does not need a semantic parser or a translator. It is based on natural language to natural language matching and learning, where the representation of each action and each user command are both in natural language. To perform a user intended action, the system only needs to match the user command with the correct action representation, and then execute the corresponding action. The system also interactively learns new (paraphrased) commands for actions to expand the action representations over time. Our experimental results show the effectiveness of the proposed approach.