 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Data Distribution Iteration
Paper and Code
Jun 20, 2022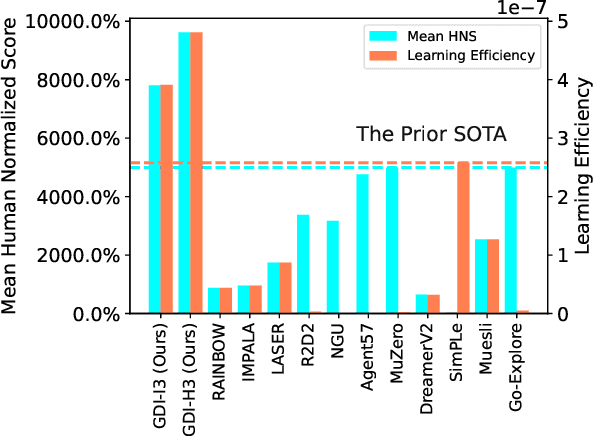
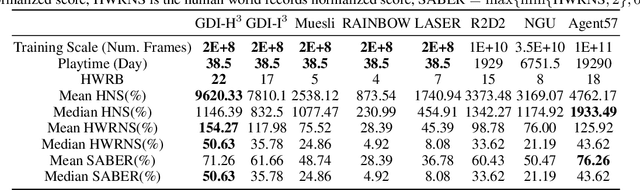
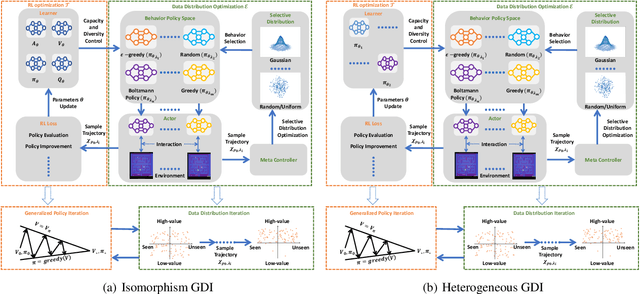
To obtain higher sample efficiency and superior final performance simultaneously has been one of the major challenges for deep reinforcement learning (DRL). Previous work could handle one of these challenges but typically failed to address them concurrently. In this paper, we try to tackle these two challenges simultaneously. To achieve this, we firstly decouple these challenges into two classic RL problems: data richness and exploration-exploitation trade-off. Then, we cast these two problems into the training data distribution optimization problem, namely to obtain desired training data within limited interactions, and address them concurrently via i) explicit modeling and control of the capacity and diversity of behavior policy and ii) more fine-grained and adaptive control of selective/sampling distribution of the behavior policy using a monotonic data distribution optimization. Finally, we integrate this process into Generalized Policy Iteration (GPI) and obtain a more general framework called Generalized Data Distribution Iteration (GDI). We use the GDI framework to introduce operator-based versions of well-known RL methods from DQN to Agent57. Theoretical guarantee of the superiority of GDI compared with GPI is concluded. We also demonstrate our state-of-the-art (SOTA) performance on Arcade Learning Environment (ALE), wherein our algorithm has achieved 9620.33% mean human normalized score (HNS), 1146.39% median HNS and surpassed 22 human world records using only 200M training frames. Our performance is comparable to Agent57's while we consume 500 times less data. We argue that there is still a long way to go before obtaining real superhuman agents in ALE.