 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2E-Fly: An Integrated Training-to-Deployment System for End-to-End Quadrotor Autonomy
Apr 14, 2026Training and transferring learning-based policies for quadrotors from simulation to reality remains challenging due to inefficient visual rendering, physical modeling inaccuracies, unmodeled sensor discrepancies, and the absence of a unified platform integrating differentiable physics learning into end-to-end training. While recent work has demonstrated various end-to-end quadrotor control tasks, few systems provide a systematic, zero-shot transfer pipeline, hindering reproducibility and real-world deployment. To bridge this gap, we introduce E2E-Fly, an integrated framework featuring an agile quadrotor platform coupled with a full-stack training, validation, and deployment workflow. The training framework incorporates a high-performance simulator with support for differentiable physics learning and reinforcement learning, alongside structured reward design tailored to common quadrotor tasks. We further introduce a two-stage validation strategy using sim-to-sim transfer and hardware-in-the-loop testing, and deploy policies onto two physical quadrotor platforms via a dedicated low-level control interface and a comprehensive sim-to-real alignment methodology, encompassing system identification, domain randomization, latency compensation, and noise modeling. To the best of our knowledge, this is the first work to systematically unify differentiable physical learning with training, validation, and real-world deployment for quadrotors. Finally, we demonstrate the effectiveness of our framework for training six end-to-end control tasks and deploy them in the real world.
Simple but Stable, Fast and Safe: Achieve End-to-end Control by High-Fidelity Differentiable Simulation
Apr 12, 2026Obstacle avoidance is a fundamental vision-based task essential for enabling quadrotors to perform advanced applications. When planning the trajectory, existing approaches both on optimization and learning typically regard quadrotor as a point-mass model, giving path or velocity commands then tracking the commands by outer-loop controller. However, at high speeds, planned trajectories sometimes become dynamically infeasible in actual flight, which beyond the capacity of controller. In this paper, we propose a novel end-to-end policy that directly maps depth images to low-level bodyrate commands by reinforcement learning via differentiable simulation. The high-fidelity simulation in training after parameter identification significantly reduces all the gaps between training, simulation and real world. Analytical process by differentiable simulation provides accurate gradient to ensure efficiently training the low-level policy without expert guidance. The policy employs a lightweight and the most simple inference pipeline that runs without explicit mapping, backbone networks, primitives, recurrent structures, or backend controllers, nor curriculum or privileged guidance. By inferring low-level command directly to the hardware controller, the method enables full flight envelope control and avoids the dynamic-infeasible issue.Experimental results demonstrate that the proposed approach achieves the highest success rate and the lowest jerk among state-of-the-art baselines across multiple benchmarks. The policy also exhibits strong generalization, successfully deploying zero-shot in unseen, outdoor environments while reaching speeds of up to 7.5m/s as well as stably flying in the super-dense forest.
Vision-Based End-to-End Learning for UAV Traversal of Irregular Gaps via Differentiable Simulation
Apr 03, 2026-Navigation through narrow and irregular gaps is an essential skill in autonomous drones for applications such as inspection, search-and-rescue, and disaster response. However, traditional planning and control methods rely on explicit gap extraction and measurement, while recent end-to-end approaches often assume regularly shaped gaps, leading to poor generalization and limited practicality. In this work, we present a fully vision-based, end-to-end framework that maps depth images directly to control commands, enabling drones to traverse complex gaps within unseen environments. Operating in the Special Euclidean group SE(3), where position and orientation are tightly coupled, the framework leverages differentiable simulation, a Stop-Gradient operator, and a Bimodal Initialization Distribution to achieve stable traversal through consecutive gaps. Two auxiliary prediction modules-a gap-crossing success classifier and a traversability predictor-further enhance continuous navigation and safety. Extensive simulation and real-world experiments demonstrate the approach's effectiveness, generalization capability, and practical robustness.
VisFly-Lab: Unified Differentiable Framework for First-Order Reinforcement Learning of Quadrotor Control
Mar 22, 2026First-order reinforcement learning with differentiable simulation is promising for quadrotor control, but practical progress remains fragmented across task-specific settings. To support more systematic development and evaluation, we present a unified differentiable framework for multi-task quadrotor control. The framework is wrapped, extensible, and equipped with deployment-oriented dynamics, providing a common interface across four representative tasks: hovering, tracking, landing, and racing. We also present the suite of first-order learning algorithms, where we identify two practical bottlenecks of standard first-order training: limited state coverage caused by horizon initialization and gradient bias caused by partially non-differentiable rewards. To address these issues, we propose Amended Backpropagation Through Time (ABPT), which combines differentiable rollout optimization, a value-based auxiliary objective, and visited-state initialization to improve training robustness. Experimental results show that ABPT yields the clearest gains in tasks with partially non-differentiable rewards, while remaining competitive in fully differentiable settings. We further provide proof-of-concept real-world deployments showing initial transferability of policies learned in the proposed framework beyond simulation.
Curriculum Reinforcement Learning for Quadrotor Racing with Random Obstacles
Feb 27, 2026Autonomous drone racing has attracted increasing interest as a research topic for exploring the limits of agile flight. However, existing studies primarily focus on obstacle-free racetracks, while the perception and dynamic challenges introduced by obstacles remain underexplored, often resulting in low success rates and limited robustness in real-world flight. To this end, we propose a novel vision-based curriculum reinforcement learning framework for training a robust controller capable of addressing unseen obstacles in drone racing. We combine multi-stage cu rriculum learning, domain randomization, and a multi-scene updating strategy to address the conflicting challenges of obstacle avoidance and gate traversal. Our end-to-end control policy is implemented as a single network, allowing high-speed flight of quadrotors in environments with variable obstacles. Both hardware-in-the-loop and real-world experiments demonstrate that our method achieves faster lap times and higher success rates than existing approaches, effectively advancing drone racing in obstacle-rich environments. The video and code are available at: https://github.com/SJTU-ViSYS-team/CRL-Drone-Racing.
CoordAR: One-Reference 6D Pose Estimation of Novel Objects via Autoregressive Coordinate Map Generation
Nov 17, 2025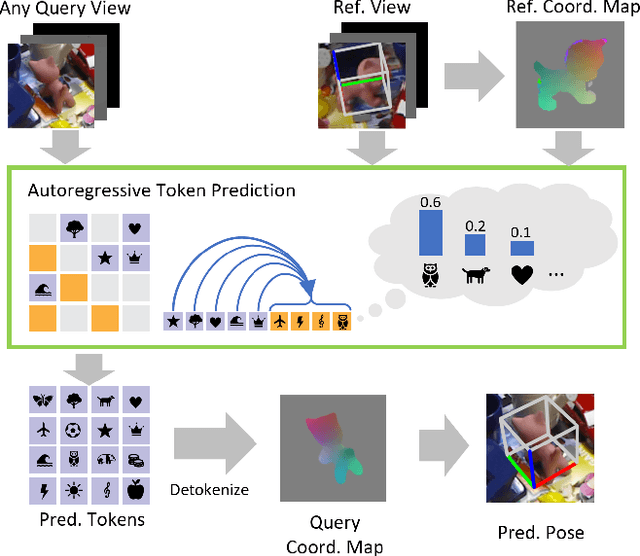
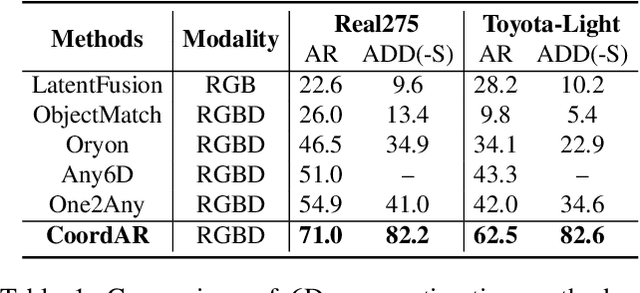
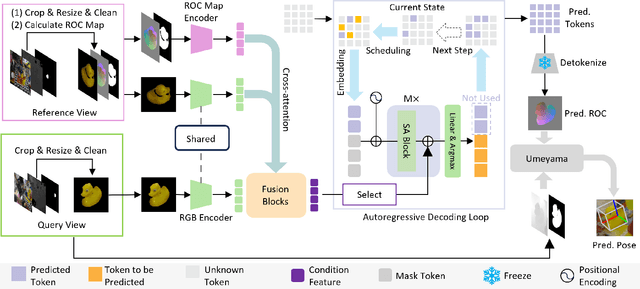
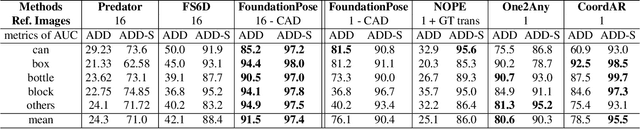
Object 6D pose estimation, a crucial task for robotics and augmented reality applications, becomes particularly challenging when dealing with novel objects whose 3D models are not readily available. To reduce dependency on 3D models, recent studies have explored one-reference-based pose estimation, which requires only a single reference view instead of a complete 3D model. However, existing methods that rely on real-valued coordinate regression suffer from limited global consistency due to the local nature of convolutional architectures and face challenges in symmetric or occluded scenarios owing to a lack of uncertainty modeling. We present CoordAR, a novel autoregressive framework for one-reference 6D pose estimation of unseen objects. CoordAR formulates 3D-3D correspondences between the reference and query views as a map of discrete tokens, which is obtained in an autoregressive and probabilistic manner. To enable accurate correspondence regression, CoordAR introduces 1) a novel coordinate map tokenization that enables probabilistic prediction over discretized 3D space; 2) a modality-decoupled encoding strategy that separately encodes RGB appearance and coordinate cues; and 3) an autoregressive transformer decoder conditioned on both position-aligned query features and the partially generated token sequence. With these novel mechanisms, CoordAR significantly outperforms existing methods on multiple benchmarks and demonstrates strong robustness to symmetry, occlusion, and other challenges in real-world tests.
StableTracker: Learning to Stably Track Target via Differentiable Simulation
Sep 17, 2025FPV object tracking methods heavily rely on handcraft modular designs, resulting in hardware overload and cumulative error, which seriously degrades the tracking performance, especially for rapidly accelerating or decelerating targets. To address these challenges, we present \textbf{StableTracker}, a learning-based control policy that enables quadrotors to robustly follow the moving target from arbitrary perspectives. The policy is trained using backpropagation-through-time via differentiable simulation, allowing the quadrotor to maintain the target at the center of the visual field in both horizontal and vertical directions, while keeping a fixed relative distance, thereby functioning as an autonomous aerial camera. We compare StableTracker against both state-of-the-art traditional algorithms and learning baselines. Simulation experiments demonstrate that our policy achieves superior accuracy, stability and generalization across varying safe distances, trajectories, and target velocities. Furthermore, a real-world experiment on a quadrotor with an onboard computer validated practicality of the proposed approach.
Collaborative Learning for Unsupervised Multimodal Remote Sensing Image Registration: Integrating Self-Supervision and MIM-Guided Diffusion-Based Image Translation
May 28, 2025The substantial modality-induced variations in radiometric, texture, and structural characteristics pose significant challenges for the accurate registration of multimodal images. While supervised deep learning methods have demonstrated strong performance, they often rely on large-scale annotated datasets, limiting their practical application. Traditional unsupervised methods usually optimize registration by minimizing differences in feature representations, yet often fail to robustly capture geometric discrepancies, particularly under substantial spatial and radiometric variations, thus hindering convergence stability. To address these challenges, we propose a Collaborative Learning framework for Unsupervised Multimodal Image Registration, named CoLReg, which reformulates unsupervised registration learning into a collaborative training paradigm comprising three components: (1) a cross-modal image translation network, MIMGCD, which employs a learnable Maximum Index Map (MIM) guided conditional diffusion model to synthesize modality-consistent image pairs; (2) a self-supervised intermediate registration network which learns to estimate geometric transformations using accurate displacement labels derived from MIMGCD outputs; (3) a distilled cross-modal registration network trained with pseudo-label predicted by the intermediate network. The three networks are jointly optimized through an alternating training strategy wherein each network enhances the performance of the others. This mutual collaboration progressively reduces modality discrepancies, enhances the quality of pseudo-labels, and improves registration accuracy. Extensive experimental results on multiple datasets demonstrate that our ColReg achieves competitive or superior performance compared to state-of-the-art unsupervised approaches and even surpasses several supervised baselines.
OSDM-MReg: Multimodal Image Registration based One Step Diffusion Model
Apr 08, 2025Multimodal remote sensing image registration aligns images from different sensors for data fusion and analysis. However, current methods often fail to extract modality-invariant features when aligning image pairs with large nonlinear radiometric differences. To address this issues, we propose OSDM-MReg, a novel multimodal image registration framework based image-to-image translation to eliminate the gap of multimodal images. Firstly, we propose a novel one-step unaligned target-guided conditional denoising diffusion probabilistic models(UTGOS-CDDPM)to translate multimodal images into a unified domain. In the inference stage, traditional conditional DDPM generate translated source image by a large number of iterations, which severely slows down the image registration task. To address this issues, we use the unaligned traget image as a condition to promote the generation of low-frequency features of the translated source image. Furthermore, during the training stage, we add the inverse process of directly predicting the translated image to ensure that the translated source image can be generated in one step during the testing stage. Additionally, to supervised the detail features of translated source image, we propose a new perceptual loss that focuses on the high-frequency feature differences between the translated and ground-truth images. Finally, a multimodal multiscale image registration network (MM-Reg) fuse the multimodal feature of the unimodal images and multimodal images by proposed multimodal feature fusion strategy. Experiments demonstrate superior accuracy and efficiency across various multimodal registration tasks, particularly for SAR-optical image pairs.
mmDEAR: mmWave Point Cloud Density Enhancement for Accurate Human Body Reconstruction
Mar 04, 2025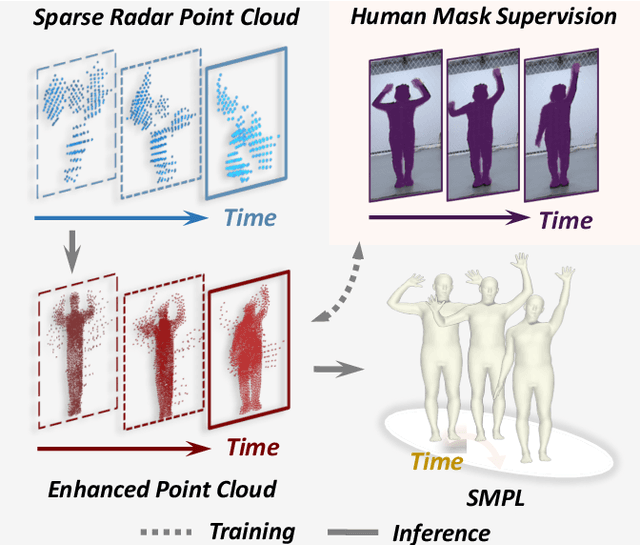

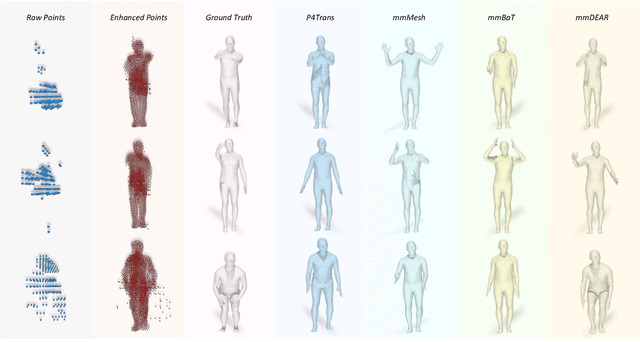
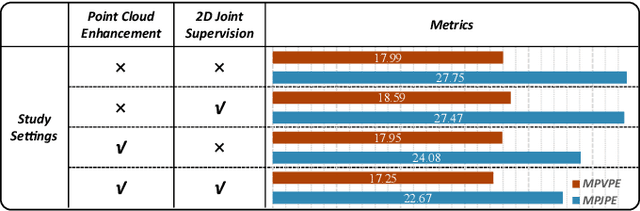
Millimeter-wave (mmWave) radar offers robust sensing capabilities in diverse environments, making it a highly promising solution for human body reconstruction due to its privacy-friendly and non-intrusive nature. However, the significant sparsity of mmWave point clouds limits the estimation accuracy. To overcome this challenge, we propose a two-stage deep learning framework that enhances mmWave point clouds and improves human body reconstruction accuracy. Our method includes a mmWave point cloud enhancement module that densifies the raw data by leveraging temporal features and a multi-stage completion network, followed by a 2D-3D fusion module that extracts both 2D and 3D motion features to refine SMPL parameters. The mmWave point cloud enhancement module learns the detailed shape and posture information from 2D human masks in single-view images. However, image-based supervision is involved only during the training phase, and the inference relies solely on sparse point clouds to maintain privacy. Experiments on multiple datasets demonstrate that our approach outperforms state-of-the-art methods, with the enhanced point clouds further improving performance when integrated into existing models.