 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate-Distortion Optimized Communication for Collaborative Perception
Sep 26, 2025



Collaborative perception emphasizes enhancing environmental understanding by enabling multiple agents to share visual information with limited bandwidth resources. While prior work has explored the empirical trade-off between task performance and communication volume, a significant gap remains in the theoretical foundation. To fill this gap, we draw on information theory and introduce a pragmatic rate-distortion theory for multi-agent collaboration, specifically formulated to analyze performance-communication trade-off in goal-oriented multi-agent systems. This theory concretizes two key conditions for designing optimal communication strategies: supplying pragmatically relevant information and transmitting redundancy-less messages. Guided by these two conditions, we propose RDcomm, a communication-efficient collaborative perception framework that introduces two key innovations: i) task entropy discrete coding, which assigns features with task-relevant codeword-lengths to maximize the efficiency in supplying pragmatic information; ii) mutual-information-driven message selection, which utilizes mutual information neural estimation to approach the optimal redundancy-less condition. Experiments on 3D object detection and BEV segmentation demonstrate that RDcomm achieves state-of-the-art accuracy on DAIR-V2X and OPV2V, while reducing communication volume by up to 108 times. The code will be released.
ThermoStereoRT: Thermal Stereo Matching in Real Time via Knowledge Distillation and Attention-based Refinement
Apr 10, 2025We introduce ThermoStereoRT, a real-time thermal stereo matching method designed for all-weather conditions that recovers disparity from two rectified thermal stereo images, envisioning applications such as night-time drone surveillance or under-bed cleaning robots. Leveraging a lightweight yet powerful backbone, ThermoStereoRT constructs a 3D cost volume from thermal images and employs multi-scale attention mechanisms to produce an initial disparity map. To refine this map, we design a novel channel and spatial attention module. Addressing the challenge of sparse ground truth data in thermal imagery, we utilize knowledge distillation to boost performance without increasing computational demands. Comprehensive evaluations on multiple datasets demonstrate that ThermoStereoRT delivers both real-time capacity and robust accuracy, making it a promising solution for real-world deployment in various challenging environments. Our code will be released on https://github.com/SJTU-ViSYS-team/ThermoStereoRT
* 7 pages, 6 figures, 4 tables. Accepted to IEEE ICRA 2025. This is the preprint version
RoCo-Sim: Enhancing Roadside Collaborative Perception through Foreground Simulation
Mar 13, 2025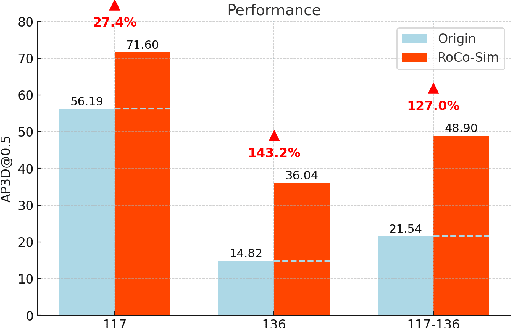
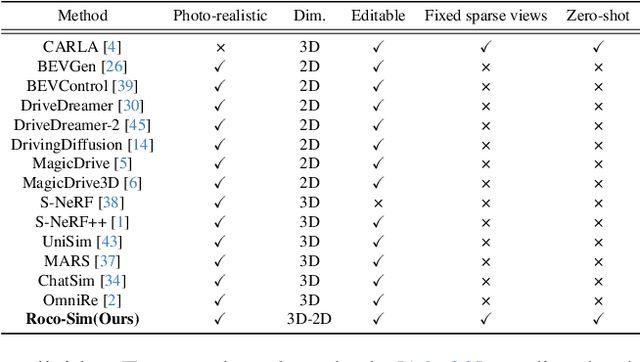


Roadside Collaborative Perception refers to a system where multiple roadside units collaborate to pool their perceptual data, assisting vehicles in enhancing their environmental awareness. Existing roadside perception methods concentrate on model design but overlook data issues like calibration errors, sparse information, and multi-view consistency, leading to poor performance on recent published datasets. To significantly enhance roadside collaborative perception and address critical data issues, we present the first simulation framework RoCo-Sim for road-side collaborative perception. RoCo-Sim is capable of generating diverse, multi-view consistent simulated roadside data through dynamic foreground editing and full-scene style transfer of a single image. RoCo-Sim consists of four components: (1) Camera Extrinsic Optimization ensures accurate 3D to 2D projection for roadside cameras; (2) A novel Multi-View Occlusion-Aware Sampler (MOAS) determines the placement of diverse digital assets within 3D space; (3) DepthSAM innovatively models foreground-background relationships from single-frame fixed-view images, ensuring multi-view consistency of foreground; and (4) Scalable Post-Processing Toolkit generates more realistic and enriched scenes through style transfer and other enhancements. RoCo-Sim significantly improves roadside 3D object detection, outperforming SOTA methods by 83.74 on Rcooper-Intersection and 83.12 on TUMTraf-V2X for AP70. RoCo-Sim fills a critical gap in roadside perception simulation. Code and pre-trained models will be released soon: https://github.com/duyuwen-duen/RoCo-Sim
Stereo-LiDAR Depth Estimation with Deformable Propagation and Learned Disparity-Depth Conversion
Apr 11, 2024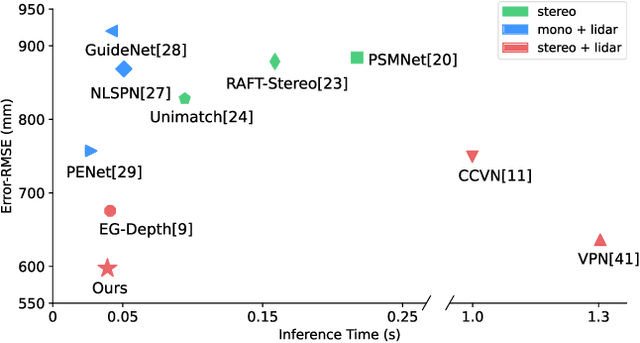
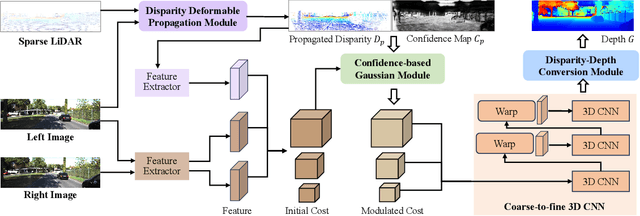
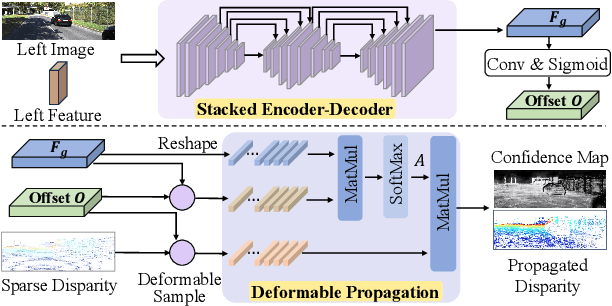
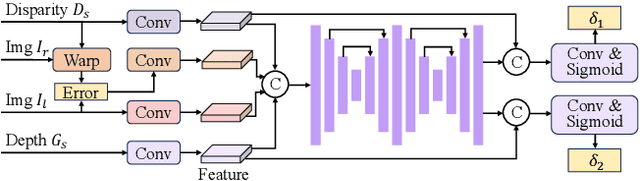
Accurate and dense depth estimation with stereo cameras and LiDAR is an important task for automatic driving and robotic perception. While sparse hints from LiDAR points have improved cost aggregation in stereo matching, their effectiveness is limited by the low density and non-uniform distribution. To address this issue, we propose a novel stereo-LiDAR depth estimation network with Semi-Dense hint Guidance, named SDG-Depth. Our network includes a deformable propagation module for generating a semi-dense hint map and a confidence map by propagating sparse hints using a learned deformable window. These maps then guide cost aggregation in stereo matching. To reduce the triangulation error in depth recovery from disparity, especially in distant regions, we introduce a disparity-depth conversion module. Our method is both accurate and efficient. The experimental results on benchmark tests show its superior performance. Our code is available at https://github.com/SJTU-ViSYS/SDG-Depth.