 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoCo-Sim: Enhancing Roadside Collaborative Perception through Foreground Simulation
Mar 13, 2025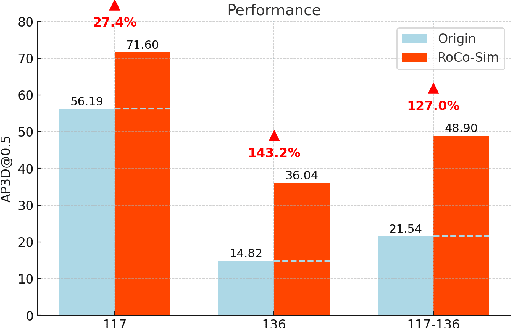
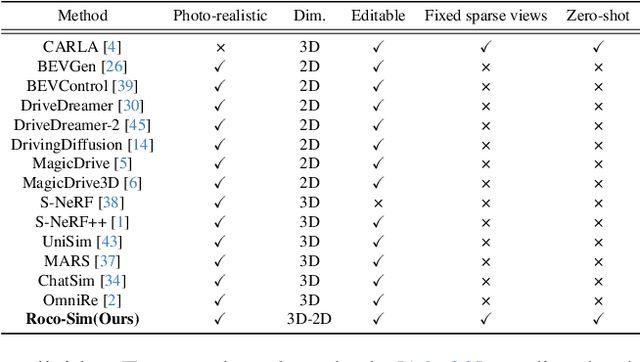


Roadside Collaborative Perception refers to a system where multiple roadside units collaborate to pool their perceptual data, assisting vehicles in enhancing their environmental awareness. Existing roadside perception methods concentrate on model design but overlook data issues like calibration errors, sparse information, and multi-view consistency, leading to poor performance on recent published datasets. To significantly enhance roadside collaborative perception and address critical data issues, we present the first simulation framework RoCo-Sim for road-side collaborative perception. RoCo-Sim is capable of generating diverse, multi-view consistent simulated roadside data through dynamic foreground editing and full-scene style transfer of a single image. RoCo-Sim consists of four components: (1) Camera Extrinsic Optimization ensures accurate 3D to 2D projection for roadside cameras; (2) A novel Multi-View Occlusion-Aware Sampler (MOAS) determines the placement of diverse digital assets within 3D space; (3) DepthSAM innovatively models foreground-background relationships from single-frame fixed-view images, ensuring multi-view consistency of foreground; and (4) Scalable Post-Processing Toolkit generates more realistic and enriched scenes through style transfer and other enhancements. RoCo-Sim significantly improves roadside 3D object detection, outperforming SOTA methods by 83.74 on Rcooper-Intersection and 83.12 on TUMTraf-V2X for AP70. RoCo-Sim fills a critical gap in roadside perception simulation. Code and pre-trained models will be released soon: https://github.com/duyuwen-duen/RoCo-Sim
Towards Collaborative Autonomous Driving: Simulation Platform and End-to-End System
Apr 15, 2024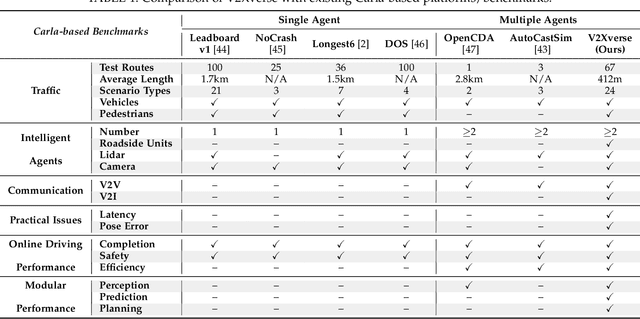
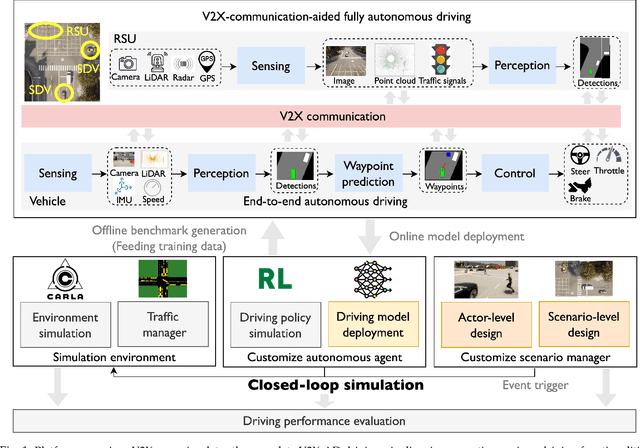

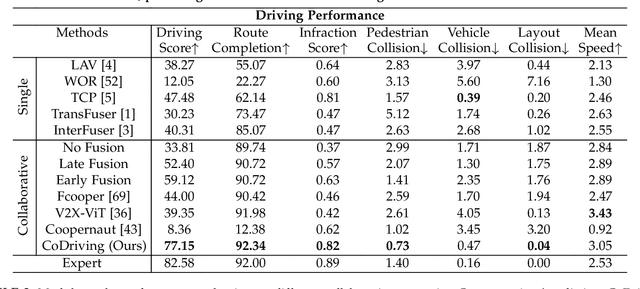
Vehicle-to-everything-aided autonomous driving (V2X-AD) has a huge potential to provide a safer driving solution. Despite extensive researches in transportation and communication to support V2X-AD, the actual utilization of these infrastructures and communication resources in enhancing driving performances remains largely unexplored. This highlights the necessity of collaborative autonomous driving: a machine learning approach that optimizes the information sharing strategy to improve the driving performance of each vehicle. This effort necessitates two key foundations: a platform capable of generating data to facilitate the training and testing of V2X-AD, and a comprehensive system that integrates full driving-related functionalities with mechanisms for information sharing. From the platform perspective, we present V2Xverse, a comprehensive simulation platform for collaborative autonomous driving. This platform provides a complete pipeline for collaborative driving. From the system perspective, we introduce CoDriving, a novel end-to-end collaborative driving system that properly integrates V2X communication over the entire autonomous pipeline, promoting driving with shared perceptual information. The core idea is a novel driving-oriented communication strategy. Leveraging this strategy, CoDriving improves driving performance while optimizing communication efficiency. We make comprehensive benchmarks with V2Xverse, analyzing both modular performance and closed-loop driving performance. Experimental results show that CoDriving: i) significantly improves the driving score by 62.49% and drastically reduces the pedestrian collision rate by 53.50% compared to the SOTA end-to-end driving method, and ii) achieves sustaining driving performance superiority over dynamic constraint communication conditions.
TBP-Former: Learning Temporal Bird's-Eye-View Pyramid for Joint Perception and Prediction in Vision-Centric Autonomous Driving
Mar 22, 2023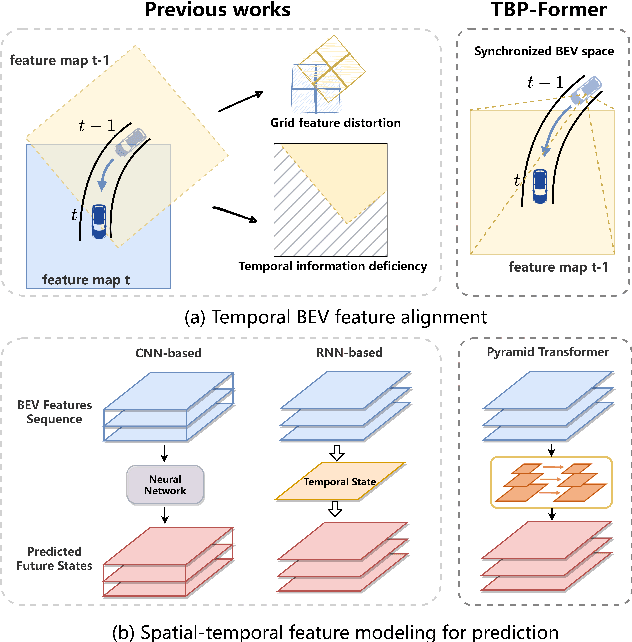

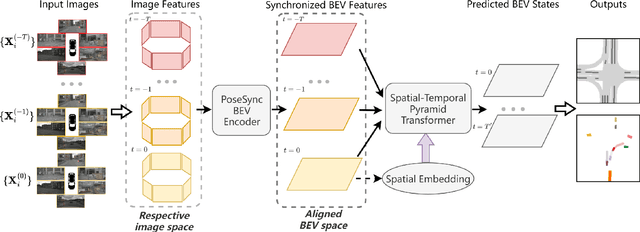

Vision-centric joint perception and prediction (PnP) has become an emerging trend in autonomous driving research. It predicts the future states of the traffic participants in the surrounding environment from raw RGB images. However, it is still a critical challenge to synchronize features obtained at multiple camera views and timestamps due to inevitable geometric distortions and further exploit those spatial-temporal features. To address this issue, we propose a temporal bird's-eye-view pyramid transformer (TBP-Former) for vision-centric PnP, which includes two novel designs. First, a pose-synchronized BEV encoder is proposed to map raw image inputs with any camera pose at any time to a shared and synchronized BEV space for better spatial-temporal synchronization. Second, a spatial-temporal pyramid transformer is introduced to comprehensively extract multi-scale BEV features and predict future BEV states with the support of spatial-temporal priors. Extensive experiments on nuScenes dataset show that our proposed framework overall outperforms all state-of-the-art vision-based prediction methods.