 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthical-Lens: Curbing Malicious Usages of Open-Source Text-to-Image Models
Apr 18, 2024



The burgeoning landscape of text-to-image models, exemplified by innovations such as Midjourney and DALLE 3, has revolutionized content creation across diverse sectors. However, these advancements bring forth critical ethical concerns, particularly with the misuse of open-source models to generate content that violates societal norms. Addressing this, we introduce Ethical-Lens, a framework designed to facilitate the value-aligned usage of text-to-image tools without necessitating internal model revision. Ethical-Lens ensures value alignment in text-to-image models across toxicity and bias dimensions by refining user commands and rectifying model outputs. Systematic evaluation metrics, combining GPT4-V, HEIM, and FairFace scores, assess alignment capability. Our experiments reveal that Ethical-Lens enhances alignment capabilities to levels comparable with or superior to commercial models like DALLE 3, ensuring user-generated content adheres to ethical standards while maintaining image quality. This study indicates the potential of Ethical-Lens to ensure the sustainable development of open-source text-to-image tools and their beneficial integration into society. Our code is available at https://github.com/yuzhu-cai/Ethical-Lens.
Towards Collaborative Autonomous Driving: Simulation Platform and End-to-End System
Apr 15, 2024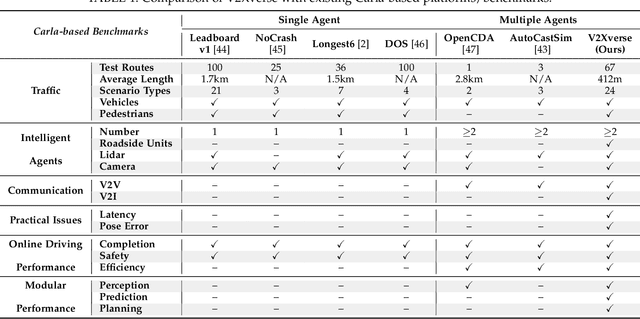
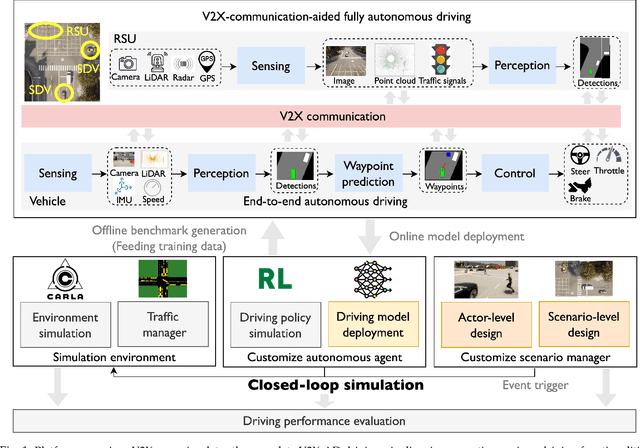

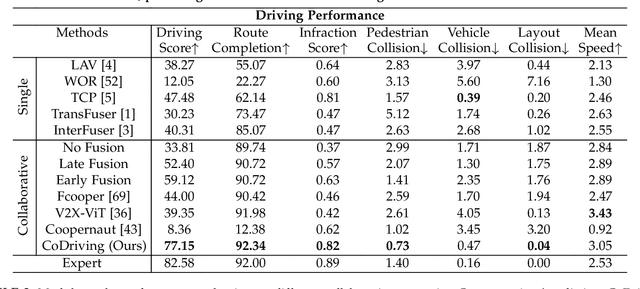
Vehicle-to-everything-aided autonomous driving (V2X-AD) has a huge potential to provide a safer driving solution. Despite extensive researches in transportation and communication to support V2X-AD, the actual utilization of these infrastructures and communication resources in enhancing driving performances remains largely unexplored. This highlights the necessity of collaborative autonomous driving: a machine learning approach that optimizes the information sharing strategy to improve the driving performance of each vehicle. This effort necessitates two key foundations: a platform capable of generating data to facilitate the training and testing of V2X-AD, and a comprehensive system that integrates full driving-related functionalities with mechanisms for information sharing. From the platform perspective, we present V2Xverse, a comprehensive simulation platform for collaborative autonomous driving. This platform provides a complete pipeline for collaborative driving. From the system perspective, we introduce CoDriving, a novel end-to-end collaborative driving system that properly integrates V2X communication over the entire autonomous pipeline, promoting driving with shared perceptual information. The core idea is a novel driving-oriented communication strategy. Leveraging this strategy, CoDriving improves driving performance while optimizing communication efficiency. We make comprehensive benchmarks with V2Xverse, analyzing both modular performance and closed-loop driving performance. Experimental results show that CoDriving: i) significantly improves the driving score by 62.49% and drastically reduces the pedestrian collision rate by 53.50% compared to the SOTA end-to-end driving method, and ii) achieves sustaining driving performance superiority over dynamic constraint communication conditions.
FusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Objection
Sep 11, 2023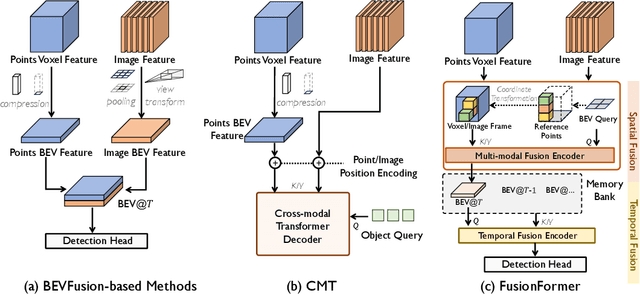
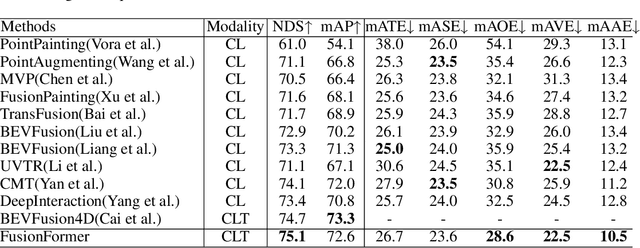
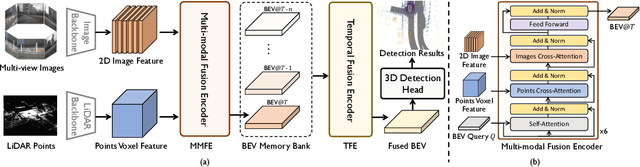
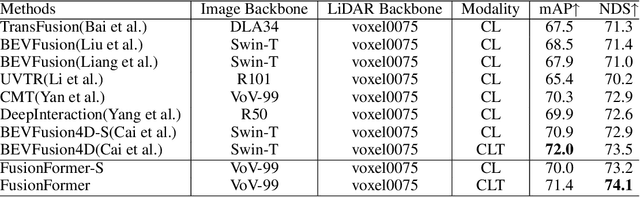
Multi-sensor modal fusion has demonstrated strong advantages in 3D object detection tasks. However, existing methods that fuse multi-modal features through a simple channel concatenation require transformation features into bird's eye view space and may lose the information on Z-axis thus leads to inferior performance. To this end, we propose FusionFormer, an end-to-end multi-modal fusion framework that leverages transformers to fuse multi-modal features and obtain fused BEV features. And based on the flexible adaptability of FusionFormer to the input modality representation, we propose a depth prediction branch that can be added to the framework to improve detection performance in camera-based detection tasks. In addition, we propose a plug-and-play temporal fusion module based on transformers that can fuse historical frame BEV features for more stable and reliable detection results. We evaluate our method on the nuScenes dataset and achieve 72.6% mAP and 75.1% NDS for 3D object detection tasks, outperforming state-of-the-art methods.
FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
Aug 14, 2023



Building a multi-modality multi-task neural network toward accurate and robust performance is a de-facto standard in perception task of autonomous driving. However, leveraging such data from multiple sensors to jointly optimize the prediction and planning tasks remains largely unexplored. In this paper, we present FusionAD, to the best of our knowledge, the first unified framework that fuse the information from two most critical sensors, camera and LiDAR, goes beyond perception task. Concretely, we first build a transformer based multi-modality fusion network to effectively produce fusion based features. In constrast to camera-based end-to-end method UniAD, we then establish a fusion aided modality-aware prediction and status-aware planning modules, dubbed FMSPnP that take advantages of multi-modality features. We conduct extensive experiments on commonly used benchmark nuScenes dataset, our FusionAD achieves state-of-the-art performance and surpassing baselines on average 15% on perception tasks like detection and tracking, 10% on occupancy prediction accuracy, reducing prediction error from 0.708 to 0.389 in ADE score and reduces the collision rate from 0.31% to only 0.12%.
Joint-Relation Transformer for Multi-Person Motion Prediction
Aug 09, 2023



Multi-person motion prediction is a challenging problem due to the dependency of motion on both individual past movements and interactions with other people. Transformer-based methods have shown promising results on this task, but they miss the explicit relation representation between joints, such as skeleton structure and pairwise distance, which is crucial for accurate interaction modeling. In this paper, we propose the Joint-Relation Transformer, which utilizes relation information to enhance interaction modeling and improve future motion prediction. Our relation information contains the relative distance and the intra-/inter-person physical constraints. To fuse relation and joint information, we design a novel joint-relation fusion layer with relation-aware attention to update both features. Additionally, we supervise the relation information by forecasting future distance. Experiments show that our method achieves a 13.4% improvement of 900ms VIM on 3DPW-SoMoF/RC and 17.8%/12.0% improvement of 3s MPJPE on CMU-Mpcap/MuPoTS-3D dataset.
Leapfrog Diffusion Model for Stochastic Trajectory Prediction
Mar 20, 2023



To model the indeterminacy of human behaviors, stochastic trajectory prediction requires a sophisticated multi-modal distribution of future trajectories. Emerging diffusion models have revealed their tremendous representation capacities in numerous generation tasks, showing potential for stochastic trajectory prediction. However, expensive time consumption prevents diffusion models from real-time prediction, since a large number of denoising steps are required to assure sufficient representation ability. To resolve the dilemma, we present LEapfrog Diffusion model (LED), a novel diffusion-based trajectory prediction model, which provides real-time, precise, and diverse predictions. The core of the proposed LED is to leverage a trainable leapfrog initializer to directly learn an expressive multi-modal distribution of future trajectories, which skips a large number of denoising steps, significantly accelerating inference speed. Moreover, the leapfrog initializer is trained to appropriately allocate correlated samples to provide a diversity of predicted future trajectories, significantly improving prediction performances. Extensive experiments on four real-world datasets, including NBA/NFL/SDD/ETH-UCY, show that LED consistently improves performance and achieves 23.7%/21.9% ADE/FDE improvement on NFL. The proposed LED also speeds up the inference 19.3/30.8/24.3/25.1 times compared to the standard diffusion model on NBA/NFL/SDD/ETH-UCY, satisfying real-time inference needs. Code is available at https://github.com/MediaBrain-SJTU/LED.
Remember Intentions: Retrospective-Memory-based Trajectory Prediction
Mar 22, 2022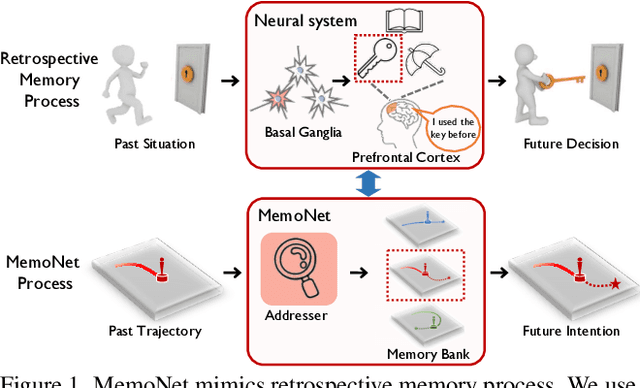
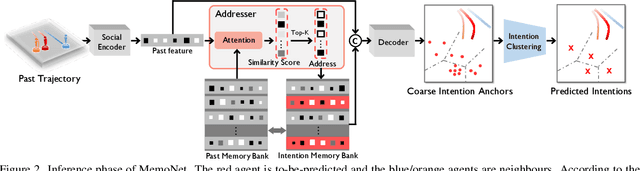

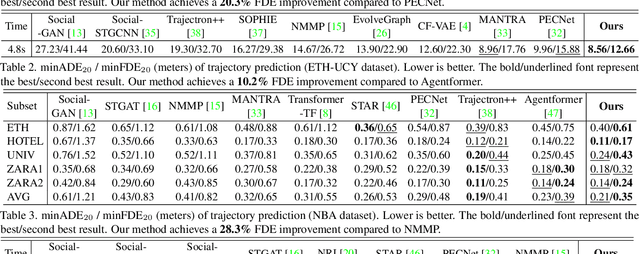
To realize trajectory prediction, most previous methods adopt the parameter-based approach, which encodes all the seen past-future instance pairs into model parameters. However, in this way, the model parameters come from all seen instances, which means a huge amount of irrelevant seen instances might also involve in predicting the current situation, disturbing the performance. To provide a more explicit link between the current situation and the seen instances, we imitate the mechanism of retrospective memory in neuropsychology and propose MemoNet, an instance-based approach that predicts the movement intentions of agents by looking for similar scenarios in the training data. In MemoNet, we design a pair of memory banks to explicitly store representative instances in the training set, acting as prefrontal cortex in the neural system, and a trainable memory addresser to adaptively search a current situation with similar instances in the memory bank, acting like basal ganglia. During prediction, MemoNet recalls previous memory by using the memory addresser to index related instances in the memory bank. We further propose a two-step trajectory prediction system, where the first step is to leverage MemoNet to predict the destination and the second step is to fulfill the whole trajectory according to the predicted destinations. Experiments show that the proposed MemoNet improves the FDE by 20.3%/10.2%/28.3% from the previous best method on SDD/ETH-UCY/NBA datasets. Experiments also show that our MemoNet has the ability to trace back to specific instances during prediction, promoting more interpretability.