 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Objection
Paper and Code
Sep 11, 2023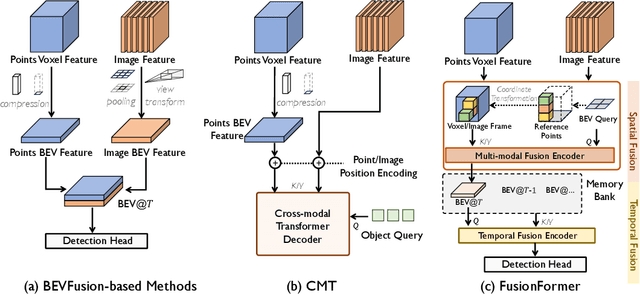
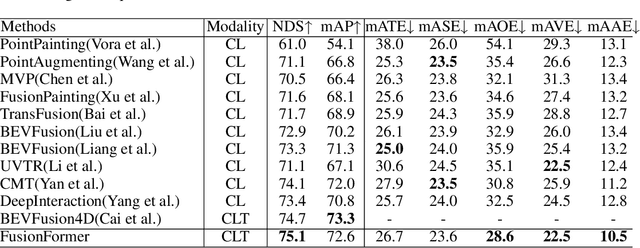
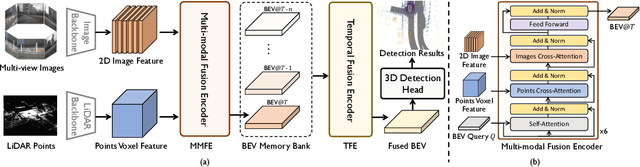
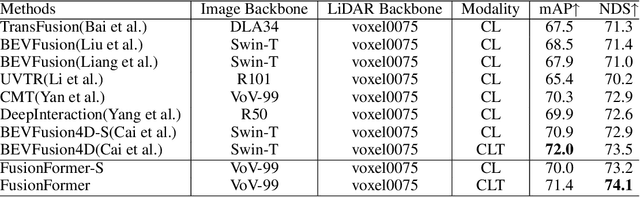
Multi-sensor modal fusion has demonstrated strong advantages in 3D object detection tasks. However, existing methods that fuse multi-modal features through a simple channel concatenation require transformation features into bird's eye view space and may lose the information on Z-axis thus leads to inferior performance. To this end, we propose FusionFormer, an end-to-end multi-modal fusion framework that leverages transformers to fuse multi-modal features and obtain fused BEV features. And based on the flexible adaptability of FusionFormer to the input modality representation, we propose a depth prediction branch that can be added to the framework to improve detection performance in camera-based detection tasks. In addition, we propose a plug-and-play temporal fusion module based on transformers that can fuse historical frame BEV features for more stable and reliable detection results. We evaluate our method on the nuScenes dataset and achieve 72.6% mAP and 75.1% NDS for 3D object detection tasks, outperforming state-of-the-art methods.