 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTMap: Real-Time Recursive Mapping with Change Detection and Localization
Jul 01, 2025While recent online HD mapping methods relieve burdened offline pipelines and solve map freshness, they remain limited by perceptual inaccuracies, occlusion in dense traffic, and an inability to fuse multi-agent observations. We propose RTMap to enhance these single-traversal methods by persistently crowdsourcing a multi-traversal HD map as a self-evolutional memory. On onboard agents, RTMap simultaneously addresses three core challenges in an end-to-end fashion: (1) Uncertainty-aware positional modeling for HD map elements, (2) probabilistic-aware localization w.r.t. the crowdsourced prior-map, and (3) real-time detection for possible road structural changes. Experiments on several public autonomous driving datasets demonstrate our solid performance on both the prior-aided map quality and the localization accuracy, demonstrating our effectiveness of robustly serving downstream prediction and planning modules while gradually improving the accuracy and freshness of the crowdsourced prior-map asynchronously. Our source-code will be made publicly available at https://github.com/CN-ADLab/RTMap (Camera ready version incorporating reviewer suggestions will be updated soon).
Industrial-Grade Sensor Simulation via Gaussian Splatting: A Modular Framework for Scalable Editing and Full-Stack Validation
Mar 14, 2025Sensor simulation is pivotal for scalable validation of autonomous driving systems, yet existing Neural Radiance Fields (NeRF) based methods face applicability and efficiency challenges in industrial workflows. This paper introduces a Gaussian Splatting (GS) based system to address these challenges: We first break down sensor simulator components and analyze the possible advantages of GS over NeRF. Then in practice, we refactor three crucial components through GS, to leverage its explicit scene representation and real-time rendering: (1) choosing the 2D neural Gaussian representation for physics-compliant scene and sensor modeling, (2) proposing a scene editing pipeline to leverage Gaussian primitives library for data augmentation, and (3) coupling a controllable diffusion model for scene expansion and harmonization. We implement this framework on a proprietary autonomous driving dataset supporting cameras and LiDAR sensors. We demonstrate through ablation studies that our approach reduces frame-wise simulation latency, achieves better geometric and photometric consistency, and enables interpretable explicit scene editing and expansion. Furthermore, we showcase how integrating such a GS-based sensor simulator with traffic and dynamic simulators enables full-stack testing of end-to-end autonomy algorithms. Our work provides both algorithmic insights and practical validation, establishing GS as a cornerstone for industrial-grade sensor simulation.
Language Driven Occupancy Prediction
Nov 25, 2024



We introduce LOcc, an effective and generalizable framework for open-vocabulary occupancy (OVO) prediction. Previous approaches typically supervise the networks through coarse voxel-to-text correspondences via image features as intermediates or noisy and sparse correspondences from voxel-based model-view projections. To alleviate the inaccurate supervision, we propose a semantic transitive labeling pipeline to generate dense and finegrained 3D language occupancy ground truth. Our pipeline presents a feasible way to dig into the valuable semantic information of images, transferring text labels from images to LiDAR point clouds and utimately to voxels, to establish precise voxel-to-text correspondences. By replacing the original prediction head of supervised occupancy models with a geometry head for binary occupancy states and a language head for language features, LOcc effectively uses the generated language ground truth to guide the learning of 3D language volume. Through extensive experiments, we demonstrate that our semantic transitive labeling pipeline can produce more accurate pseudo-labeled ground truth, diminishing labor-intensive human annotations. Additionally, we validate LOcc across various architectures, where all models consistently outperform state-ofthe-art zero-shot occupancy prediction approaches on the Occ3D-nuScenes dataset. Notably, even based on the simpler BEVDet model, with an input resolution of 256 * 704,Occ-BEVDet achieves an mIoU of 20.29, surpassing previous approaches that rely on temporal images, higher-resolution inputs, or larger backbone networks. The code for the proposed method is available at https://github.com/pkqbajng/LOcc.
FusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Objection
Sep 11, 2023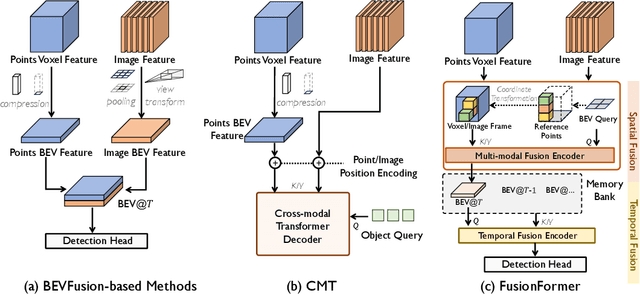
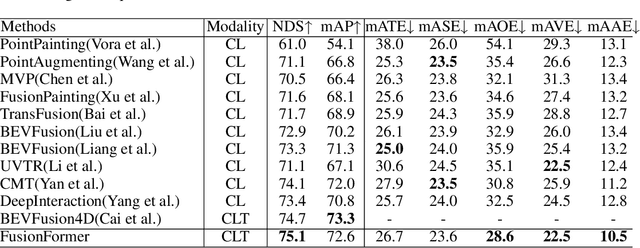
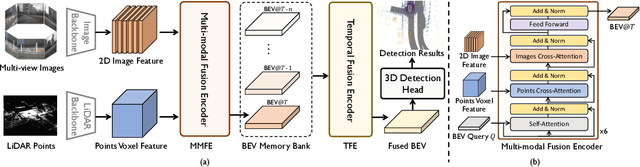
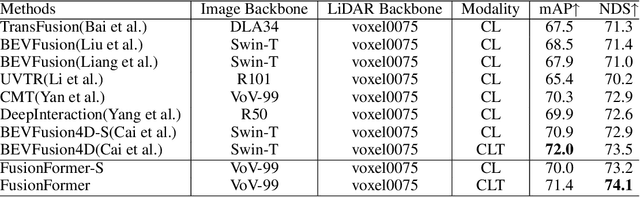
Multi-sensor modal fusion has demonstrated strong advantages in 3D object detection tasks. However, existing methods that fuse multi-modal features through a simple channel concatenation require transformation features into bird's eye view space and may lose the information on Z-axis thus leads to inferior performance. To this end, we propose FusionFormer, an end-to-end multi-modal fusion framework that leverages transformers to fuse multi-modal features and obtain fused BEV features. And based on the flexible adaptability of FusionFormer to the input modality representation, we propose a depth prediction branch that can be added to the framework to improve detection performance in camera-based detection tasks. In addition, we propose a plug-and-play temporal fusion module based on transformers that can fuse historical frame BEV features for more stable and reliable detection results. We evaluate our method on the nuScenes dataset and achieve 72.6% mAP and 75.1% NDS for 3D object detection tasks, outperforming state-of-the-art methods.