 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSMap: 2D Gaussians for Online HD Mapping
May 10, 2026Accurate High-Definition (HD) map construction is critical for autonomous driving, yet existing methods face a fundamental trade-off: vectorization-based approaches preserve topology but struggle with geometric fidelity, while rasterization-based approaches enable precise geometric supervision but produce unstructured outputs. To bridge this gap, we propose GSMap, a novel framework that unifies both paradigms via a learnable 2D Gaussian representation. Each map element is modeled as an ordered sequence of 2D Gaussians, whose centers correspond to the vertices of the vectorized polyline/polygon. This formulation enables simultaneous optimization through: (1) Differentiable rasterization that enforces pixel-level geometric constraints, and (2) Topology-aware vectorization that maintains structural regularity. Experiments on both nuScenes and Argoverse2 demonstrate that our Gaussian-based representation effectively unifies geometric and topological learning, achieving significant performance improvements and demonstrating strong compatibility with existing HD mapping architectures. Code will be available at https://github.com/peakpang/GSMap
RTMap: Real-Time Recursive Mapping with Change Detection and Localization
Jul 01, 2025While recent online HD mapping methods relieve burdened offline pipelines and solve map freshness, they remain limited by perceptual inaccuracies, occlusion in dense traffic, and an inability to fuse multi-agent observations. We propose RTMap to enhance these single-traversal methods by persistently crowdsourcing a multi-traversal HD map as a self-evolutional memory. On onboard agents, RTMap simultaneously addresses three core challenges in an end-to-end fashion: (1) Uncertainty-aware positional modeling for HD map elements, (2) probabilistic-aware localization w.r.t. the crowdsourced prior-map, and (3) real-time detection for possible road structural changes. Experiments on several public autonomous driving datasets demonstrate our solid performance on both the prior-aided map quality and the localization accuracy, demonstrating our effectiveness of robustly serving downstream prediction and planning modules while gradually improving the accuracy and freshness of the crowdsourced prior-map asynchronously. Our source-code will be made publicly available at https://github.com/CN-ADLab/RTMap (Camera ready version incorporating reviewer suggestions will be updated soon).
FusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Objection
Sep 11, 2023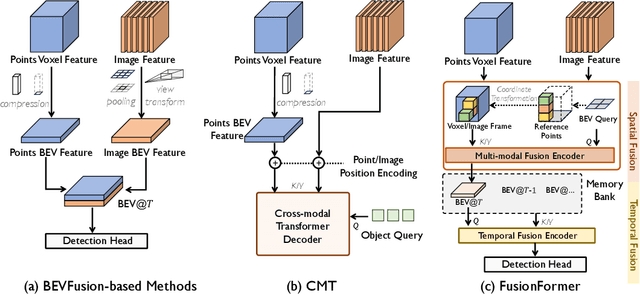
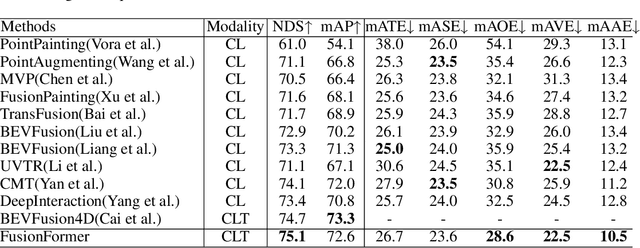
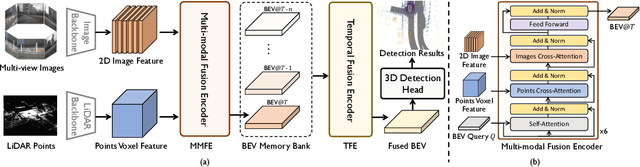
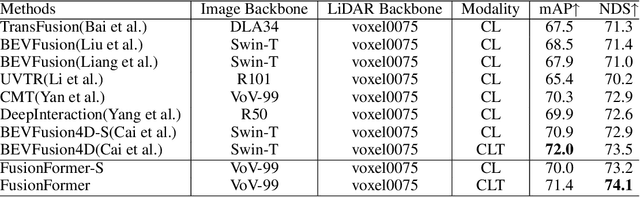
Multi-sensor modal fusion has demonstrated strong advantages in 3D object detection tasks. However, existing methods that fuse multi-modal features through a simple channel concatenation require transformation features into bird's eye view space and may lose the information on Z-axis thus leads to inferior performance. To this end, we propose FusionFormer, an end-to-end multi-modal fusion framework that leverages transformers to fuse multi-modal features and obtain fused BEV features. And based on the flexible adaptability of FusionFormer to the input modality representation, we propose a depth prediction branch that can be added to the framework to improve detection performance in camera-based detection tasks. In addition, we propose a plug-and-play temporal fusion module based on transformers that can fuse historical frame BEV features for more stable and reliable detection results. We evaluate our method on the nuScenes dataset and achieve 72.6% mAP and 75.1% NDS for 3D object detection tasks, outperforming state-of-the-art methods.
CVFNet: Real-time 3D Object Detection by Learning Cross View Features
Mar 13, 2022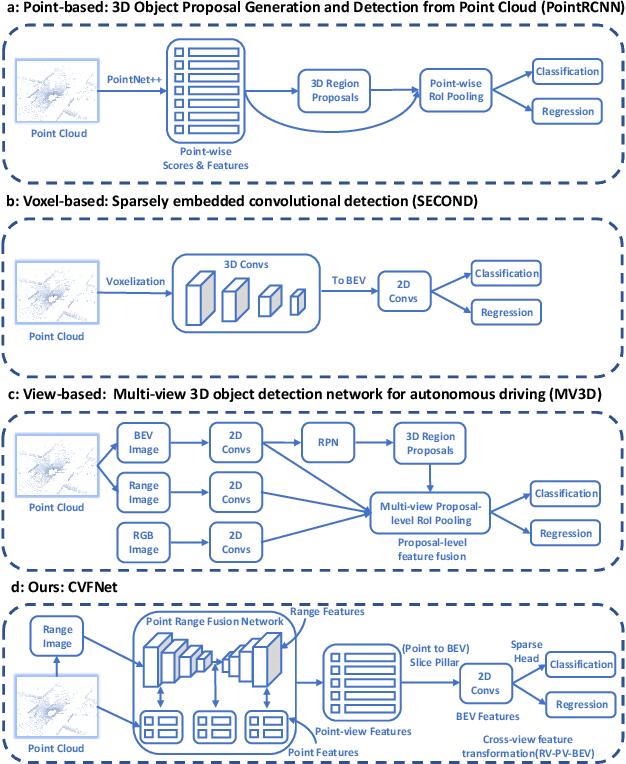

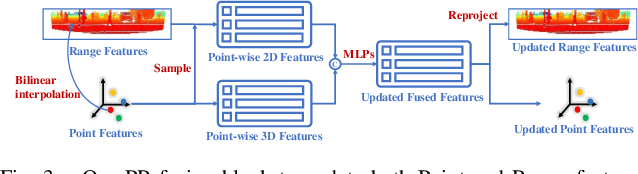
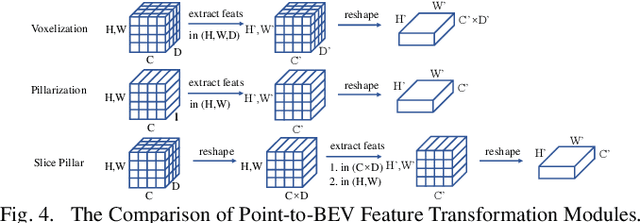
In recent years 3D object detection from LiDAR point clouds has made great progress thanks to the development of deep learning technologies. Although voxel or point based methods are popular in 3D object detection, they usually involve time-consuming operations such as 3D convolutions on voxels or ball query among points, making the resulting network inappropriate for time critical applications. On the other hand, 2D view-based methods feature high computing efficiency while usually obtaining inferior performance than the voxel or point based methods. In this work, we present a real-time view-based single stage 3D object detector, namely CVFNet to fulfill this task. To strengthen the cross-view feature learning under the condition of demanding efficiency, our framework extracts the features of different views and fuses them in an efficient progressive way. We first propose a novel Point-Range feature fusion module that deeply integrates point and range view features in multiple stages. Then, a special Slice Pillar is designed to well maintain the 3D geometry when transforming the obtained deep point-view features into bird's eye view. To better balance the ratio of samples, a sparse pillar detection head is presented to focus the detection on the nonempty grids. We conduct experiments on the popular KITTI and NuScenes benchmark, and state-of-the-art performances are achieved in terms of both accuracy and speed.
DenseLiDAR: A Real-Time Pseudo Dense Depth Guided Depth Completion Network
Aug 28, 2021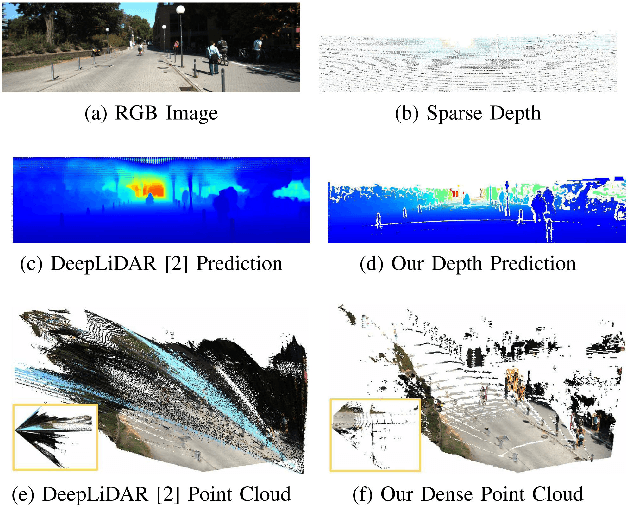
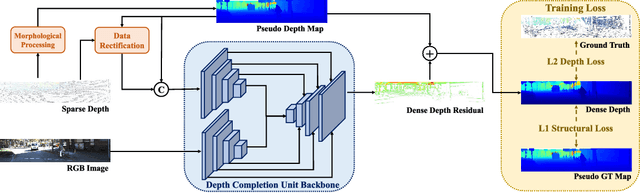


Depth Completion can produce a dense depth map from a sparse input and provide a more complete 3D description of the environment. Despite great progress made in depth completion, the sparsity of the input and low density of the ground truth still make this problem challenging. In this work, we propose DenseLiDAR, a novel real-time pseudo-depth guided depth completion neural network. We exploit dense pseudo-depth map obtained from simple morphological operations to guide the network in three aspects: (1) Constructing a residual structure for the output; (2) Rectifying the sparse input data; (3) Providing dense structural loss for training the network. Thanks to these novel designs, higher performance of the output could be achieved. In addition, two new metrics for better evaluating the quality of the predicted depth map are also presented. Extensive experiments on KITTI depth completion benchmark suggest that our model is able to achieve the state-of-the-art performance at the highest frame rate of 50Hz. The predicted dense depth is further evaluated by several downstream robotic perception or positioning tasks. For the task of 3D object detection, 3~5 percent performance gains on small objects categories are achieved on KITTI 3D object detection dataset. For RGB-D SLAM, higher accuracy on vehicle's trajectory is also obtained in KITTI Odometry dataset. These promising results not only verify the high quality of our depth prediction, but also demonstrate the potential of improving the related downstream tasks by using depth completion results.
* 9 pages, 7 figures, published in IEEE Robotics and Automation Letters and Accepted by ICRA2021