 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaLiFlow: Scene Flow Estimation with 4D Radar and LiDAR Point Clouds
Dec 11, 2025Recent multimodal fusion methods, integrating images with LiDAR point clouds, have shown promise in scene flow estimation. However, the fusion of 4D millimeter wave radar and LiDAR remains unexplored. Unlike LiDAR, radar is cheaper, more robust in various weather conditions and can detect point-wise velocity, making it a valuable complement to LiDAR. However, radar inputs pose challenges due to noise, low resolution, and sparsity. Moreover, there is currently no dataset that combines LiDAR and radar data specifically for scene flow estimation. To address this gap, we construct a Radar-LiDAR scene flow dataset based on a public real-world automotive dataset. We propose an effective preprocessing strategy for radar denoising and scene flow label generation, deriving more reliable flow ground truth for radar points out of the object boundaries. Additionally, we introduce RaLiFlow, the first joint scene flow learning framework for 4D radar and LiDAR, which achieves effective radar-LiDAR fusion through a novel Dynamic-aware Bidirectional Cross-modal Fusion (DBCF) module and a carefully designed set of loss functions. The DBCF module integrates dynamic cues from radar into the local cross-attention mechanism, enabling the propagation of contextual information across modalities. Meanwhile, the proposed loss functions mitigate the adverse effects of unreliable radar data during training and enhance the instance-level consistency in scene flow predictions from both modalities, particularly for dynamic foreground areas. Extensive experiments on the repurposed scene flow dataset demonstrate that our method outperforms existing LiDAR-based and radar-based single-modal methods by a significant margin.
RayFusion: Ray Fusion Enhanced Collaborative Visual Perception
Oct 09, 2025



Collaborative visual perception methods have gained widespread attention in the autonomous driving community in recent years due to their ability to address sensor limitation problems. However, the absence of explicit depth information often makes it difficult for camera-based perception systems, e.g., 3D object detection, to generate accurate predictions. To alleviate the ambiguity in depth estimation, we propose RayFusion, a ray-based fusion method for collaborative visual perception. Using ray occupancy information from collaborators, RayFusion reduces redundancy and false positive predictions along camera rays, enhancing the detection performance of purely camera-based collaborative perception systems. Comprehensive experiments show that our method consistently outperforms existing state-of-the-art models, substantially advancing the performance of collaborative visual perception. The code is available at https://github.com/wangsh0111/RayFusion.
MIDAS: Modeling Ground-Truth Distributions with Dark Knowledge for Domain Generalized Stereo Matching
Mar 06, 2025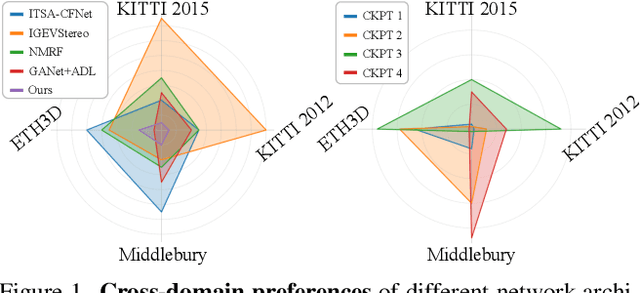



Despite the significant advances in domain generalized stereo matching, existing methods still exhibit domain-specific preferences when transferring from synthetic to real domains, hindering their practical applications in complex and diverse scenarios. The probability distributions predicted by the stereo network naturally encode rich similarity and uncertainty information. Inspired by this observation, we propose to extract these two types of dark knowledge from the pre-trained network to model intuitive multi-modal ground-truth distributions for both edge and non-edge regions. To mitigate the inherent domain preferences of a single network, we adopt network ensemble and further distinguish between objective and biased knowledge in the Laplace parameter space. Finally, the objective knowledge and the original disparity labels are jointly modeled as a mixture of Laplacians to provide fine-grained supervision for the stereo network training. Extensive experiments demonstrate that: 1) Our method is generic and effectively improves the generalization of existing networks. 2) PCWNet with our method achieves the state-of-the-art generalization performance on both KITTI 2015 and 2012 datasets. 3) Our method outperforms existing methods in comprehensive ranking across four popular real-world datasets.
SCKD: Semi-Supervised Cross-Modality Knowledge Distillation for 4D Radar Object Detection
Dec 19, 20243D object detection is one of the fundamental perception tasks for autonomous vehicles. Fulfilling such a task with a 4D millimeter-wave radar is very attractive since the sensor is able to acquire 3D point clouds similar to Lidar while maintaining robust measurements under adverse weather. However, due to the high sparsity and noise associated with the radar point clouds, the performance of the existing methods is still much lower than expected. In this paper, we propose a novel Semi-supervised Cross-modality Knowledge Distillation (SCKD) method for 4D radar-based 3D object detection. It characterizes the capability of learning the feature from a Lidar-radar-fused teacher network with semi-supervised distillation. We first propose an adaptive fusion module in the teacher network to boost its performance. Then, two feature distillation modules are designed to facilitate the cross-modality knowledge transfer. Finally, a semi-supervised output distillation is proposed to increase the effectiveness and flexibility of the distillation framework. With the same network structure, our radar-only student trained by SCKD boosts the mAP by 10.38% over the baseline and outperforms the state-of-the-art works on the VoD dataset. The experiment on ZJUODset also shows 5.12% mAP improvements on the moderate difficulty level over the baseline when extra unlabeled data are available. Code is available at https://github.com/Ruoyu-Xu/SCKD.
RISurConv: Rotation Invariant Surface Attention-Augmented Convolutions for 3D Point Cloud Classification and Segmentation
Aug 12, 2024



Despite the progress on 3D point cloud deep learning, most prior works focus on learning features that are invariant to translation and point permutation, and very limited efforts have been devoted for rotation invariant property. Several recent studies achieve rotation invariance at the cost of lower accuracies. In this work, we close this gap by proposing a novel yet effective rotation invariant architecture for 3D point cloud classification and segmentation. Instead of traditional pointwise operations, we construct local triangle surfaces to capture more detailed surface structure, based on which we can extract highly expressive rotation invariant surface properties which are then integrated into an attention-augmented convolution operator named RISurConv to generate refined attention features via self-attention layers. Based on RISurConv we build an effective neural network for 3D point cloud analysis that is invariant to arbitrary rotations while maintaining high accuracy. We verify the performance on various benchmarks with supreme results obtained surpassing the previous state-of-the-art by a large margin. We achieve an overall accuracy of 96.0% (+4.7%) on ModelNet40, 93.1% (+12.8%) on ScanObjectNN, and class accuracies of 91.5% (+3.6%), 82.7% (+5.1%), and 78.5% (+9.2%) on the three categories of the FG3D dataset for the fine-grained classification task. Additionally, we achieve 81.5% (+1.0%) mIoU on ShapeNet for the segmentation task. Code is available here: https://github.com/cszyzhang/RISurConv
IFTR: An Instance-Level Fusion Transformer for Visual Collaborative Perception
Jul 13, 2024



Multi-agent collaborative perception has emerged as a widely recognized technology in the field of autonomous driving in recent years. However, current collaborative perception predominantly relies on LiDAR point clouds, with significantly less attention given to methods using camera images. This severely impedes the development of budget-constrained collaborative systems and the exploitation of the advantages offered by the camera modality. This work proposes an instance-level fusion transformer for visual collaborative perception (IFTR), which enhances the detection performance of camera-only collaborative perception systems through the communication and sharing of visual features. To capture the visual information from multiple agents, we design an instance feature aggregation that interacts with the visual features of individual agents using predefined grid-shaped bird eye view (BEV) queries, generating more comprehensive and accurate BEV features. Additionally, we devise a cross-domain query adaptation as a heuristic to fuse 2D priors, implicitly encoding the candidate positions of targets. Furthermore, IFTR optimizes communication efficiency by sending instance-level features, achieving an optimal performance-bandwidth trade-off. We evaluate the proposed IFTR on a real dataset, DAIR-V2X, and two simulated datasets, OPV2V and V2XSet, achieving performance improvements of 57.96%, 9.23% and 12.99% in AP@70 metrics compared to the previous SOTAs, respectively. Extensive experiments demonstrate the superiority of IFTR and the effectiveness of its key components. The code is available at https://github.com/wangsh0111/IFTR.
Lite-SAM Is Actually What You Need for Segment Everything
Jul 12, 2024

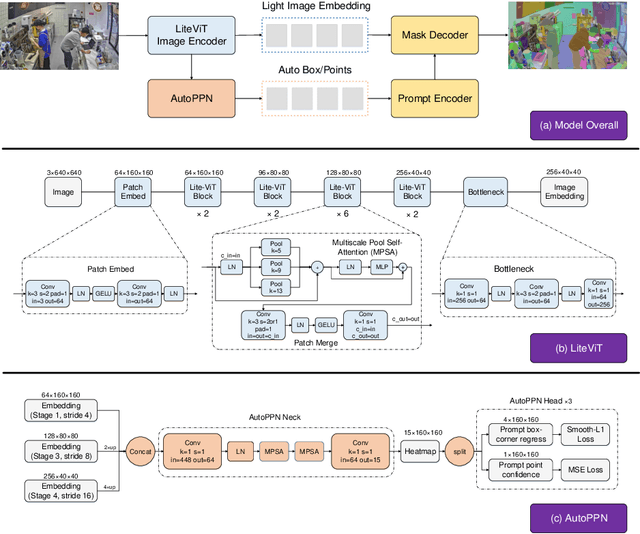

This paper introduces Lite-SAM, an efficient end-to-end solution for the SegEvery task designed to reduce computational costs and redundancy. Lite-SAM is composed of four main components: a streamlined CNN-Transformer hybrid encoder (LiteViT), an automated prompt proposal network (AutoPPN), a traditional prompt encoder, and a mask decoder. All these components are integrated within the SAM framework. Our LiteViT, a high-performance lightweight backbone network, has only 1.16M parameters, which is a 23% reduction compared to the lightest existing backbone network Shufflenet. We also introduce AutoPPN, an innovative end-to-end method for prompt boxes and points generation. This is an improvement over traditional grid search sampling methods, and its unique design allows for easy integration into any SAM series algorithm, extending its usability. we have thoroughly benchmarked Lite-SAM across a plethora of both public and private datasets. The evaluation encompassed a broad spectrum of universal metrics, including the number of parameters, SegEvery execution time, and accuracy. The findings reveal that Lite-SAM, operating with a lean 4.2M parameters, significantly outpaces its counterparts, demonstrating performance improvements of 43x, 31x, 20x, 21x, and 1.6x over SAM, MobileSAM, Edge-SAM, EfficientViT-SAM, and MobileSAM-v2 respectively, all the while maintaining competitive accuracy. This underscores Lite-SAM's prowess in achieving an optimal equilibrium between performance and precision, thereby setting a new state-of-the-art(SOTA) benchmark in the domain.
Rethinking Cross-Entropy Loss for Stereo Matching Networks
Jun 27, 2023



Despite the great success of deep learning in stereo matching, recovering accurate and clearly-contoured disparity map is still challenging. Currently, L1 loss and cross-entropy loss are the two most widely used loss functions for training the stereo matching networks. Comparing with the former, the latter can usually achieve better results thanks to its direct constraint to the the cost volume. However, how to generate reasonable ground-truth distribution for this loss function remains largely under exploited. Existing works assume uni-modal distributions around the ground-truth for all of the pixels, which ignores the fact that the edge pixels may have multi-modal distributions. In this paper, we first experimentally exhibit the importance of correct edge supervision to the overall disparity accuracy. Then a novel adaptive multi-modal cross-entropy loss which encourages the network to generate different distribution patterns for edge and non-edge pixels is proposed. We further optimize the disparity estimator in the inference stage to alleviate the bleeding and misalignment artifacts at the edge. Our method is generic and can help classic stereo matching models regain competitive performance. GANet trained by our loss ranks 1st on the KITTI 2015 and 2012 benchmarks and outperforms state-of-the-art methods by a large margin. Meanwhile, our method also exhibits superior cross-domain generalization ability and outperforms existing generalization-specialized methods on four popular real-world datasets.
RWT-SLAM: Robust Visual SLAM for Highly Weak-textured Environments
Jul 07, 2022
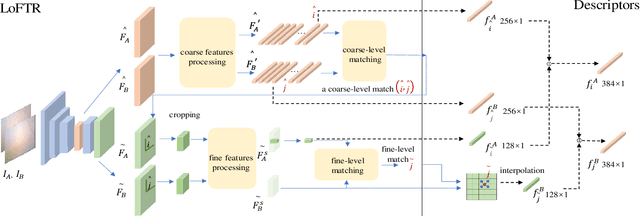
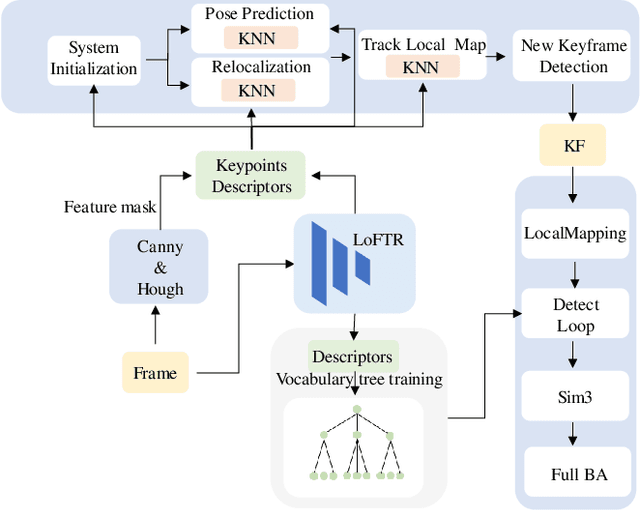

As a fundamental task for intelligent robots, visual SLAM has made great progress over the past decades. However, robust SLAM under highly weak-textured environments still remains very challenging. In this paper, we propose a novel visual SLAM system named RWT-SLAM to tackle this problem. We modify LoFTR network which is able to produce dense point matching under low-textured scenes to generate feature descriptors. To integrate the new features into the popular ORB-SLAM framework, we develop feature masks to filter out the unreliable features and employ KNN strategy to strengthen the matching robustness. We also retrained visual vocabulary upon new descriptors for efficient loop closing. The resulting RWT-SLAM is tested in various public datasets such as TUM and OpenLORIS, as well as our own data. The results shows very promising performance under highly weak-textured environments.
Objects Matter: Learning Object Relation Graph for Robust Camera Relocalization
May 26, 2022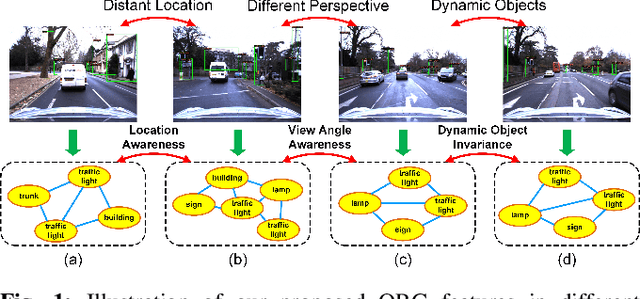
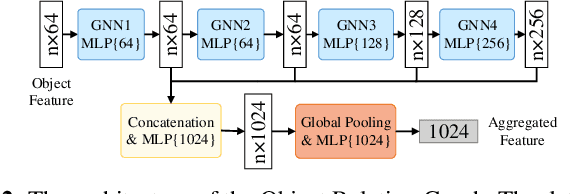
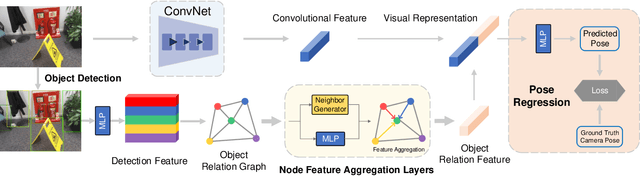
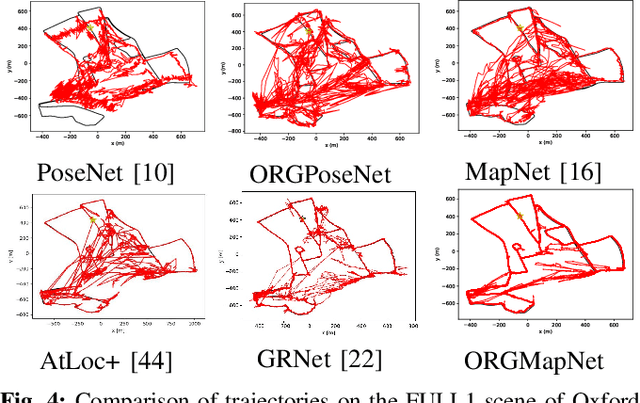
Visual relocalization aims to estimate the pose of a camera from one or more images. In recent years deep learning based pose regression methods have attracted many attentions. They feature predicting the absolute poses without relying on any prior built maps or stored images, making the relocalization very efficient. However, robust relocalization under environments with complex appearance changes and real dynamics remains very challenging. In this paper, we propose to enhance the distinctiveness of the image features by extracting the deep relationship among objects. In particular, we extract objects in the image and construct a deep object relation graph (ORG) to incorporate the semantic connections and relative spatial clues of the objects. We integrate our ORG module into several popular pose regression models. Extensive experiments on various public indoor and outdoor datasets demonstrate that our method improves the performance significantly and outperforms the previous approaches.