 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaLiFlow: Scene Flow Estimation with 4D Radar and LiDAR Point Clouds
Dec 11, 2025Recent multimodal fusion methods, integrating images with LiDAR point clouds, have shown promise in scene flow estimation. However, the fusion of 4D millimeter wave radar and LiDAR remains unexplored. Unlike LiDAR, radar is cheaper, more robust in various weather conditions and can detect point-wise velocity, making it a valuable complement to LiDAR. However, radar inputs pose challenges due to noise, low resolution, and sparsity. Moreover, there is currently no dataset that combines LiDAR and radar data specifically for scene flow estimation. To address this gap, we construct a Radar-LiDAR scene flow dataset based on a public real-world automotive dataset. We propose an effective preprocessing strategy for radar denoising and scene flow label generation, deriving more reliable flow ground truth for radar points out of the object boundaries. Additionally, we introduce RaLiFlow, the first joint scene flow learning framework for 4D radar and LiDAR, which achieves effective radar-LiDAR fusion through a novel Dynamic-aware Bidirectional Cross-modal Fusion (DBCF) module and a carefully designed set of loss functions. The DBCF module integrates dynamic cues from radar into the local cross-attention mechanism, enabling the propagation of contextual information across modalities. Meanwhile, the proposed loss functions mitigate the adverse effects of unreliable radar data during training and enhance the instance-level consistency in scene flow predictions from both modalities, particularly for dynamic foreground areas. Extensive experiments on the repurposed scene flow dataset demonstrate that our method outperforms existing LiDAR-based and radar-based single-modal methods by a significant margin.
MIDAS: Modeling Ground-Truth Distributions with Dark Knowledge for Domain Generalized Stereo Matching
Mar 06, 2025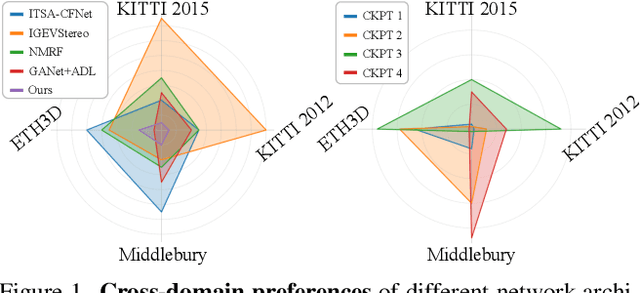



Despite the significant advances in domain generalized stereo matching, existing methods still exhibit domain-specific preferences when transferring from synthetic to real domains, hindering their practical applications in complex and diverse scenarios. The probability distributions predicted by the stereo network naturally encode rich similarity and uncertainty information. Inspired by this observation, we propose to extract these two types of dark knowledge from the pre-trained network to model intuitive multi-modal ground-truth distributions for both edge and non-edge regions. To mitigate the inherent domain preferences of a single network, we adopt network ensemble and further distinguish between objective and biased knowledge in the Laplace parameter space. Finally, the objective knowledge and the original disparity labels are jointly modeled as a mixture of Laplacians to provide fine-grained supervision for the stereo network training. Extensive experiments demonstrate that: 1) Our method is generic and effectively improves the generalization of existing networks. 2) PCWNet with our method achieves the state-of-the-art generalization performance on both KITTI 2015 and 2012 datasets. 3) Our method outperforms existing methods in comprehensive ranking across four popular real-world datasets.
Rethinking Cross-Entropy Loss for Stereo Matching Networks
Jun 27, 2023



Despite the great success of deep learning in stereo matching, recovering accurate and clearly-contoured disparity map is still challenging. Currently, L1 loss and cross-entropy loss are the two most widely used loss functions for training the stereo matching networks. Comparing with the former, the latter can usually achieve better results thanks to its direct constraint to the the cost volume. However, how to generate reasonable ground-truth distribution for this loss function remains largely under exploited. Existing works assume uni-modal distributions around the ground-truth for all of the pixels, which ignores the fact that the edge pixels may have multi-modal distributions. In this paper, we first experimentally exhibit the importance of correct edge supervision to the overall disparity accuracy. Then a novel adaptive multi-modal cross-entropy loss which encourages the network to generate different distribution patterns for edge and non-edge pixels is proposed. We further optimize the disparity estimator in the inference stage to alleviate the bleeding and misalignment artifacts at the edge. Our method is generic and can help classic stereo matching models regain competitive performance. GANet trained by our loss ranks 1st on the KITTI 2015 and 2012 benchmarks and outperforms state-of-the-art methods by a large margin. Meanwhile, our method also exhibits superior cross-domain generalization ability and outperforms existing generalization-specialized methods on four popular real-world datasets.