 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Distributed Multi-UGV Exploration Framework With Loop-Aware Planning and Descriptor-Aided Localization in Resource-Limited Environments
Jun 09, 2026Robust and efficient cooperative exploration with multiple unmanned ground vehicles (UGVs) in unknown, GPSdenied, and bandwidth-limited environments without prior maps remains challenging, as localization drift degrades map consistency and induces redundant coverage. This paper presents a fully distributed exploration framework that couples descriptoraided inter-UGV loop closure with loop-aware hierarchical planning while enabling autonomous localization and exploration. We develop a lightweight LiDAR global descriptor with range-image prealignment to enable robust cross-UGV place recognition under large yaw and lateral variations, and use verified loop closures to maintain globally consistent trajectories and a sparse topological representation. We further introduce an uncertainty-aware crossUGV loop-closure selection module that scores candidate loop closures under pose uncertainty and retains high-utility loop closures as planning anchors for global task allocation and local route refinement. Simulations and real-UGV experiments show that the loop-closure module achieves AR@1/AR@1% of 89.9%/95.5%, distributed optimization reduces absolute trajectory error, the system substantially reduces two-way communication volume, and the overall framework reduces exploration time and travel distance by 15% and 14%, respectively, compared with an mTSP baseline.
SCKD: Semi-Supervised Cross-Modality Knowledge Distillation for 4D Radar Object Detection
Dec 19, 20243D object detection is one of the fundamental perception tasks for autonomous vehicles. Fulfilling such a task with a 4D millimeter-wave radar is very attractive since the sensor is able to acquire 3D point clouds similar to Lidar while maintaining robust measurements under adverse weather. However, due to the high sparsity and noise associated with the radar point clouds, the performance of the existing methods is still much lower than expected. In this paper, we propose a novel Semi-supervised Cross-modality Knowledge Distillation (SCKD) method for 4D radar-based 3D object detection. It characterizes the capability of learning the feature from a Lidar-radar-fused teacher network with semi-supervised distillation. We first propose an adaptive fusion module in the teacher network to boost its performance. Then, two feature distillation modules are designed to facilitate the cross-modality knowledge transfer. Finally, a semi-supervised output distillation is proposed to increase the effectiveness and flexibility of the distillation framework. With the same network structure, our radar-only student trained by SCKD boosts the mAP by 10.38% over the baseline and outperforms the state-of-the-art works on the VoD dataset. The experiment on ZJUODset also shows 5.12% mAP improvements on the moderate difficulty level over the baseline when extra unlabeled data are available. Code is available at https://github.com/Ruoyu-Xu/SCKD.
TeFF: Tracking-enhanced Forgetting-free Few-shot 3D LiDAR Semantic Segmentation
Aug 28, 2024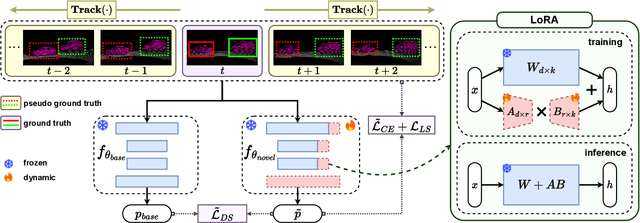
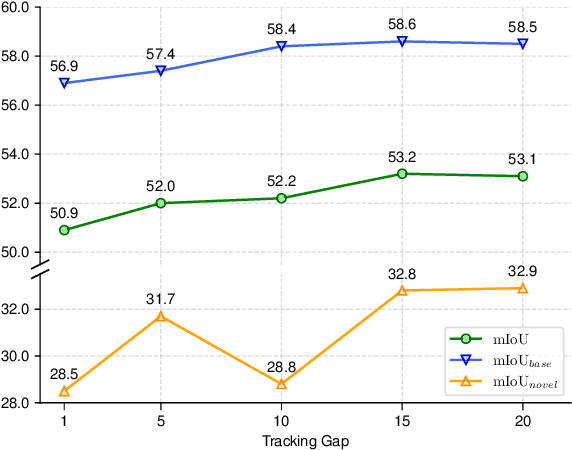
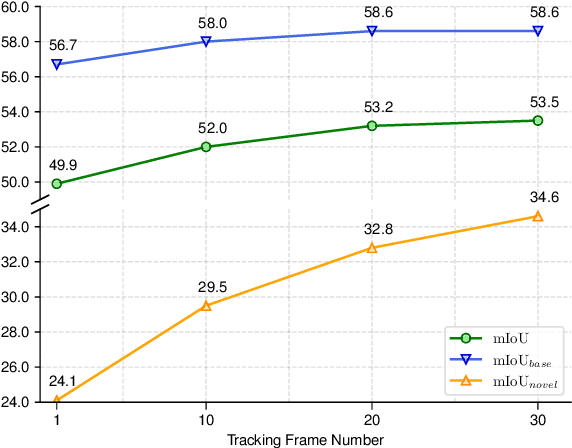
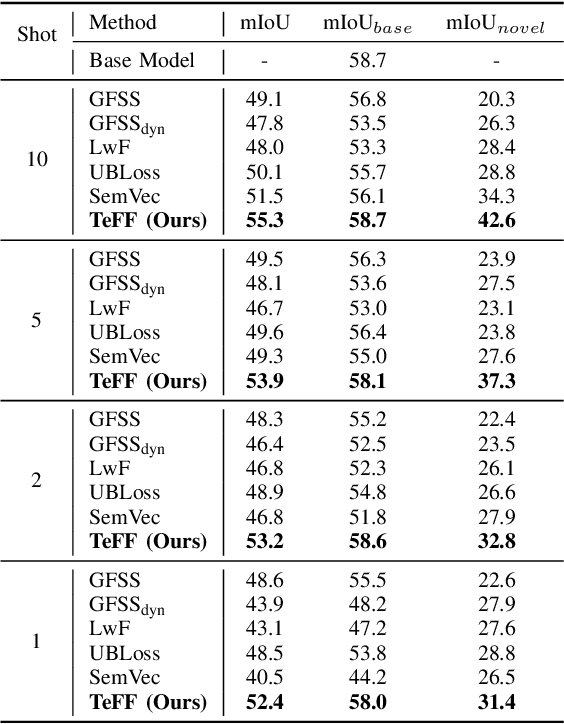
In autonomous driving, 3D LiDAR plays a crucial role in understanding the vehicle's surroundings. However, the newly emerged, unannotated objects presents few-shot learning problem for semantic segmentation. This paper addresses the limitations of current few-shot semantic segmentation by exploiting the temporal continuity of LiDAR data. Employing a tracking model to generate pseudo-ground-truths from a sequence of LiDAR frames, our method significantly augments the dataset, enhancing the model's ability to learn on novel classes. However, this approach introduces a data imbalance biased to novel data that presents a new challenge of catastrophic forgetting. To mitigate this, we incorporate LoRA, a technique that reduces the number of trainable parameters, thereby preserving the model's performance on base classes while improving its adaptability to novel classes. This work represents a significant step forward in few-shot 3D LiDAR semantic segmentation for autonomous driving. Our code is available at https://github.com/junbao-zhou/Track-no-forgetting.
Rethinking Cross-Entropy Loss for Stereo Matching Networks
Jun 27, 2023



Despite the great success of deep learning in stereo matching, recovering accurate and clearly-contoured disparity map is still challenging. Currently, L1 loss and cross-entropy loss are the two most widely used loss functions for training the stereo matching networks. Comparing with the former, the latter can usually achieve better results thanks to its direct constraint to the the cost volume. However, how to generate reasonable ground-truth distribution for this loss function remains largely under exploited. Existing works assume uni-modal distributions around the ground-truth for all of the pixels, which ignores the fact that the edge pixels may have multi-modal distributions. In this paper, we first experimentally exhibit the importance of correct edge supervision to the overall disparity accuracy. Then a novel adaptive multi-modal cross-entropy loss which encourages the network to generate different distribution patterns for edge and non-edge pixels is proposed. We further optimize the disparity estimator in the inference stage to alleviate the bleeding and misalignment artifacts at the edge. Our method is generic and can help classic stereo matching models regain competitive performance. GANet trained by our loss ranks 1st on the KITTI 2015 and 2012 benchmarks and outperforms state-of-the-art methods by a large margin. Meanwhile, our method also exhibits superior cross-domain generalization ability and outperforms existing generalization-specialized methods on four popular real-world datasets.
RWT-SLAM: Robust Visual SLAM for Highly Weak-textured Environments
Jul 07, 2022
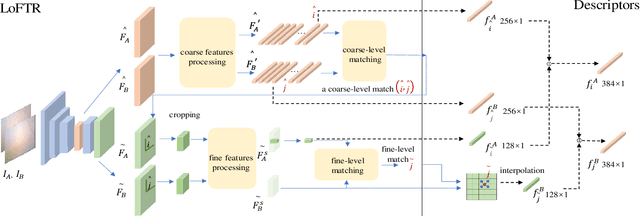
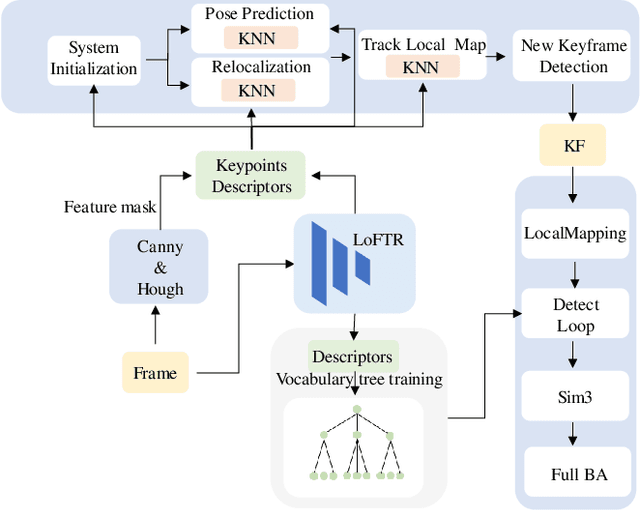

As a fundamental task for intelligent robots, visual SLAM has made great progress over the past decades. However, robust SLAM under highly weak-textured environments still remains very challenging. In this paper, we propose a novel visual SLAM system named RWT-SLAM to tackle this problem. We modify LoFTR network which is able to produce dense point matching under low-textured scenes to generate feature descriptors. To integrate the new features into the popular ORB-SLAM framework, we develop feature masks to filter out the unreliable features and employ KNN strategy to strengthen the matching robustness. We also retrained visual vocabulary upon new descriptors for efficient loop closing. The resulting RWT-SLAM is tested in various public datasets such as TUM and OpenLORIS, as well as our own data. The results shows very promising performance under highly weak-textured environments.
An Active and Contrastive Learning Framework for Fine-Grained Off-Road Semantic Segmentation
Feb 18, 2022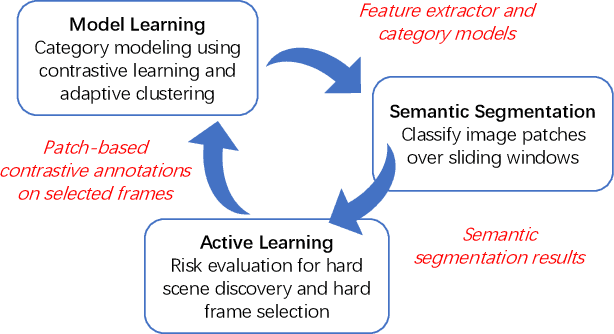
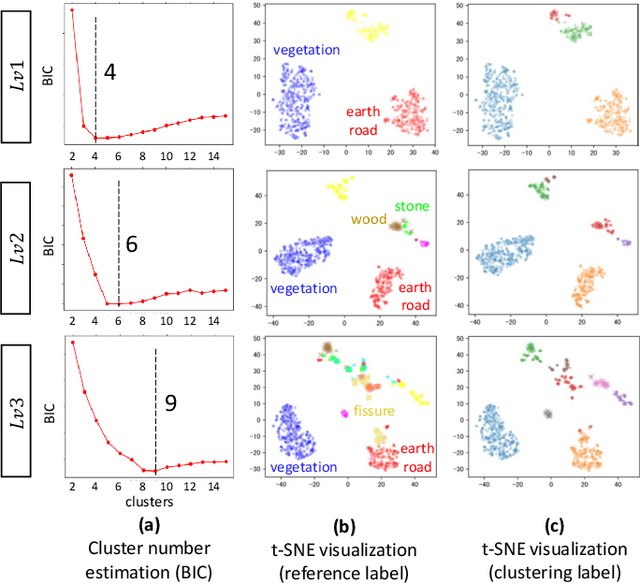
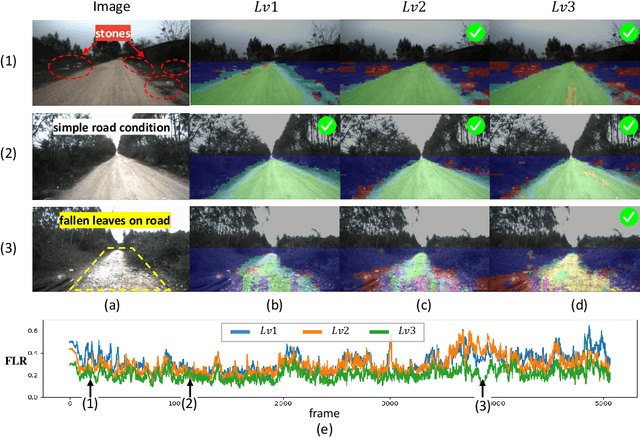
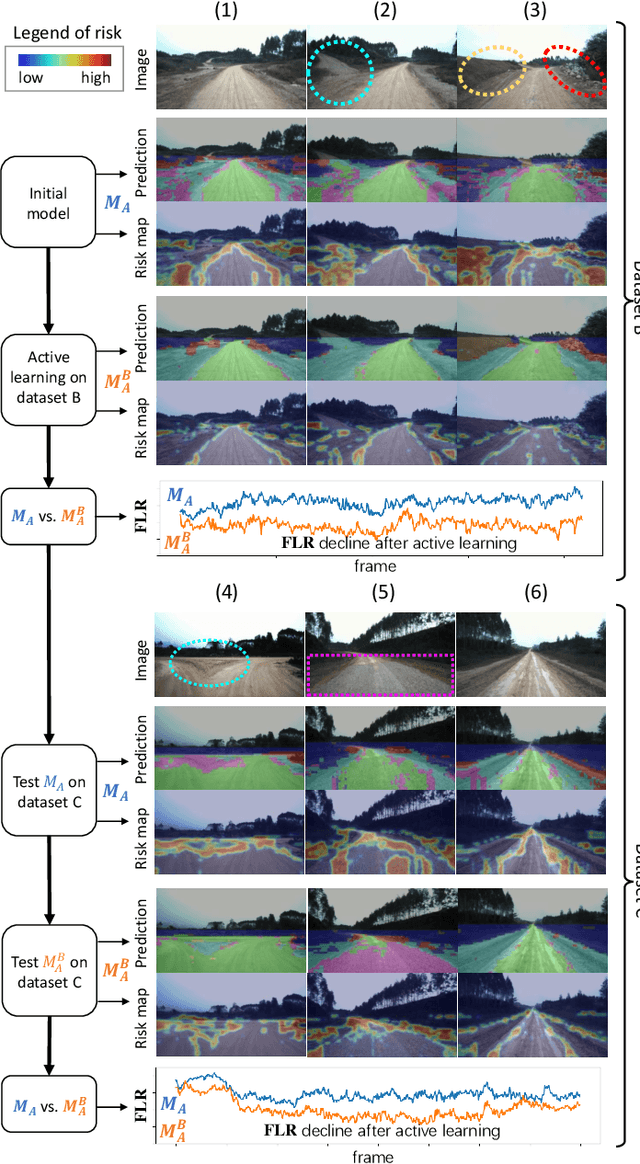
Off-road semantic segmentation with fine-grained labels is necessary for autonomous vehicles to understand driving scenes, as the coarse-grained road detection can not satisfy off-road vehicles with various mechanical properties. Fine-grained semantic segmentation in off-road scenes usually has no unified category definition due to ambiguous nature environments, and the cost of pixel-wise labeling is extremely high. Furthermore, semantic properties of off-road scenes can be very changeable due to various precipitations, temperature, defoliation, etc. To address these challenges, this research proposes an active and contrastive learning-based method that does not rely on pixel-wise labels, but only on patch-based weak annotations for model learning. There is no need for predefined semantic categories, the contrastive learning-based feature representation and adaptive clustering will discover the category model from scene data. In order to actively adapt to new scenes, a risk evaluation method is proposed to discover and select hard frames with high-risk predictions for supplemental labeling, so as to update the model efficiently. Experiments conducted on our self-developed off-road dataset and DeepScene dataset demonstrate that fine-grained semantic segmentation can be learned with only dozens of weakly labeled frames, and the model can efficiently adapt across scenes by weak supervision, while achieving almost the same level of performance as typical fully supervised baselines.
Fine-Grained Off-Road Semantic Segmentation and Mapping via Contrastive Learning
Mar 05, 2021


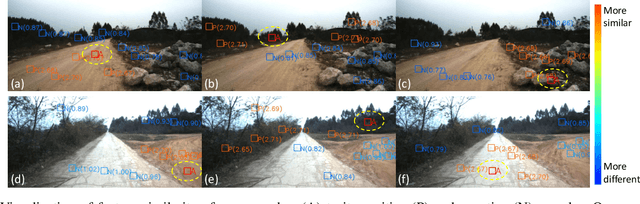
Road detection or traversability analysis has been a key technique for a mobile robot to traverse complex off-road scenes. The problem has been mainly formulated in early works as a binary classification one, e.g. associating pixels with road or non-road labels. Whereas understanding scenes with fine-grained labels are needed for off-road robots, as scenes are very diverse, and the various mechanical performance of off-road robots may lead to different definitions of safe regions to traverse. How to define and annotate fine-grained labels to achieve meaningful scene understanding for a robot to traverse off-road is still an open question. This research proposes a contrastive learning based method. With a set of human-annotated anchor patches, a feature representation is learned to discriminate regions with different traversability, a method of fine-grained semantic segmentation and mapping is subsequently developed for off-road scene understanding. Experiments are conducted on a dataset of three driving segments that represent very diverse off-road scenes. An anchor accuracy of 89.8% is achieved by evaluating the matching with human-annotated image patches in cross-scene validation. Examined by associated 3D LiDAR data, the fine-grained segments of visual images are demonstrated to have different levels of toughness and terrain elevation, which represents their semantical meaningfulness. The resultant maps contain both fine-grained labels and confidence values, providing rich information to support a robot traversing complex off-road scenes.
Off-Road Drivable Area Extraction Using 3D LiDAR Data
Mar 10, 2020


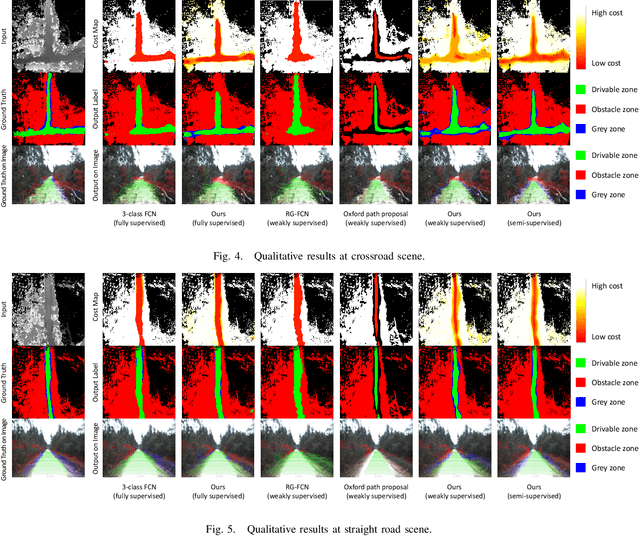
We propose a method for off-road drivable area extraction using 3D LiDAR data with the goal of autonomous driving application. A specific deep learning framework is designed to deal with the ambiguous area, which is one of the main challenges in the off-road environment. To reduce the considerable demand for human-annotated data for network training, we utilize the information from vast quantities of vehicle paths and auto-generated obstacle labels. Using these autogenerated annotations, the proposed network can be trained using weakly supervised or semi-supervised methods, which can achieve better performance with fewer human annotations. The experiments on our dataset illustrate the reasonability of our framework and the validity of our weakly and semi-supervised methods.
Semantic Segmentation of 3D LiDAR Data in Dynamic Scene Using Semi-supervised Learning
Sep 03, 2018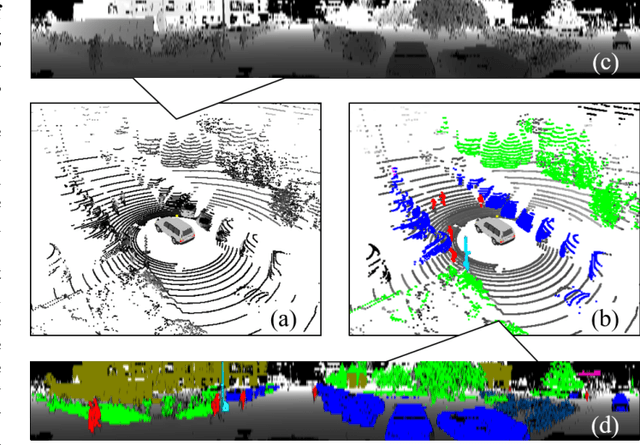
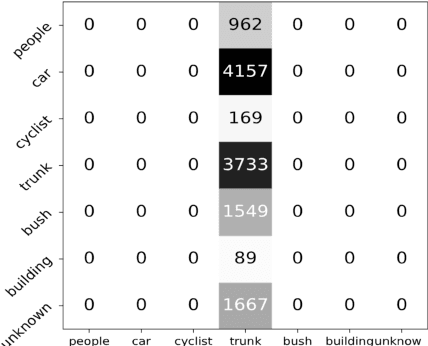
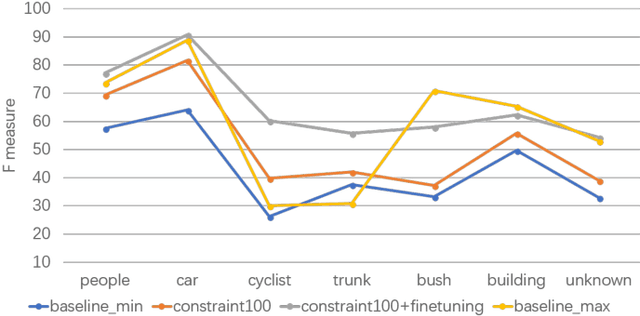

This work studies the semantic segmentation of 3D LiDAR data in dynamic scenes for autonomous driving applications. A system of semantic segmentation using 3D LiDAR data, including range image segmentation, sample generation, inter-frame data association, track-level annotation and semi-supervised learning, is developed. To reduce the considerable requirement of fine annotations, a CNN-based classifier is trained by considering both supervised samples with manually labeled object classes and pairwise constraints, where a data sample is composed of a segment as the foreground and neighborhood points as the background. A special loss function is designed to account for both annotations and constraints, where the constraint data are encouraged to be assigned to the same semantic class. A dataset containing 1838 frames of LiDAR data, 39934 pairwise constraints and 57927 human annotations is developed. The performance of the method is examined extensively. Qualitative and quantitative experiments show that the combination of a few annotations and large amount of constraint data significantly enhances the effectiveness and scene adaptability, resulting in greater than 10% improvement