 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSAIC: Bridging the Sim-to-Real Gap in Generalist Humanoid Motion Tracking and Teleoperation with Rapid Residual Adaptation
Feb 09, 2026Generalist humanoid motion trackers have recently achieved strong simulation metrics by scaling data and training, yet often remain brittle on hardware during sustained teleoperation due to interface- and dynamics-induced errors. We present MOSAIC, an open-source, full-stack system for humanoid motion tracking and whole-body teleoperation across multiple interfaces. MOSAIC first learns a teleoperation-oriented general motion tracker via RL on a multi-source motion bank with adaptive resampling and rewards that emphasize world-frame motion consistency, which is critical for mobile teleoperation. To bridge the sim-to-real interface gap without sacrificing generality, MOSAIC then performs rapid residual adaptation: an interface-specific policy is trained using minimal interface-specific data, and then distilled into the general tracker through an additive residual module, outperforming naive fine-tuning or continual learning. We validate MOSAIC with systematic ablations, out-of-distribution benchmarking, and real-robot experiments demonstrating robust offline motion replay and online long-horizon teleoperation under realistic latency and noise.
An Active and Contrastive Learning Framework for Fine-Grained Off-Road Semantic Segmentation
Feb 18, 2022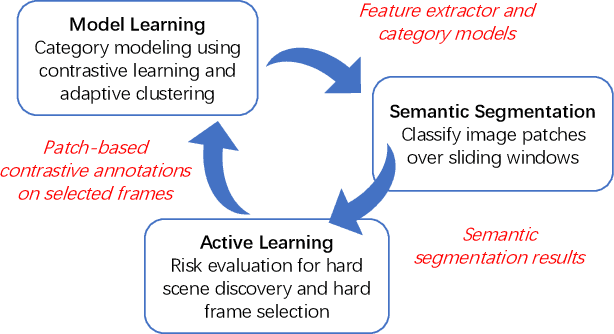
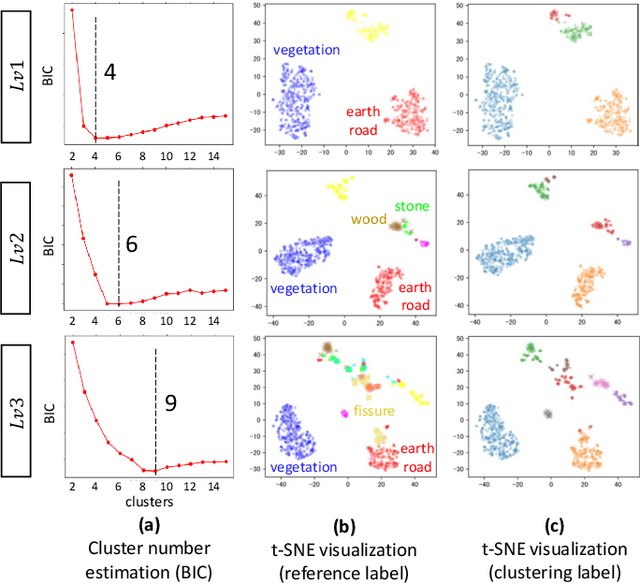
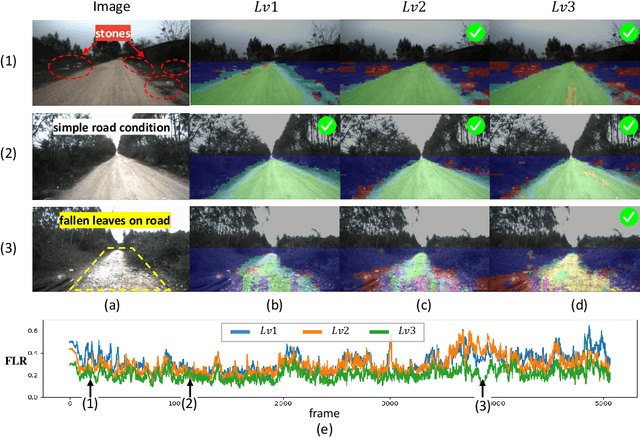
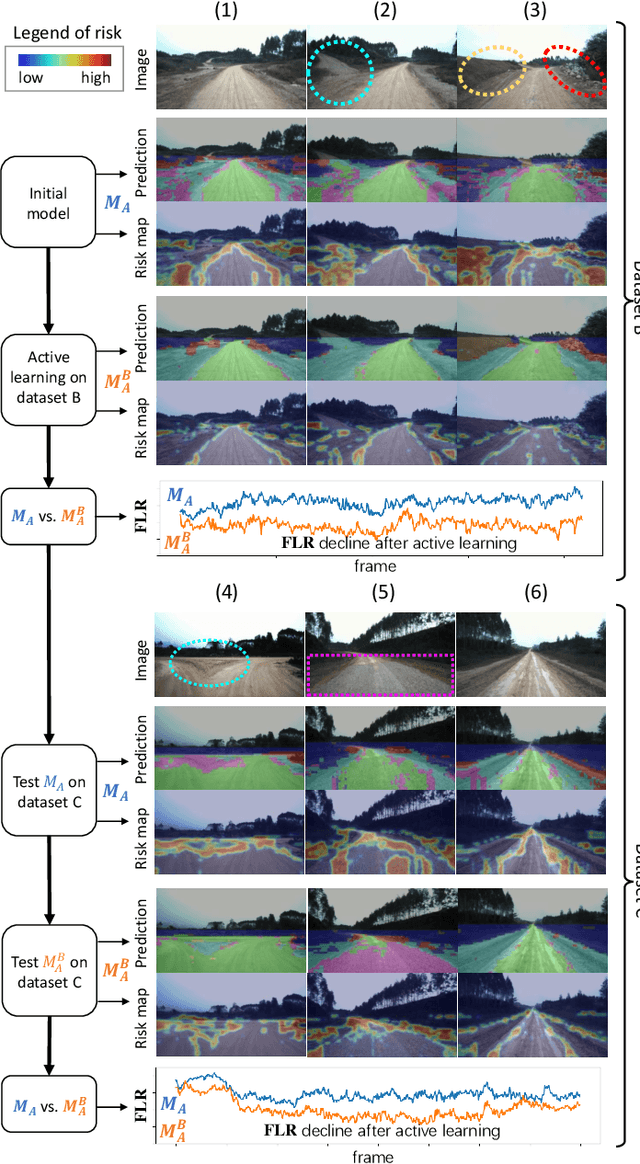
Off-road semantic segmentation with fine-grained labels is necessary for autonomous vehicles to understand driving scenes, as the coarse-grained road detection can not satisfy off-road vehicles with various mechanical properties. Fine-grained semantic segmentation in off-road scenes usually has no unified category definition due to ambiguous nature environments, and the cost of pixel-wise labeling is extremely high. Furthermore, semantic properties of off-road scenes can be very changeable due to various precipitations, temperature, defoliation, etc. To address these challenges, this research proposes an active and contrastive learning-based method that does not rely on pixel-wise labels, but only on patch-based weak annotations for model learning. There is no need for predefined semantic categories, the contrastive learning-based feature representation and adaptive clustering will discover the category model from scene data. In order to actively adapt to new scenes, a risk evaluation method is proposed to discover and select hard frames with high-risk predictions for supplemental labeling, so as to update the model efficiently. Experiments conducted on our self-developed off-road dataset and DeepScene dataset demonstrate that fine-grained semantic segmentation can be learned with only dozens of weakly labeled frames, and the model can efficiently adapt across scenes by weak supervision, while achieving almost the same level of performance as typical fully supervised baselines.
An Image-based Approach of Task-driven Driving Scene Categorization
Mar 10, 2021

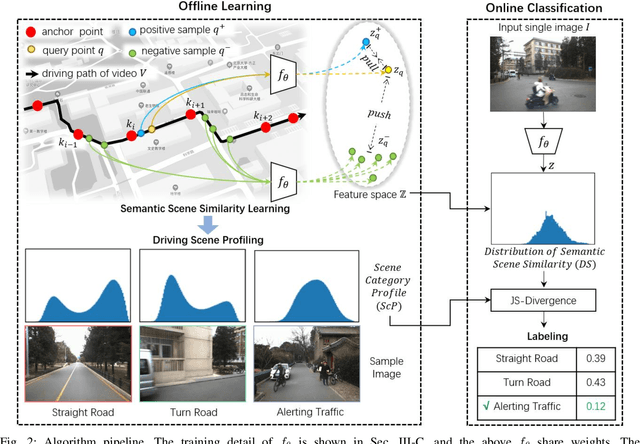
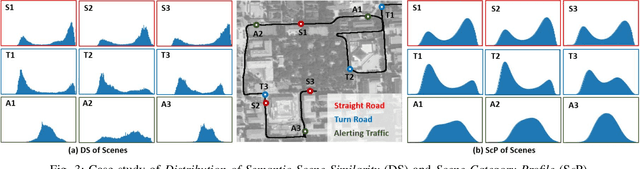
Categorizing driving scenes via visual perception is a key technology for safe driving and the downstream tasks of autonomous vehicles. Traditional methods infer scene category by detecting scene-related objects or using a classifier that is trained on large datasets of fine-labeled scene images. Whereas at cluttered dynamic scenes such as campus or park, human activities are not strongly confined by rules, and the functional attributes of places are not strongly correlated with objects. So how to define, model and infer scene categories is crucial to make the technique really helpful in assisting a robot to pass through the scene. This paper proposes a method of task-driven driving scene categorization using weakly supervised data. Given a front-view video of a driving scene, a set of anchor points is marked by following the decision making of a human driver, where an anchor point is not a semantic label but an indicator meaning the semantic attribute of the scene is different from that of the previous one. A measure is learned to discriminate the scenes of different semantic attributes via contrastive learning, and a driving scene profiling and categorization method is developed based on that measure. Experiments are conducted on a front-view video that is recorded when a vehicle passed through the cluttered dynamic campus of Peking University. The scenes are categorized into straight road, turn road and alerting traffic. The results of semantic scene similarity learning and driving scene categorization are extensively studied, and positive result of scene categorization is 97.17 \% on the learning video and 85.44\% on the video of new scenes.
Fine-Grained Off-Road Semantic Segmentation and Mapping via Contrastive Learning
Mar 05, 2021


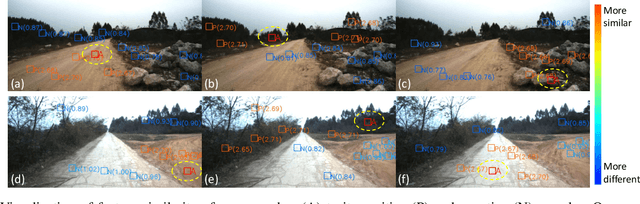
Road detection or traversability analysis has been a key technique for a mobile robot to traverse complex off-road scenes. The problem has been mainly formulated in early works as a binary classification one, e.g. associating pixels with road or non-road labels. Whereas understanding scenes with fine-grained labels are needed for off-road robots, as scenes are very diverse, and the various mechanical performance of off-road robots may lead to different definitions of safe regions to traverse. How to define and annotate fine-grained labels to achieve meaningful scene understanding for a robot to traverse off-road is still an open question. This research proposes a contrastive learning based method. With a set of human-annotated anchor patches, a feature representation is learned to discriminate regions with different traversability, a method of fine-grained semantic segmentation and mapping is subsequently developed for off-road scene understanding. Experiments are conducted on a dataset of three driving segments that represent very diverse off-road scenes. An anchor accuracy of 89.8% is achieved by evaluating the matching with human-annotated image patches in cross-scene validation. Examined by associated 3D LiDAR data, the fine-grained segments of visual images are demonstrated to have different levels of toughness and terrain elevation, which represents their semantical meaningfulness. The resultant maps contain both fine-grained labels and confidence values, providing rich information to support a robot traversing complex off-road scenes.
Are We Hungry for 3D LiDAR Data for Semantic Segmentation?
Jun 08, 2020
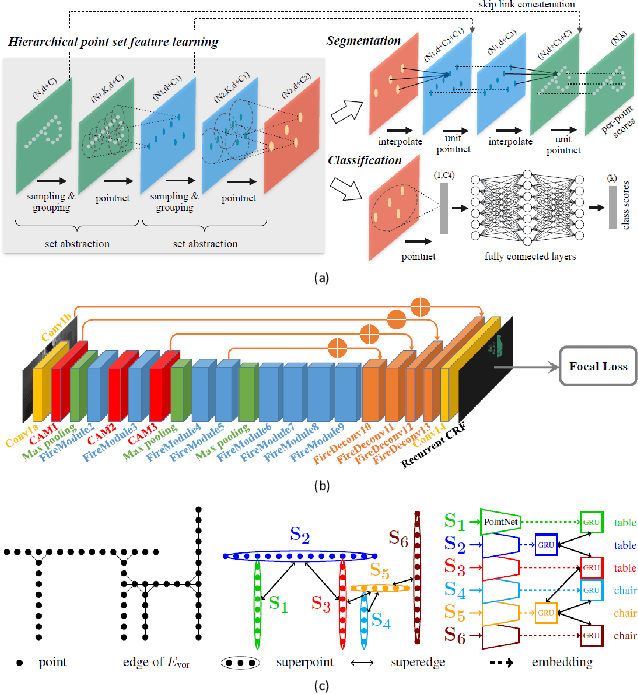
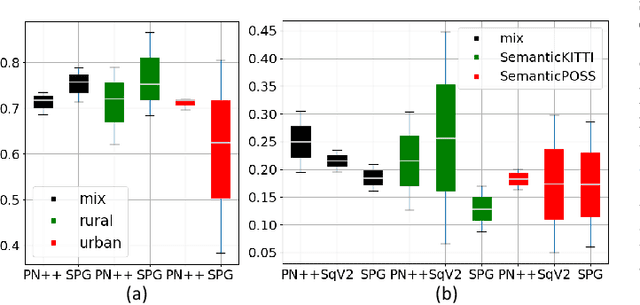
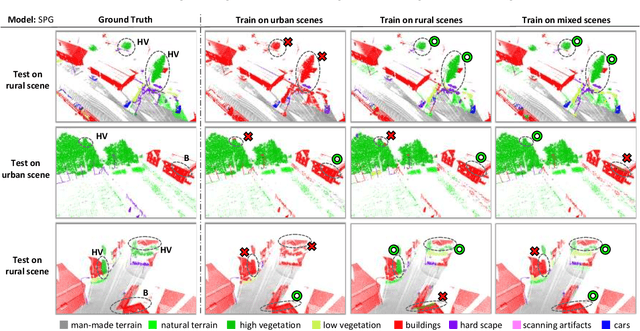
3D LiDAR semantic segmentation is a pivotal task that is widely involved in many applications, such as autonomous driving and robotics. Studies of 3D LiDAR semantic segmentation have recently achieved considerable development, especially in terms of deep learning strategies. However, these studies usually rely heavily on considerable fine annotated data, while point-wise 3D LiDAR datasets are extremely insufficient and expensive to label. The performance limitation caused by the lack of training data is called the data hungry effect. This survey aims to explore whether and how we are hungry for 3D LiDAR data for semantic segmentation. Thus, we first provide an organized review of existing 3D datasets and 3D semantic segmentation methods. Then, we provide an in-depth analysis of three representative datasets and several experiments to evaluate the data hungry effects in different aspects. Efforts to solve data hungry problems are summarized for both 3D LiDAR-focused methods and general-purpose methods. Finally, insightful topics are discussed for future research on data hungry problems and open questions.
Off-Road Drivable Area Extraction Using 3D LiDAR Data
Mar 10, 2020


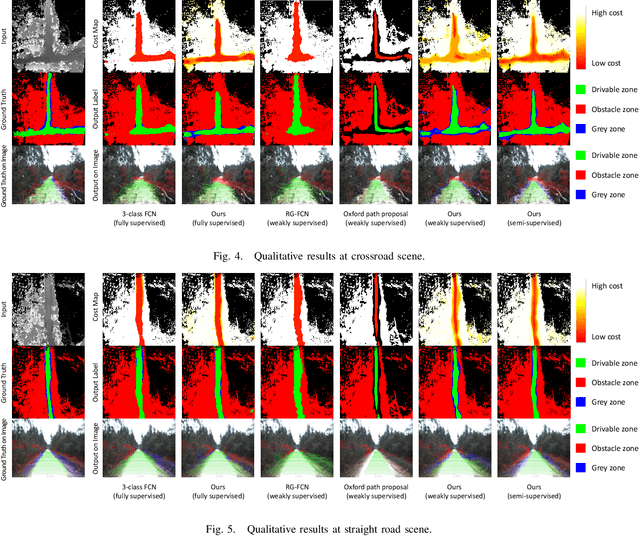
We propose a method for off-road drivable area extraction using 3D LiDAR data with the goal of autonomous driving application. A specific deep learning framework is designed to deal with the ambiguous area, which is one of the main challenges in the off-road environment. To reduce the considerable demand for human-annotated data for network training, we utilize the information from vast quantities of vehicle paths and auto-generated obstacle labels. Using these autogenerated annotations, the proposed network can be trained using weakly supervised or semi-supervised methods, which can achieve better performance with fewer human annotations. The experiments on our dataset illustrate the reasonability of our framework and the validity of our weakly and semi-supervised methods.
SemanticPOSS: A Point Cloud Dataset with Large Quantity of Dynamic Instances
Feb 21, 2020
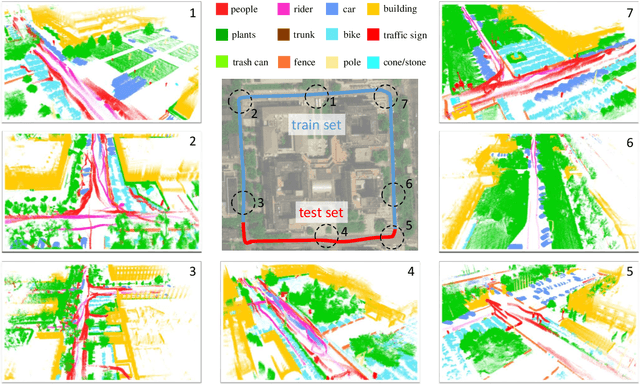

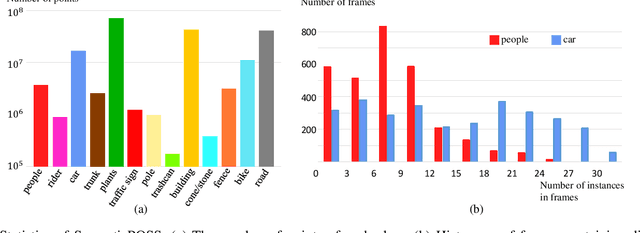
3D semantic segmentation is one of the key tasks for autonomous driving system. Recently, deep learning models for 3D semantic segmentation task have been widely researched, but they usually require large amounts of training data. However, the present datasets for 3D semantic segmentation are lack of point-wise annotation, diversiform scenes and dynamic objects. In this paper, we propose the SemanticPOSS dataset, which contains 2988 various and complicated LiDAR scans with large quantity of dynamic instances. The data is collected in Peking University and uses the same data format as SemanticKITTI. In addition, we evaluate several typical 3D semantic segmentation models on our SemanticPOSS dataset. Experimental results show that SemanticPOSS can help to improve the prediction accuracy of dynamic objects as people, car in some degree. SemanticPOSS will be published at \url{www.poss.pku.edu.cn}.
Semantic Segmentation of 3D LiDAR Data in Dynamic Scene Using Semi-supervised Learning
Sep 03, 2018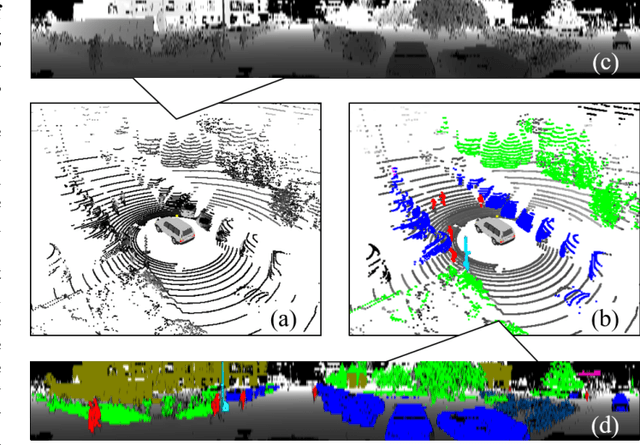
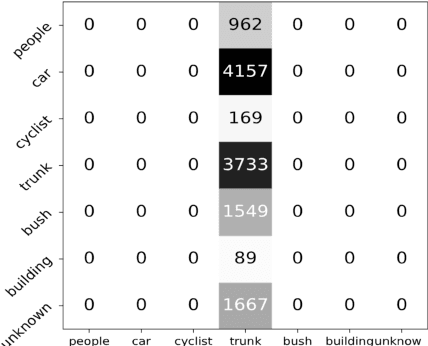
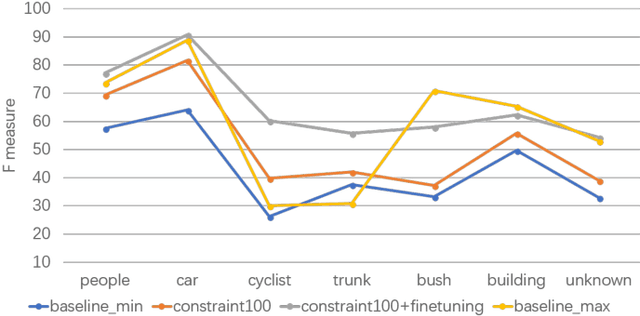

This work studies the semantic segmentation of 3D LiDAR data in dynamic scenes for autonomous driving applications. A system of semantic segmentation using 3D LiDAR data, including range image segmentation, sample generation, inter-frame data association, track-level annotation and semi-supervised learning, is developed. To reduce the considerable requirement of fine annotations, a CNN-based classifier is trained by considering both supervised samples with manually labeled object classes and pairwise constraints, where a data sample is composed of a segment as the foreground and neighborhood points as the background. A special loss function is designed to account for both annotations and constraints, where the constraint data are encouraged to be assigned to the same semantic class. A dataset containing 1838 frames of LiDAR data, 39934 pairwise constraints and 57927 human annotations is developed. The performance of the method is examined extensively. Qualitative and quantitative experiments show that the combination of a few annotations and large amount of constraint data significantly enhances the effectiveness and scene adaptability, resulting in greater than 10% improvement