 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Image-based Approach of Task-driven Driving Scene Categorization
Mar 10, 2021

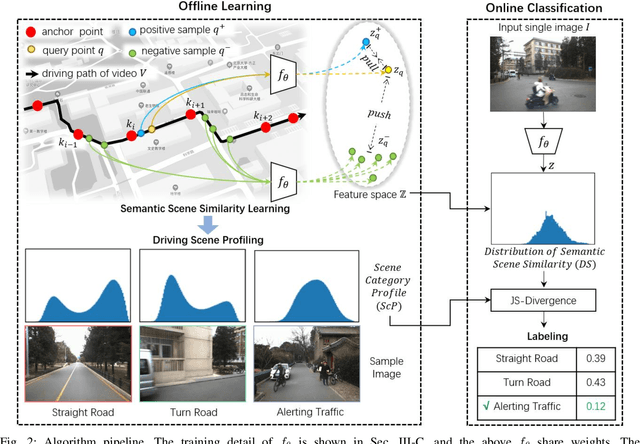
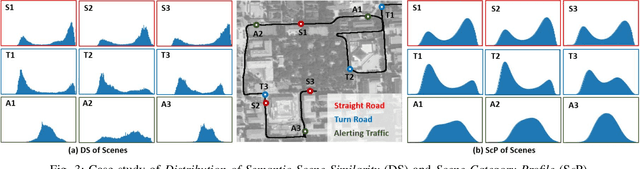
Categorizing driving scenes via visual perception is a key technology for safe driving and the downstream tasks of autonomous vehicles. Traditional methods infer scene category by detecting scene-related objects or using a classifier that is trained on large datasets of fine-labeled scene images. Whereas at cluttered dynamic scenes such as campus or park, human activities are not strongly confined by rules, and the functional attributes of places are not strongly correlated with objects. So how to define, model and infer scene categories is crucial to make the technique really helpful in assisting a robot to pass through the scene. This paper proposes a method of task-driven driving scene categorization using weakly supervised data. Given a front-view video of a driving scene, a set of anchor points is marked by following the decision making of a human driver, where an anchor point is not a semantic label but an indicator meaning the semantic attribute of the scene is different from that of the previous one. A measure is learned to discriminate the scenes of different semantic attributes via contrastive learning, and a driving scene profiling and categorization method is developed based on that measure. Experiments are conducted on a front-view video that is recorded when a vehicle passed through the cluttered dynamic campus of Peking University. The scenes are categorized into straight road, turn road and alerting traffic. The results of semantic scene similarity learning and driving scene categorization are extensively studied, and positive result of scene categorization is 97.17 \% on the learning video and 85.44\% on the video of new scenes.
Fine-Grained Off-Road Semantic Segmentation and Mapping via Contrastive Learning
Mar 05, 2021


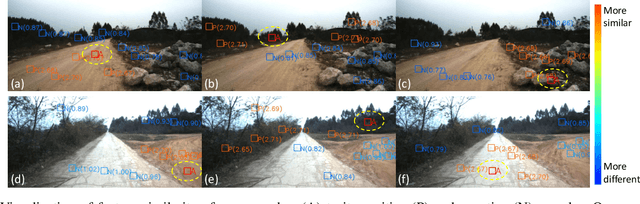
Road detection or traversability analysis has been a key technique for a mobile robot to traverse complex off-road scenes. The problem has been mainly formulated in early works as a binary classification one, e.g. associating pixels with road or non-road labels. Whereas understanding scenes with fine-grained labels are needed for off-road robots, as scenes are very diverse, and the various mechanical performance of off-road robots may lead to different definitions of safe regions to traverse. How to define and annotate fine-grained labels to achieve meaningful scene understanding for a robot to traverse off-road is still an open question. This research proposes a contrastive learning based method. With a set of human-annotated anchor patches, a feature representation is learned to discriminate regions with different traversability, a method of fine-grained semantic segmentation and mapping is subsequently developed for off-road scene understanding. Experiments are conducted on a dataset of three driving segments that represent very diverse off-road scenes. An anchor accuracy of 89.8% is achieved by evaluating the matching with human-annotated image patches in cross-scene validation. Examined by associated 3D LiDAR data, the fine-grained segments of visual images are demonstrated to have different levels of toughness and terrain elevation, which represents their semantical meaningfulness. The resultant maps contain both fine-grained labels and confidence values, providing rich information to support a robot traversing complex off-road scenes.
Cross Scene Prediction via Modeling Dynamic Correlation using Latent Space Shared Auto-Encoders
Mar 31, 2020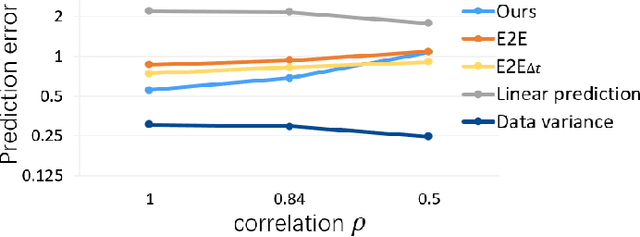
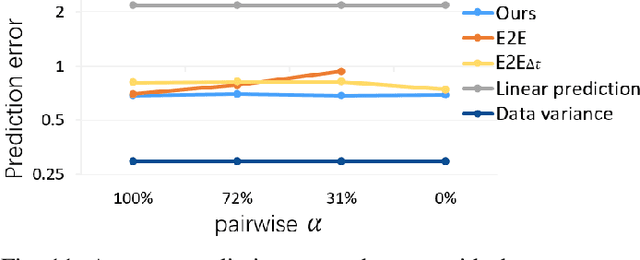
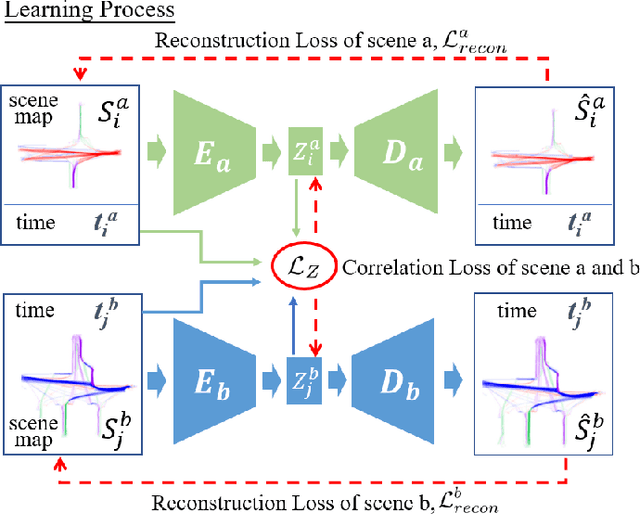
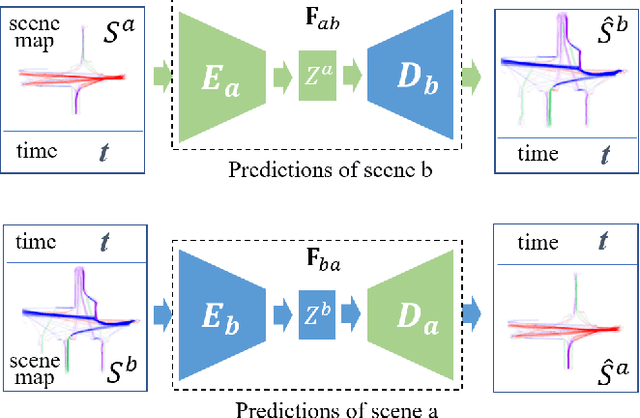
This work addresses on the following problem: given a set of unsynchronized history observations of two scenes that are correlative on their dynamic changes, the purpose is to learn a cross-scene predictor, so that with the observation of one scene, a robot can onlinely predict the dynamic state of another. A method is proposed to solve the problem via modeling dynamic correlation using latent space shared auto-encoders. Assuming that the inherent correlation of scene dynamics can be represented by shared latent space, where a common latent state is reached if the observations of both scenes are at an approximate time, a learning model is developed by connecting two auto-encoders through the latent space, and a prediction model is built by concatenating the encoder of the input scene with the decoder of the target one. Simulation datasets are generated imitating the dynamic flows at two adjacent gates of a campus, where the dynamic changes are triggered by a common working and teaching schedule. Similar scenarios can also be found at successive intersections on a single road, gates of a subway station, etc. Accuracy of cross-scene prediction is examined at various conditions of scene correlation and pairwise observations. Potentials of the proposed method are demonstrated by comparing with conventional end-to-end methods and linear predictions.