 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeeding Up Path Planning via Reinforcement Learning in MCTS for Automated Parking
Mar 25, 2024



In this paper, we address a method that integrates reinforcement learning into the Monte Carlo tree search to boost online path planning under fully observable environments for automated parking tasks. Sampling-based planning methods under high-dimensional space can be computationally expensive and time-consuming. State evaluation methods are useful by leveraging the prior knowledge into the search steps, making the process faster in a real-time system. Given the fact that automated parking tasks are often executed under complex environments, a solid but lightweight heuristic guidance is challenging to compose in a traditional analytical way. To overcome this limitation, we propose a reinforcement learning pipeline with a Monte Carlo tree search under the path planning framework. By iteratively learning the value of a state and the best action among samples from its previous cycle's outcomes, we are able to model a value estimator and a policy generator for given states. By doing that, we build up a balancing mechanism between exploration and exploitation, speeding up the path planning process while maintaining its quality without using human expert driver data.
Integrating Higher-Order Dynamics and Roadway-Compliance into Constrained ILQR-based Trajectory Planning for Autonomous Vehicles
Sep 25, 2023



This paper addresses the advancements in on-road trajectory planning for Autonomous Passenger Vehicles (APV). Trajectory planning aims to produce a globally optimal route for APVs, considering various factors such as vehicle dynamics, constraints, and detected obstacles. Traditional techniques involve a combination of sampling methods followed by optimization algorithms, where the former ensures global awareness and the latter refines for local optima. Notably, the Constrained Iterative Linear Quadratic Regulator (CILQR) optimization algorithm has recently emerged, adapted for APV systems, emphasizing improved safety and comfort. However, existing implementations utilizing the vehicle bicycle kinematic model may not guarantee controllable trajectories. We augment this model by incorporating higher-order terms, including the first and second-order derivatives of curvature and longitudinal jerk. This inclusion facilitates a richer representation in our cost and constraint design. We also address roadway compliance, emphasizing adherence to lane boundaries and directions, which past work often overlooked. Lastly, we adopt a relaxed logarithmic barrier function to address the CILQR's dependency on feasible initial trajectories. The proposed methodology is then validated through simulation and real-world experiment driving scenes in real time.
Learning from Naturalistic Driving Data for Human-like Autonomous Highway Driving
May 23, 2020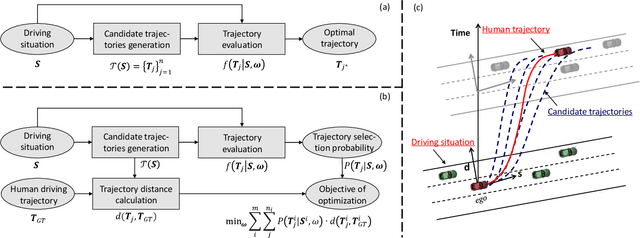
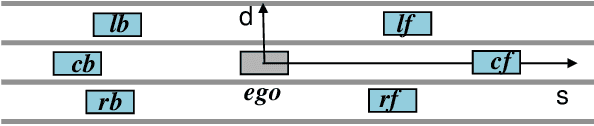

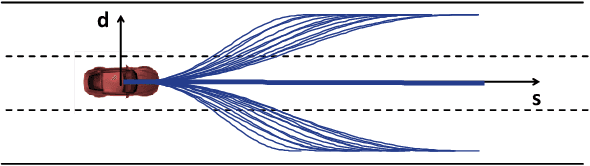
Driving in a human-like manner is important for an autonomous vehicle to be a smart and predictable traffic participant. To achieve this goal, parameters of the motion planning module should be carefully tuned, which needs great effort and expert knowledge. In this study, a method of learning cost parameters of a motion planner from naturalistic driving data is proposed. The learning is achieved by encouraging the selected trajectory to approximate the human driving trajectory under the same traffic situation. The employed motion planner follows a widely accepted methodology that first samples candidate trajectories in the trajectory space, then select the one with minimal cost as the planned trajectory. Moreover, in addition to traditional factors such as comfort, efficiency and safety, the cost function is proposed to incorporate incentive of behavior decision like a human driver, so that both lane change decision and motion planning are coupled into one framework. Two types of lane incentive cost -- heuristic and learning based -- are proposed and implemented. To verify the validity of the proposed method, a data set is developed by using the naturalistic trajectory data of human drivers collected on the motorways in Beijing, containing samples of lane changes to the left and right lanes, and car followings. Experiments are conducted with respect to both lane change decision and motion planning, and promising results are achieved.
Driver Identification through Stochastic Multi-State Car-Following Modeling
May 22, 2020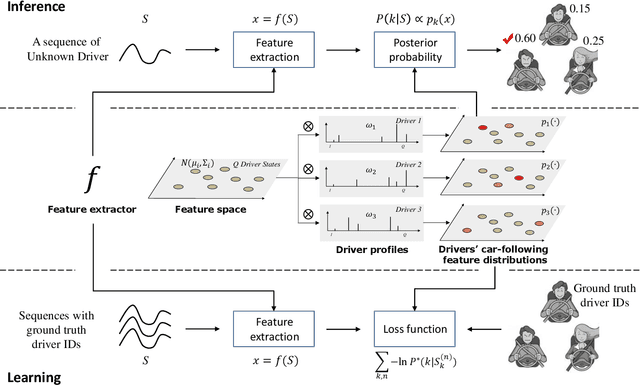
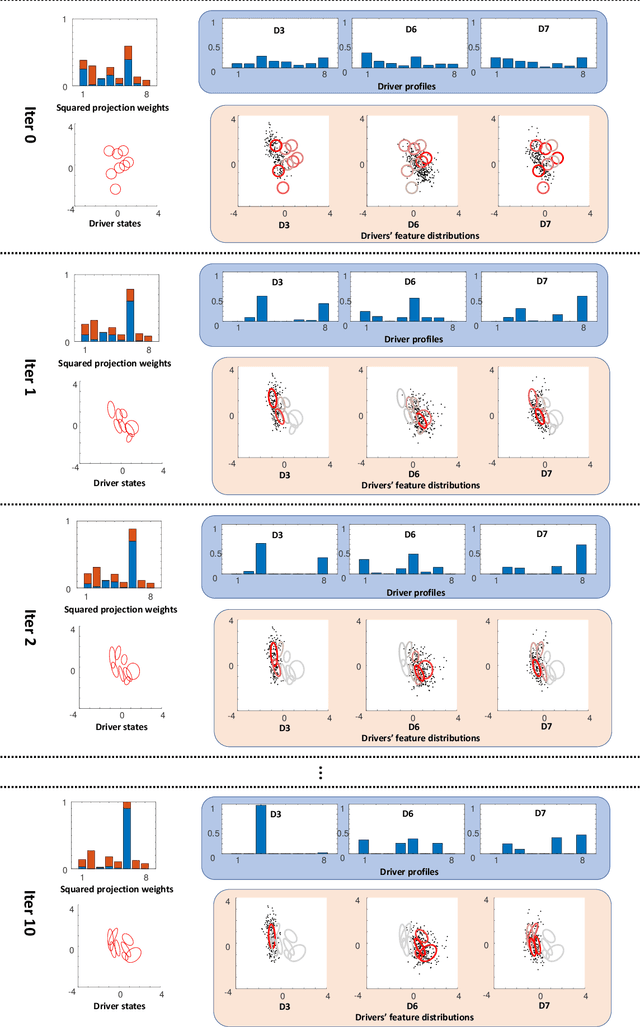
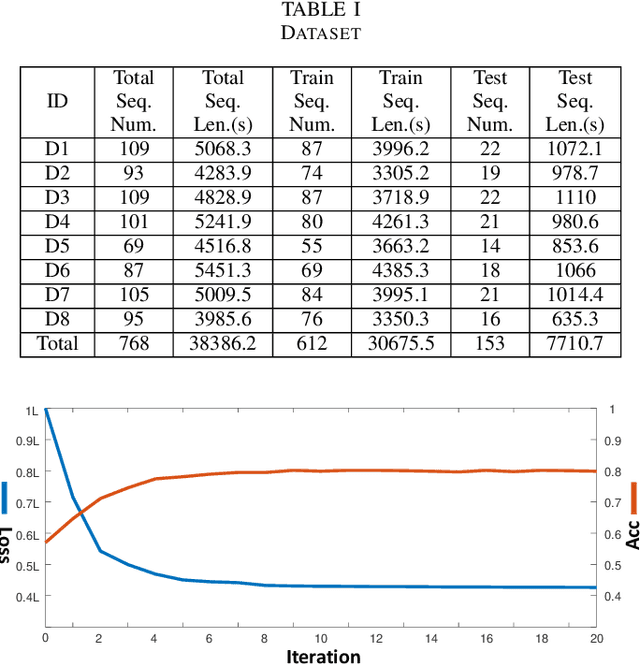
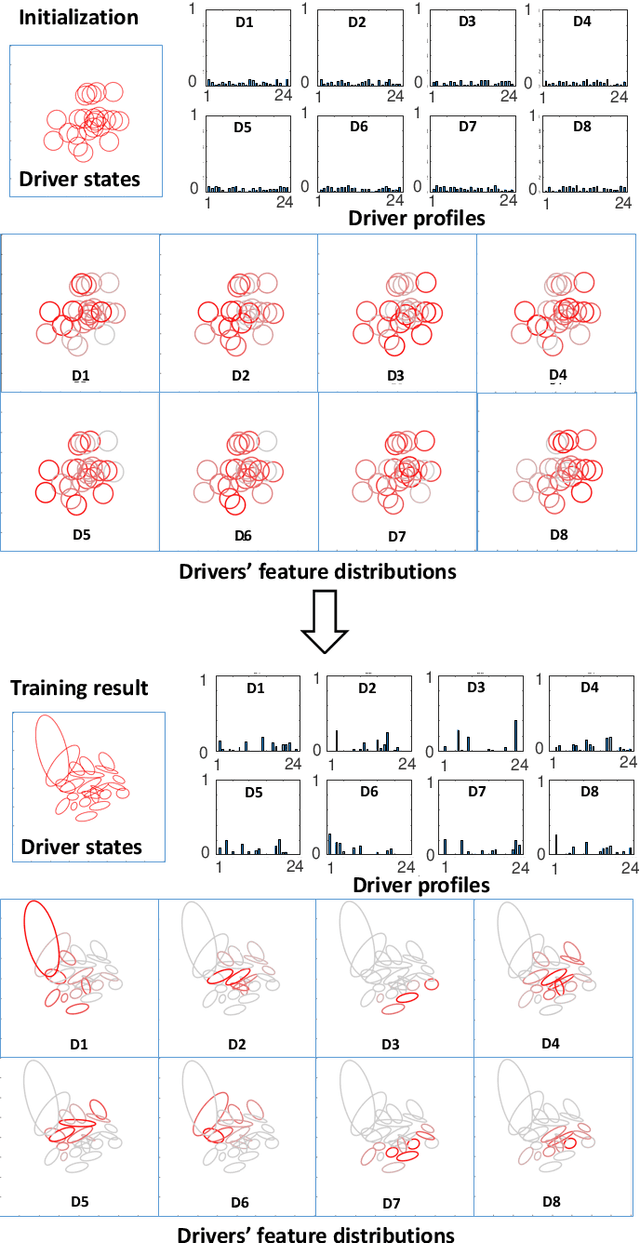
Intra-driver and inter-driver heterogeneity has been confirmed to exist in human driving behaviors by many studies. In this study, a joint model of the two types of heterogeneity in car-following behavior is proposed as an approach of driver profiling and identification. It is assumed that all drivers share a pool of driver states; under each state a car-following data sequence obeys a specific probability distribution in feature space; each driver has his/her own probability distribution over the states, called driver profile, which characterize the intradriver heterogeneity, while the difference between the driver profile of different drivers depict the inter-driver heterogeneity. Thus, the driver profile can be used to distinguish a driver from others. Based on the assumption, a stochastic car-following model is proposed to take both intra-driver and inter-driver heterogeneity into consideration, and a method is proposed to jointly learn parameters in behavioral feature extractor, driver states and driver profiles. Experiments demonstrate the performance of the proposed method in driver identification on naturalistic car-following data: accuracy of 82.3% is achieved in an 8-driver experiment using 10 car-following sequences of duration 15 seconds for online inference. The potential of fast registration of new drivers are demonstrated and discussed.
Cross Scene Prediction via Modeling Dynamic Correlation using Latent Space Shared Auto-Encoders
Mar 31, 2020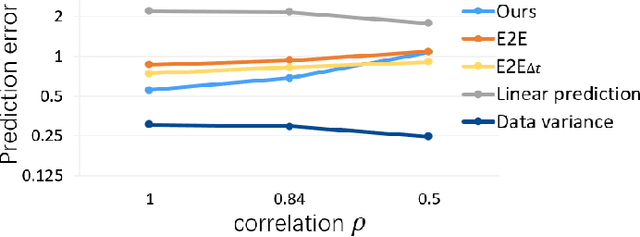
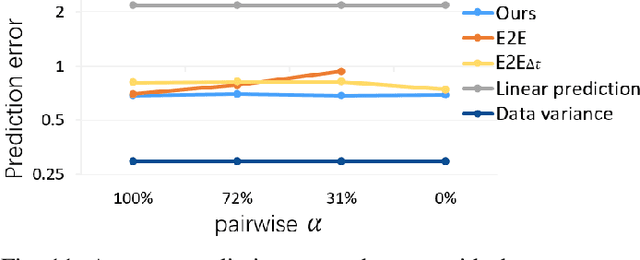
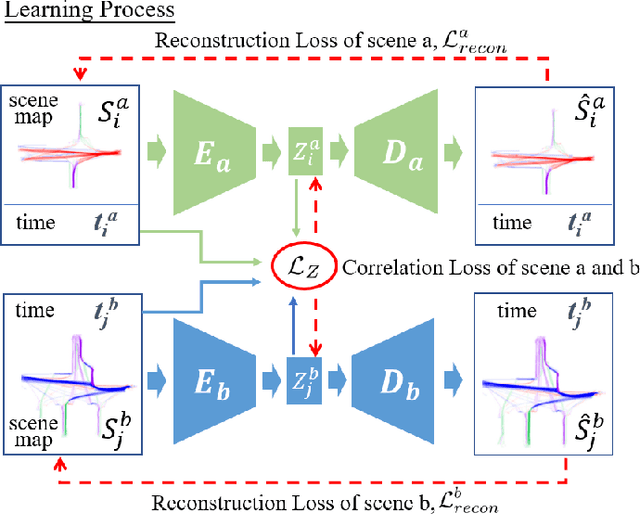
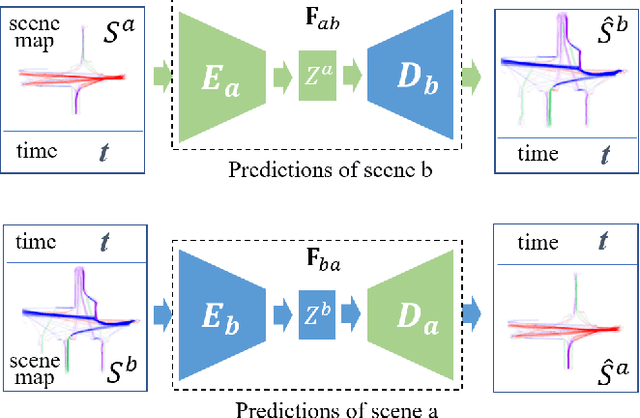
This work addresses on the following problem: given a set of unsynchronized history observations of two scenes that are correlative on their dynamic changes, the purpose is to learn a cross-scene predictor, so that with the observation of one scene, a robot can onlinely predict the dynamic state of another. A method is proposed to solve the problem via modeling dynamic correlation using latent space shared auto-encoders. Assuming that the inherent correlation of scene dynamics can be represented by shared latent space, where a common latent state is reached if the observations of both scenes are at an approximate time, a learning model is developed by connecting two auto-encoders through the latent space, and a prediction model is built by concatenating the encoder of the input scene with the decoder of the target one. Simulation datasets are generated imitating the dynamic flows at two adjacent gates of a campus, where the dynamic changes are triggered by a common working and teaching schedule. Similar scenarios can also be found at successive intersections on a single road, gates of a subway station, etc. Accuracy of cross-scene prediction is examined at various conditions of scene correlation and pairwise observations. Potentials of the proposed method are demonstrated by comparing with conventional end-to-end methods and linear predictions.
Scene-Aware Error Modeling of LiDAR/Visual Odometry for Fusion-based Vehicle Localization
Mar 29, 2020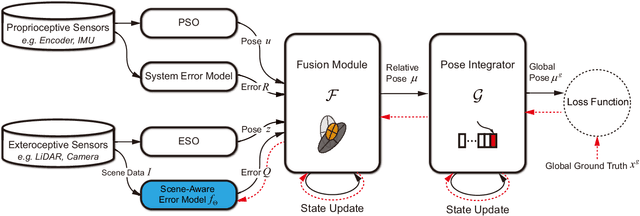
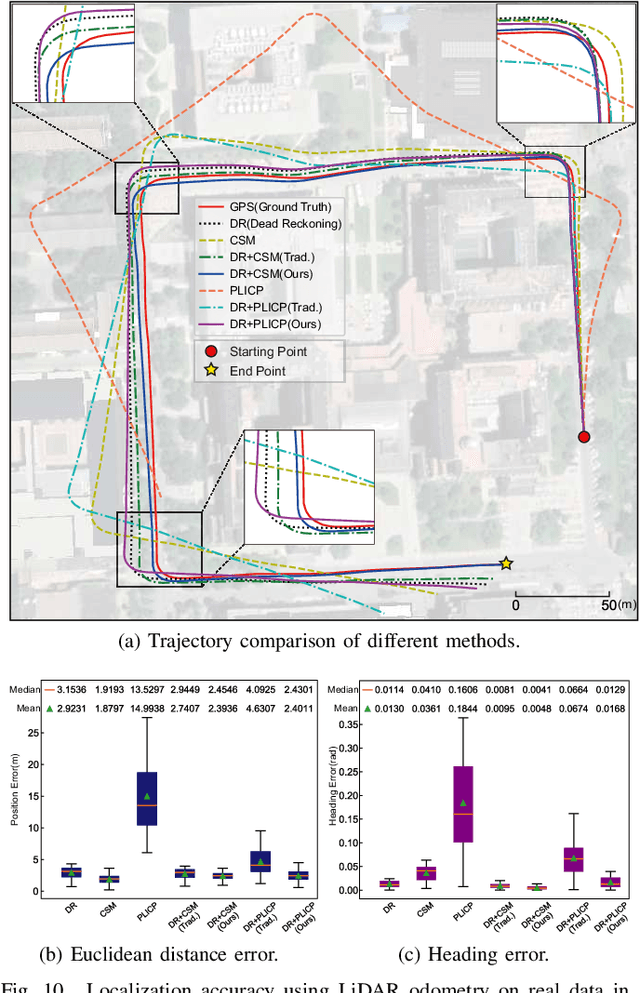
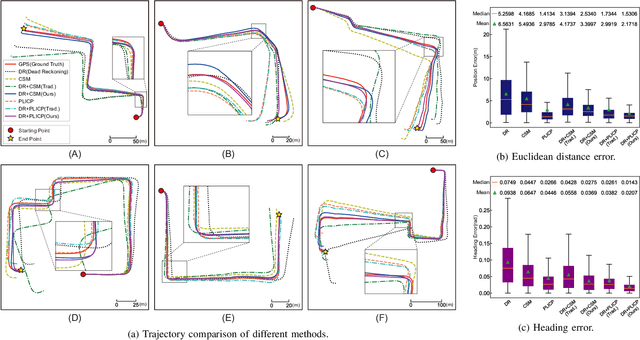
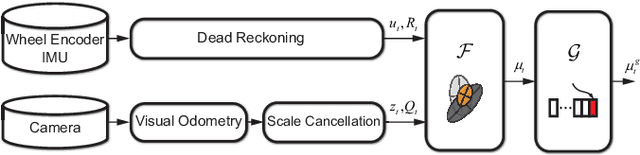
Localization is an essential technique in mobile robotics. In a complex environment, it is necessary to fuse different localization modules to obtain more robust results, in which the error model plays a paramount role. However, exteroceptive sensor-based odometries (ESOs), such as LiDAR/visual odometry, often deliver results with scene-related error, which is difficult to model accurately. To address this problem, this research designs a scene-aware error model for ESO, based on which a multimodal localization fusion framework is developed. In addition, an end-to-end learning method is proposed to train this error model using sparse global poses such as GPS/IMU results. The proposed method is realized for error modeling of LiDAR/visual odometry, and the results are fused with dead reckoning to examine the performance of vehicle localization. Experiments are conducted using both simulation and real-world data of experienced and unexperienced environments, and the experimental results demonstrate that with the learned scene-aware error models, vehicle localization accuracy can be largely improved and shows adaptiveness in unexperienced scenes.
Off-road Autonomous Vehicles Traversability Analysis and Trajectory Planning Based on Deep Inverse Reinforcement Learning
Sep 16, 2019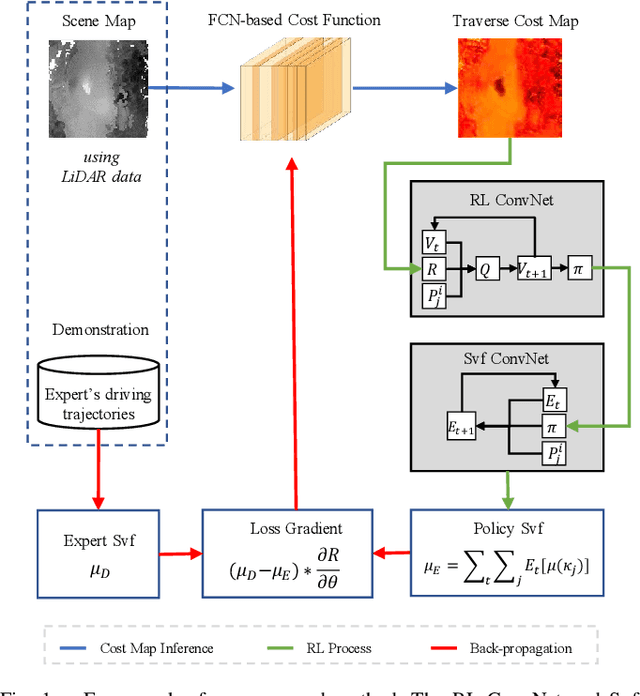
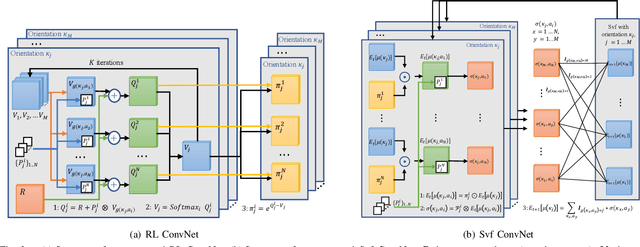

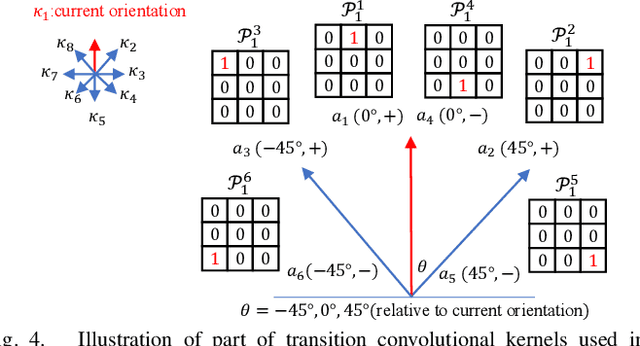
Terrain traversability analysis is a fundamental issue to achieve the autonomy of a robot at off-road environments. Geometry-based and appearance-based methods have been studied in decades, while behavior-based methods exploiting learning from demonstration (LfD) are new trends. Behavior-based methods learn cost functions that guide trajectory planning in compliance with experts' demonstrations, which can be more scalable to various scenes and driving behaviors. This research proposes a method of off-road traversability analysis and trajectory planning using Deep Maximum Entropy Inverse Reinforcement Learning. To incorporate vehicle's kinematics while solving the problem of exponential increase of state-space complexity, two convolutional neural networks, i.e., RL ConvNet and Svf ConvNet, are developed to encode kinematics into convolution kernels and achieve efficient forward reinforcement learning. We conduct experiments in off-road environments. Scene maps are generated using 3D LiDAR data, and expert demonstrations are either the vehicle's real driving trajectories at the scene or synthesized ones to represent specific behaviors such as crossing negative obstacles. Four cost functions of traversability analysis are learned and tested at various scenes of capability in guiding the trajectory planning of different behaviors. We also demonstrate the computation efficiency of the proposed method.
Semantic Segmentation of 3D LiDAR Data in Dynamic Scene Using Semi-supervised Learning
Sep 03, 2018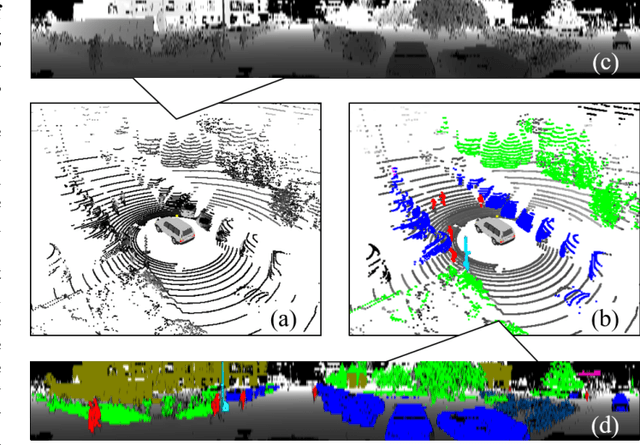
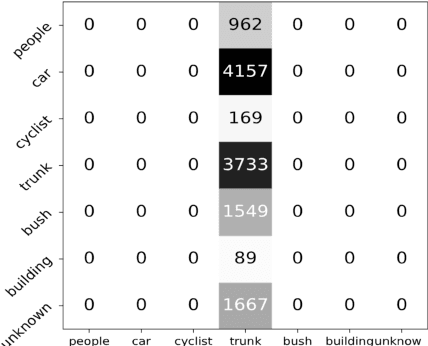
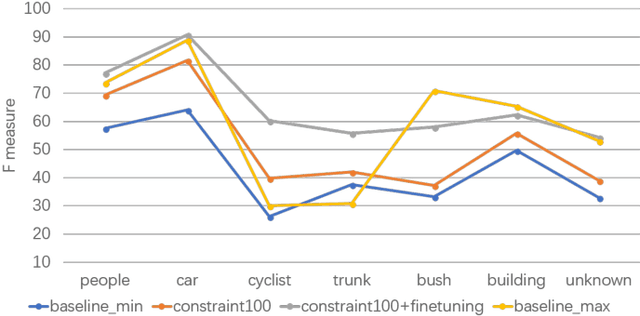

This work studies the semantic segmentation of 3D LiDAR data in dynamic scenes for autonomous driving applications. A system of semantic segmentation using 3D LiDAR data, including range image segmentation, sample generation, inter-frame data association, track-level annotation and semi-supervised learning, is developed. To reduce the considerable requirement of fine annotations, a CNN-based classifier is trained by considering both supervised samples with manually labeled object classes and pairwise constraints, where a data sample is composed of a segment as the foreground and neighborhood points as the background. A special loss function is designed to account for both annotations and constraints, where the constraint data are encouraged to be assigned to the same semantic class. A dataset containing 1838 frames of LiDAR data, 39934 pairwise constraints and 57927 human annotations is developed. The performance of the method is examined extensively. Qualitative and quantitative experiments show that the combination of a few annotations and large amount of constraint data significantly enhances the effectiveness and scene adaptability, resulting in greater than 10% improvement