 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Apr 20, 2026Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
DALI: A Workload-Aware Offloading Framework for Efficient MoE Inference on Local PCs
Feb 03, 2026Mixture of Experts (MoE) architectures significantly enhance the capacity of LLMs without proportional increases in computation, but at the cost of a vast parameter size. Offloading MoE expert parameters to host memory and leveraging both CPU and GPU computation has recently emerged as a promising direction to support such models on resourceconstrained local PC platforms. While promising, we notice that existing approaches mismatch the dynamic nature of expert workloads, which leads to three fundamental inefficiencies: (1) Static expert assignment causes severe CPUGPU load imbalance, underutilizing CPU and GPU resources; (2) Existing prefetching techniques fail to accurately predict high-workload experts, leading to costly inaccurate prefetches; (3) GPU cache policies neglect workload dynamics, resulting in poor hit rates and limited effectiveness. To address these challenges, we propose DALI, a workloaDAware offLoadIng framework for efficient MoE inference on local PCs. To fully utilize hardware resources, DALI first dynamically assigns experts to CPU or GPU by modeling assignment as a 0-1 integer optimization problem and solving it efficiently using a Greedy Assignment strategy at runtime. To improve prefetching accuracy, we develop a Residual-Based Prefetching method leveraging inter-layer residual information to accurately predict high-workload experts. Additionally, we introduce a Workload-Aware Cache Replacement policy that exploits temporal correlation in expert activations to improve GPU cache efficiency. By evaluating across various MoE models and settings, DALI achieves significant speedups in the both prefill and decoding phases over the state-of-the-art offloading frameworks.
WenetSpeech-Wu: Datasets, Benchmarks, and Models for a Unified Chinese Wu Dialect Speech Processing Ecosystem
Jan 16, 2026Speech processing for low-resource dialects remains a fundamental challenge in developing inclusive and robust speech technologies. Despite its linguistic significance and large speaker population, the Wu dialect of Chinese has long been hindered by the lack of large-scale speech data, standardized evaluation benchmarks, and publicly available models. In this work, we present WenetSpeech-Wu, the first large-scale, multi-dimensionally annotated open-source speech corpus for the Wu dialect, comprising approximately 8,000 hours of diverse speech data. Building upon this dataset, we introduce WenetSpeech-Wu-Bench, the first standardized and publicly accessible benchmark for systematic evaluation of Wu dialect speech processing, covering automatic speech recognition (ASR), Wu-to-Mandarin translation, speaker attribute prediction, speech emotion recognition, text-to-speech (TTS) synthesis, and instruction-following TTS (instruct TTS). Furthermore, we release a suite of strong open-source models trained on WenetSpeech-Wu, establishing competitive performance across multiple tasks and empirically validating the effectiveness of the proposed dataset. Together, these contributions lay the foundation for a comprehensive Wu dialect speech processing ecosystem, and we open-source proposed datasets, benchmarks, and models to support future research on dialectal speech intelligence.
Paper2Video: Automatic Video Generation from Scientific Papers
Oct 06, 2025Academic presentation videos have become an essential medium for research communication, yet producing them remains highly labor-intensive, often requiring hours of slide design, recording, and editing for a short 2 to 10 minutes video. Unlike natural video, presentation video generation involves distinctive challenges: inputs from research papers, dense multi-modal information (text, figures, tables), and the need to coordinate multiple aligned channels such as slides, subtitles, speech, and human talker. To address these challenges, we introduce PaperTalker, the first benchmark of 101 research papers paired with author-created presentation videos, slides, and speaker metadata. We further design four tailored evaluation metrics--Meta Similarity, PresentArena, PresentQuiz, and IP Memory--to measure how videos convey the paper's information to the audience. Building on this foundation, we propose PaperTalker, the first multi-agent framework for academic presentation video generation. It integrates slide generation with effective layout refinement by a novel effective tree search visual choice, cursor grounding, subtitling, speech synthesis, and talking-head rendering, while parallelizing slide-wise generation for efficiency. Experiments on Paper2Video demonstrate that the presentation videos produced by our approach are more faithful and informative than existing baselines, establishing a practical step toward automated and ready-to-use academic video generation. Our dataset, agent, and code are available at https://github.com/showlab/Paper2Video.
Automated Movie Generation via Multi-Agent CoT Planning
Mar 10, 2025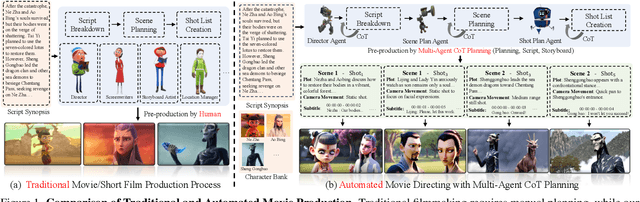
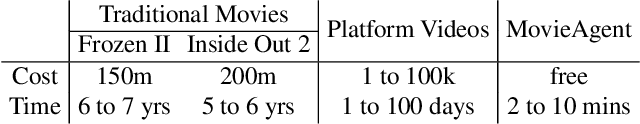
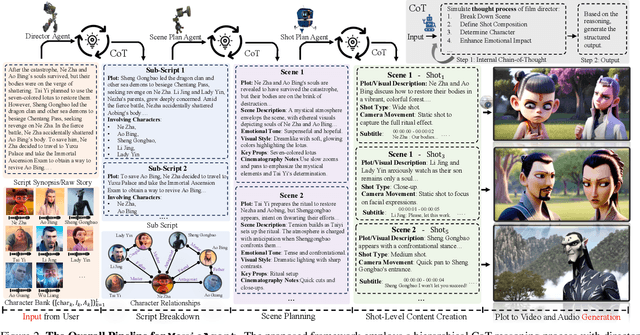
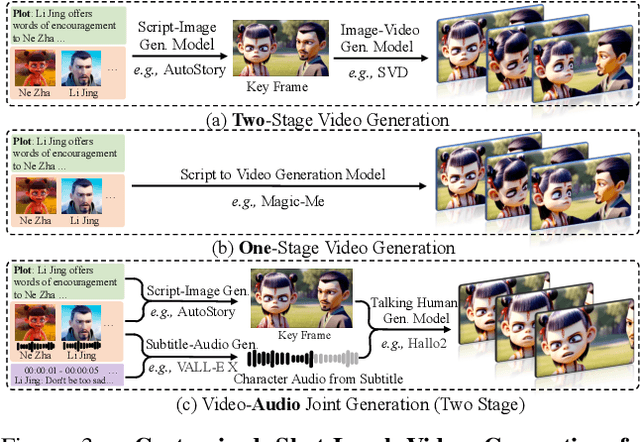
Existing long-form video generation frameworks lack automated planning, requiring manual input for storylines, scenes, cinematography, and character interactions, resulting in high costs and inefficiencies. To address these challenges, we present MovieAgent, an automated movie generation via multi-agent Chain of Thought (CoT) planning. MovieAgent offers two key advantages: 1) We firstly explore and define the paradigm of automated movie/long-video generation. Given a script and character bank, our MovieAgent can generates multi-scene, multi-shot long-form videos with a coherent narrative, while ensuring character consistency, synchronized subtitles, and stable audio throughout the film. 2) MovieAgent introduces a hierarchical CoT-based reasoning process to automatically structure scenes, camera settings, and cinematography, significantly reducing human effort. By employing multiple LLM agents to simulate the roles of a director, screenwriter, storyboard artist, and location manager, MovieAgent streamlines the production pipeline. Experiments demonstrate that MovieAgent achieves new state-of-the-art results in script faithfulness, character consistency, and narrative coherence. Our hierarchical framework takes a step forward and provides new insights into fully automated movie generation. The code and project website are available at: https://github.com/showlab/MovieAgent and https://weijiawu.github.io/MovieAgent.
MovieBench: A Hierarchical Movie Level Dataset for Long Video Generation
Nov 22, 2024



Recent advancements in video generation models, like Stable Video Diffusion, show promising results, but primarily focus on short, single-scene videos. These models struggle with generating long videos that involve multiple scenes, coherent narratives, and consistent characters. Furthermore, there is no publicly available dataset tailored for the analysis, evaluation, and training of long video generation models. In this paper, we present MovieBench: A Hierarchical Movie-Level Dataset for Long Video Generation, which addresses these challenges by providing unique contributions: (1) movie-length videos featuring rich, coherent storylines and multi-scene narratives, (2) consistency of character appearance and audio across scenes, and (3) hierarchical data structure contains high-level movie information and detailed shot-level descriptions. Experiments demonstrate that MovieBench brings some new insights and challenges, such as maintaining character ID consistency across multiple scenes for various characters. The dataset will be public and continuously maintained, aiming to advance the field of long video generation. Data can be found at: https://weijiawu.github.io/MovieBench/.
TernaryLLM: Ternarized Large Language Model
Jun 11, 2024
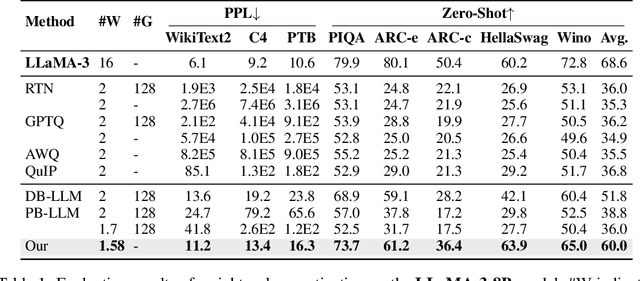

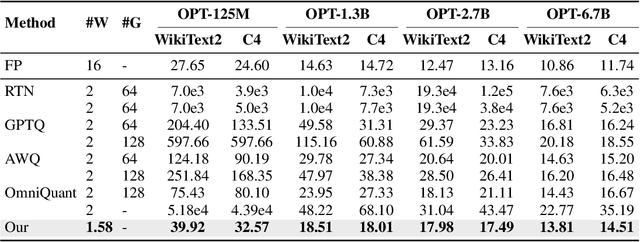
Large language models (LLMs) have achieved remarkable performance on Natural Language Processing (NLP) tasks, but they are hindered by high computational costs and memory requirements. Ternarization, an extreme form of quantization, offers a solution by reducing memory usage and enabling energy-efficient floating-point additions. However, applying ternarization to LLMs faces challenges stemming from outliers in both weights and activations. In this work, observing asymmetric outliers and non-zero means in weights, we introduce Dual Learnable Ternarization (DLT), which enables both scales and shifts to be learnable. We also propose Outlier-Friendly Feature Knowledge Distillation (OFF) to recover the information lost in extremely low-bit quantization. The proposed OFF can incorporate semantic information and is insensitive to outliers. At the core of OFF is maximizing the mutual information between features in ternarized and floating-point models using cosine similarity. Extensive experiments demonstrate that our TernaryLLM surpasses previous low-bit quantization methods on the standard text generation and zero-shot benchmarks for different LLM families. Specifically, for one of the most powerful open-source models, LLaMA-3, our approach (W1.58A16) outperforms the previous state-of-the-art method (W2A16) by 5.8 in terms of perplexity on C4 and by 8.2% in terms of average accuracy on zero-shot tasks.
MEGA: A Memory-Efficient GNN Accelerator Exploiting Degree-Aware Mixed-Precision Quantization
Nov 16, 2023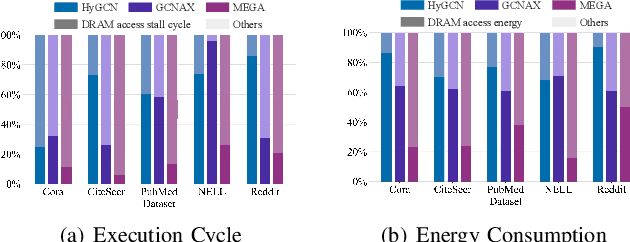
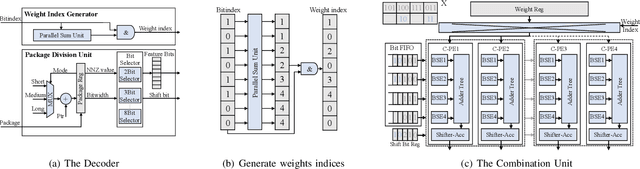
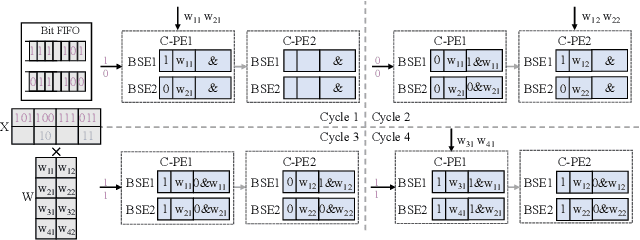

Graph Neural Networks (GNNs) are becoming a promising technique in various domains due to their excellent capabilities in modeling non-Euclidean data. Although a spectrum of accelerators has been proposed to accelerate the inference of GNNs, our analysis demonstrates that the latency and energy consumption induced by DRAM access still significantly impedes the improvement of performance and energy efficiency. To address this issue, we propose a Memory-Efficient GNN Accelerator (MEGA) through algorithm and hardware co-design in this work. Specifically, at the algorithm level, through an in-depth analysis of the node property, we observe that the data-independent quantization in previous works is not optimal in terms of accuracy and memory efficiency. This motivates us to propose the Degree-Aware mixed-precision quantization method, in which a proper bitwidth is learned and allocated to a node according to its in-degree to compress GNNs as much as possible while maintaining accuracy. At the hardware level, we employ a heterogeneous architecture design in which the aggregation and combination phases are implemented separately with different dataflows. In order to boost the performance and energy efficiency, we also present an Adaptive-Package format to alleviate the storage overhead caused by the fine-grained bitwidth and diverse sparsity, and a Condense-Edge scheduling method to enhance the data locality and further alleviate the access irregularity induced by the extremely sparse adjacency matrix in the graph. We implement our MEGA accelerator in a 28nm technology node. Extensive experiments demonstrate that MEGA can achieve an average speedup of 38.3x, 7.1x, 4.0x, 3.6x and 47.6x, 7.2x, 5.4x, 4.5x energy savings over four state-of-the-art GNN accelerators, HyGCN, GCNAX, GROW, and SGCN, respectively, while retaining task accuracy.
Spiking NeRF: Making Bio-inspired Neural Networks See through the Real World
Sep 20, 2023



Spiking neuron networks (SNNs) have been thriving on numerous tasks to leverage their promising energy efficiency and exploit their potentialities as biologically plausible intelligence. Meanwhile, the Neural Radiance Fields (NeRF) render high-quality 3D scenes with massive energy consumption, and few works delve into the energy-saving solution with a bio-inspired approach. In this paper, we propose spiking NeRF (SpikingNeRF), which aligns the radiance ray with the temporal dimension of SNN, to naturally accommodate the SNN to the reconstruction of Radiance Fields. Thus, the computation turns into a spike-based, multiplication-free manner, reducing the energy consumption. In SpikingNeRF, each sampled point on the ray is matched onto a particular time step, and represented in a hybrid manner where the voxel grids are maintained as well. Based on the voxel grids, sampled points are determined whether to be masked for better training and inference. However, this operation also incurs irregular temporal length. We propose the temporal condensing-and-padding (TCP) strategy to tackle the masked samples to maintain regular temporal length, i.e., regular tensors, for hardware-friendly computation. Extensive experiments on a variety of datasets demonstrate that our method reduces the $76.74\%$ energy consumption on average and obtains comparable synthesis quality with the ANN baseline.
Unsupervised Pansharpening via Low-rank Diffusion Model
May 18, 2023



Pansharpening is a process of merging a highresolution panchromatic (PAN) image and a low-resolution multispectral (LRMS) image to create a single high-resolution multispectral (HRMS) image. Most of the existing deep learningbased pansharpening methods have poor generalization ability and the traditional model-based pansharpening methods need careful manual exploration for the image structure prior. To alleviate these issues, this paper proposes an unsupervised pansharpening method by combining the diffusion model with the low-rank matrix factorization technique. Specifically, we assume that the HRMS image is decomposed into the product of two low-rank tensors, i.e., the base tensor and the coefficient matrix. The base tensor lies on the image field and has low spectral dimension, we can thus conveniently utilize a pre-trained remote sensing diffusion model to capture its image structures. Additionally, we derive a simple yet quite effective way to preestimate the coefficient matrix from the observed LRMS image, which preserves the spectral information of the HRMS. Extensive experimental results on some benchmark datasets demonstrate that our proposed method performs better than traditional model-based approaches and has better generalization ability than deep learning-based techniques. The code is released in https://github.com/xyrui/PLRDiff.