 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical Example Mining for Vehicle Trajectory Prediction using Flow-based Generative Models
Oct 21, 2024



Precise trajectory prediction in complex driving scenarios is essential for autonomous vehicles. In practice, different driving scenarios present varying levels of difficulty for trajectory prediction models. However, most existing research focuses on the average precision of prediction results, while ignoring the underlying distribution of the input scenarios. This paper proposes a critical example mining method that utilizes a data-driven approach to estimate the rareness of the trajectories. By combining the rareness estimation of observations with whole trajectories, the proposed method effectively identifies a subset of data that is relatively hard to predict BEFORE feeding them to a specific prediction model. The experimental results show that the mined subset has higher prediction error when applied to different downstream prediction models, which reaches +108.1% error (greater than two times compared to the average on dataset) when mining 5% samples. Further analysis indicates that the mined critical examples include uncommon cases such as sudden brake and cancelled lane-change, which helps to better understand and improve the performance of prediction models.
Understanding the Challenges When 3D Semantic Segmentation Faces Class Imbalanced and OOD Data
Mar 01, 2022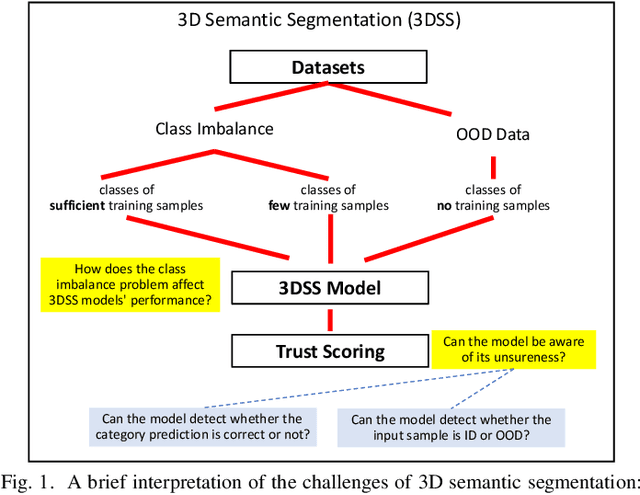

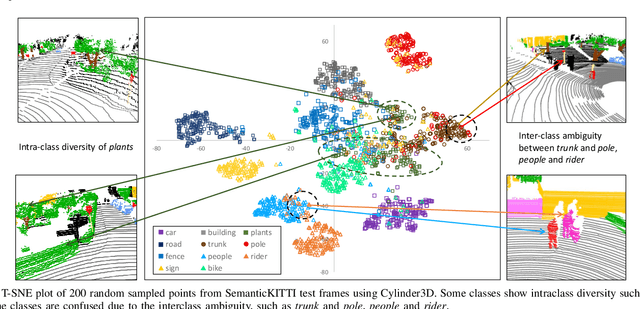

3D semantic segmentation (3DSS) is an essential process in the creation of a safe autonomous driving system. However, deep learning models for 3D semantic segmentation often suffer from the class imbalance problem and out-of-distribution (OOD) data. In this study, we explore how the class imbalance problem affects 3DSS performance and whether the model can detect the category prediction correctness, or whether data is ID (in-distribution) or OOD. For these purposes, we conduct two experiments using three representative 3DSS models and five trust scoring methods, and conduct both a confusion and feature analysis of each class. Furthermore, a data augmentation method for the 3D LiDAR dataset is proposed to create a new dataset based on SemanticKITTI and SemanticPOSS, called AugKITTI. We propose the wPre metric and TSD for a more in-depth analysis of the results, and follow are proposals with an insightful discussion. Based on the experimental results, we find that: (1) the classes are not only imbalanced in their data size but also in the basic properties of each semantic category. (2) The intraclass diversity and interclass ambiguity make class learning difficult and greatly limit the models' performance, creating the challenges of semantic and data gaps. (3) The trust scores are unreliable for classes whose features are confused with other classes. For 3DSS models, those misclassified ID classes and OODs may also be given high trust scores, making the 3DSS predictions unreliable, and leading to the challenges in judging 3DSS result trustworthiness. All of these outcomes point to several research directions for improving the performance and reliability of the 3DSS models used for real-world applications.
Multi-Task Conditional Imitation Learning for Autonomous Navigation at Crowded Intersections
Feb 21, 2022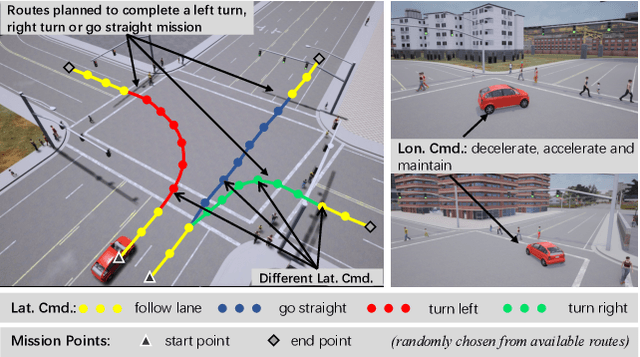
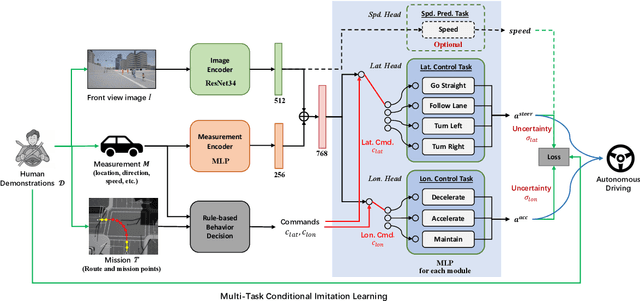
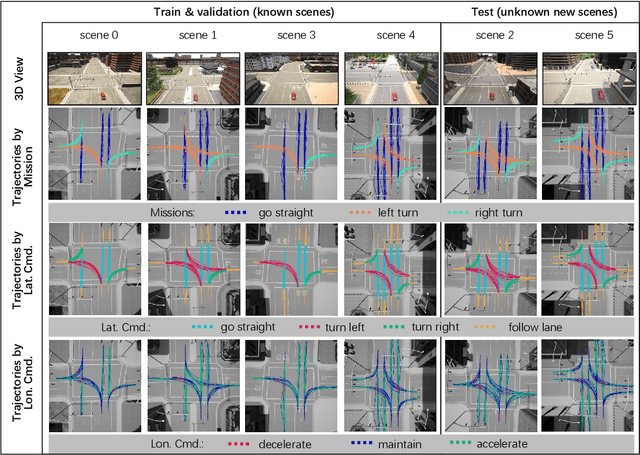
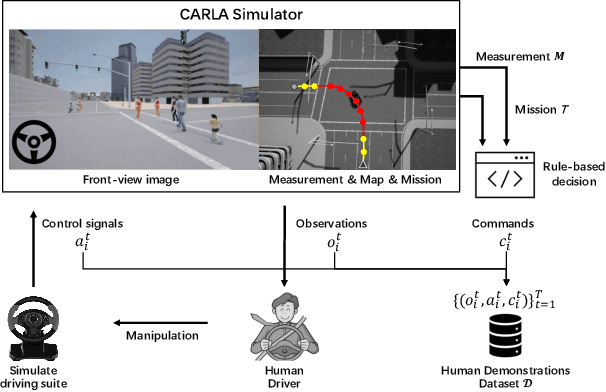
In recent years, great efforts have been devoted to deep imitation learning for autonomous driving control, where raw sensory inputs are directly mapped to control actions. However, navigating through densely populated intersections remains a challenging task due to uncertainty caused by uncertain traffic participants. We focus on autonomous navigation at crowded intersections that require interaction with pedestrians. A multi-task conditional imitation learning framework is proposed to adapt both lateral and longitudinal control tasks for safe and efficient interaction. A new benchmark called IntersectNav is developed and human demonstrations are provided. Empirical results show that the proposed method can achieve a success rate gain of up to 30% compared to the state-of-the-art.
An Active and Contrastive Learning Framework for Fine-Grained Off-Road Semantic Segmentation
Feb 18, 2022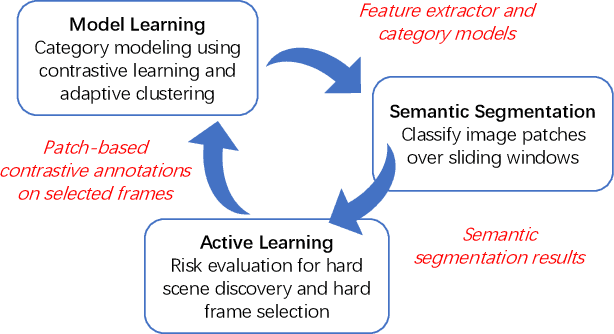
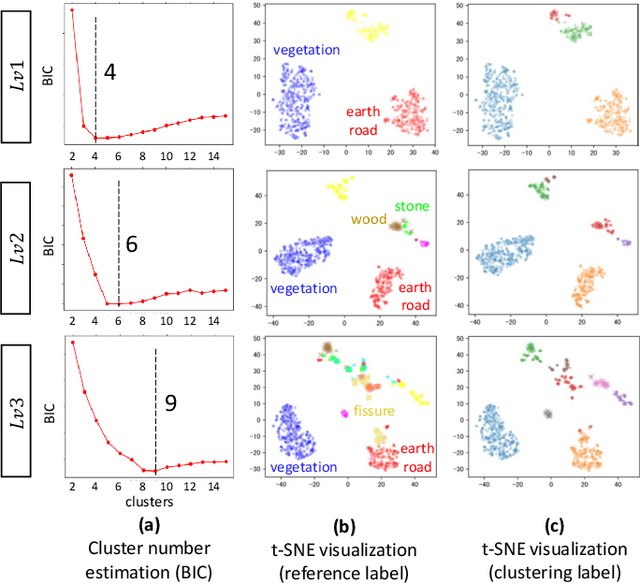
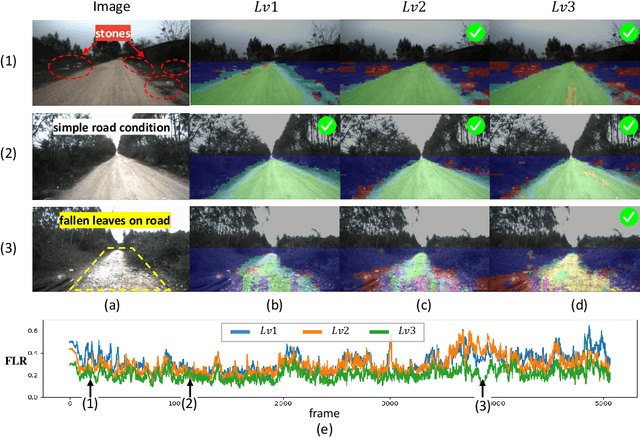
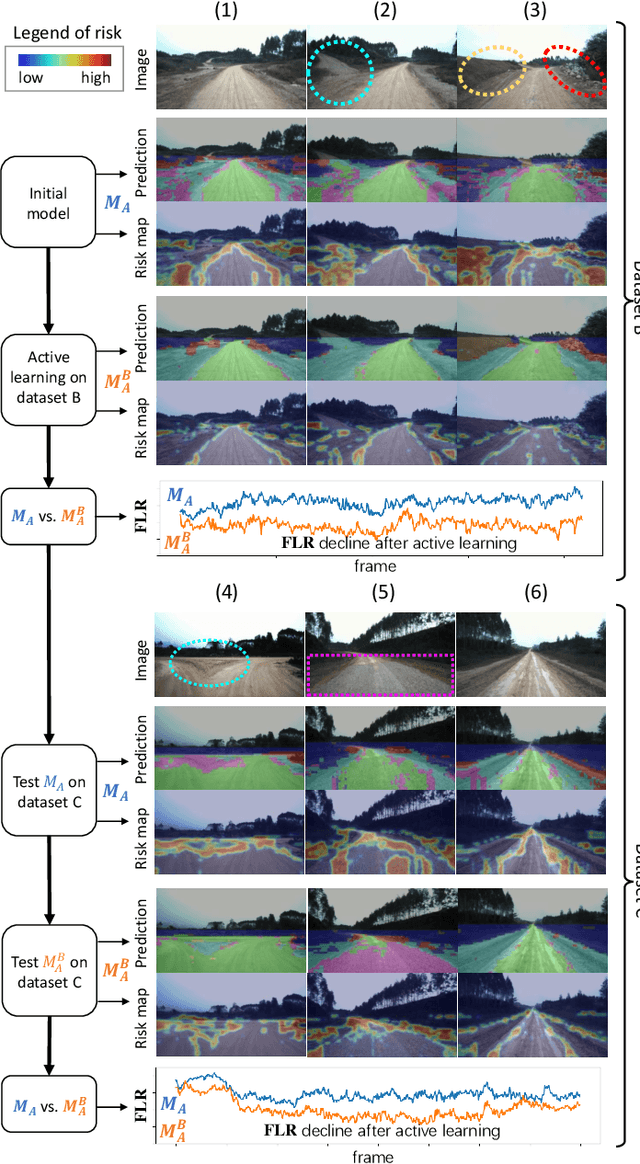
Off-road semantic segmentation with fine-grained labels is necessary for autonomous vehicles to understand driving scenes, as the coarse-grained road detection can not satisfy off-road vehicles with various mechanical properties. Fine-grained semantic segmentation in off-road scenes usually has no unified category definition due to ambiguous nature environments, and the cost of pixel-wise labeling is extremely high. Furthermore, semantic properties of off-road scenes can be very changeable due to various precipitations, temperature, defoliation, etc. To address these challenges, this research proposes an active and contrastive learning-based method that does not rely on pixel-wise labels, but only on patch-based weak annotations for model learning. There is no need for predefined semantic categories, the contrastive learning-based feature representation and adaptive clustering will discover the category model from scene data. In order to actively adapt to new scenes, a risk evaluation method is proposed to discover and select hard frames with high-risk predictions for supplemental labeling, so as to update the model efficiently. Experiments conducted on our self-developed off-road dataset and DeepScene dataset demonstrate that fine-grained semantic segmentation can be learned with only dozens of weakly labeled frames, and the model can efficiently adapt across scenes by weak supervision, while achieving almost the same level of performance as typical fully supervised baselines.
An Image-based Approach of Task-driven Driving Scene Categorization
Mar 10, 2021

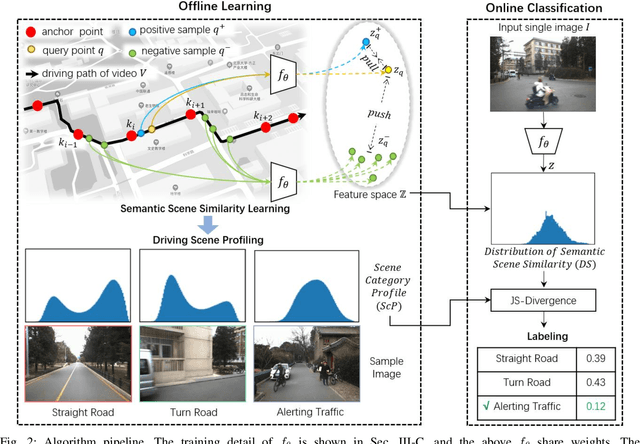
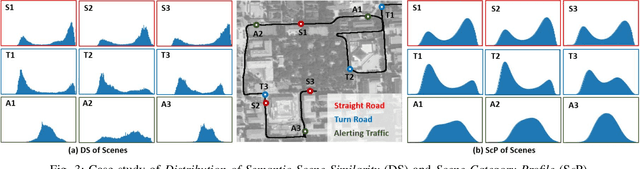
Categorizing driving scenes via visual perception is a key technology for safe driving and the downstream tasks of autonomous vehicles. Traditional methods infer scene category by detecting scene-related objects or using a classifier that is trained on large datasets of fine-labeled scene images. Whereas at cluttered dynamic scenes such as campus or park, human activities are not strongly confined by rules, and the functional attributes of places are not strongly correlated with objects. So how to define, model and infer scene categories is crucial to make the technique really helpful in assisting a robot to pass through the scene. This paper proposes a method of task-driven driving scene categorization using weakly supervised data. Given a front-view video of a driving scene, a set of anchor points is marked by following the decision making of a human driver, where an anchor point is not a semantic label but an indicator meaning the semantic attribute of the scene is different from that of the previous one. A measure is learned to discriminate the scenes of different semantic attributes via contrastive learning, and a driving scene profiling and categorization method is developed based on that measure. Experiments are conducted on a front-view video that is recorded when a vehicle passed through the cluttered dynamic campus of Peking University. The scenes are categorized into straight road, turn road and alerting traffic. The results of semantic scene similarity learning and driving scene categorization are extensively studied, and positive result of scene categorization is 97.17 \% on the learning video and 85.44\% on the video of new scenes.
Fine-Grained Off-Road Semantic Segmentation and Mapping via Contrastive Learning
Mar 05, 2021


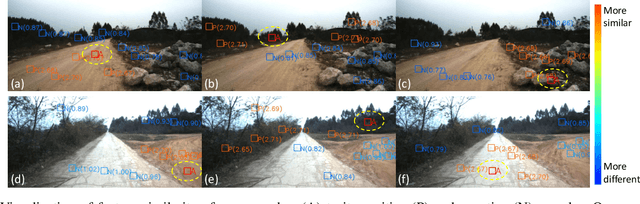
Road detection or traversability analysis has been a key technique for a mobile robot to traverse complex off-road scenes. The problem has been mainly formulated in early works as a binary classification one, e.g. associating pixels with road or non-road labels. Whereas understanding scenes with fine-grained labels are needed for off-road robots, as scenes are very diverse, and the various mechanical performance of off-road robots may lead to different definitions of safe regions to traverse. How to define and annotate fine-grained labels to achieve meaningful scene understanding for a robot to traverse off-road is still an open question. This research proposes a contrastive learning based method. With a set of human-annotated anchor patches, a feature representation is learned to discriminate regions with different traversability, a method of fine-grained semantic segmentation and mapping is subsequently developed for off-road scene understanding. Experiments are conducted on a dataset of three driving segments that represent very diverse off-road scenes. An anchor accuracy of 89.8% is achieved by evaluating the matching with human-annotated image patches in cross-scene validation. Examined by associated 3D LiDAR data, the fine-grained segments of visual images are demonstrated to have different levels of toughness and terrain elevation, which represents their semantical meaningfulness. The resultant maps contain both fine-grained labels and confidence values, providing rich information to support a robot traversing complex off-road scenes.
A Survey of Deep RL and IL for Autonomous Driving Policy Learning
Jan 06, 2021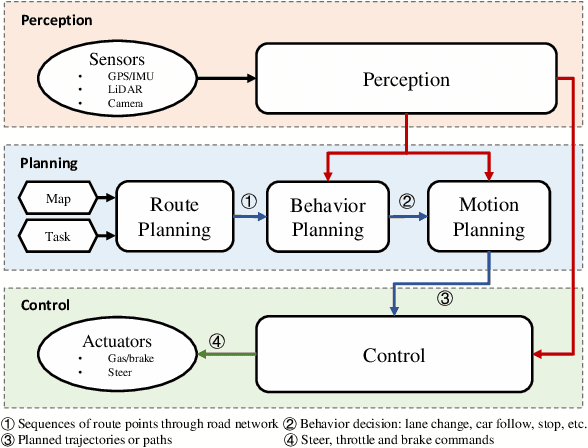
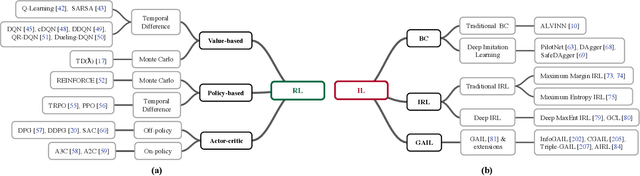
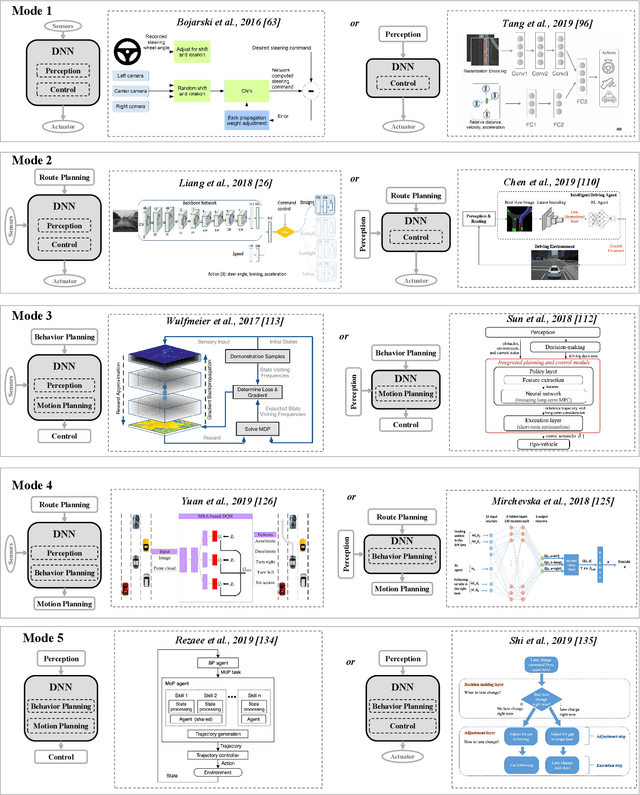
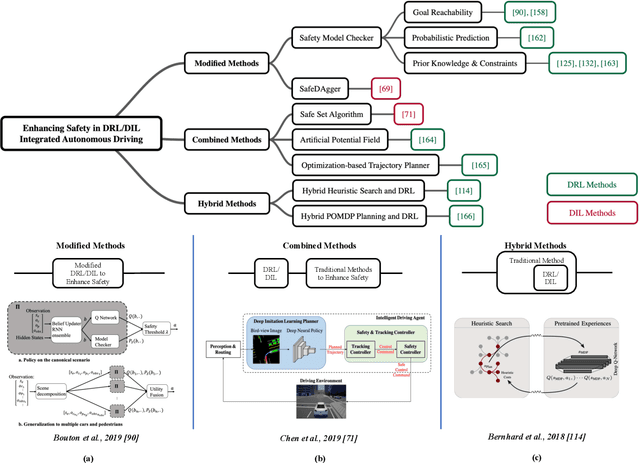
Autonomous driving (AD) agents generate driving policies based on online perception results, which are obtained at multiple levels of abstraction, e.g., behavior planning, motion planning and control. Driving policies are crucial to the realization of safe, efficient and harmonious driving behaviors, where AD agents still face substantial challenges in complex scenarios. Due to their successful application in fields such as robotics and video games, the use of deep reinforcement learning (DRL) and deep imitation learning (DIL) techniques to derive AD policies have witnessed vast research efforts in recent years. This paper is a comprehensive survey of this body of work, which is conducted at three levels: First, a taxonomy of the literature studies is constructed from the system perspective, among which five modes of integration of DRL/DIL models into an AD architecture are identified. Second, the formulations of DRL/DIL models for conducting specified AD tasks are comprehensively reviewed, where various designs on the model state and action spaces and the reinforcement learning rewards are covered. Finally, an in-depth review is conducted on how the critical issues of AD applications regarding driving safety, interaction with other traffic participants and uncertainty of the environment are addressed by the DRL/DIL models. To the best of our knowledge, this is the first survey to focus on AD policy learning using DRL/DIL, which is addressed simultaneously from the system, task-driven and problem-driven perspectives. We share and discuss findings, which may lead to the investigation of various topics in the future.
Are We Hungry for 3D LiDAR Data for Semantic Segmentation?
Jun 08, 2020
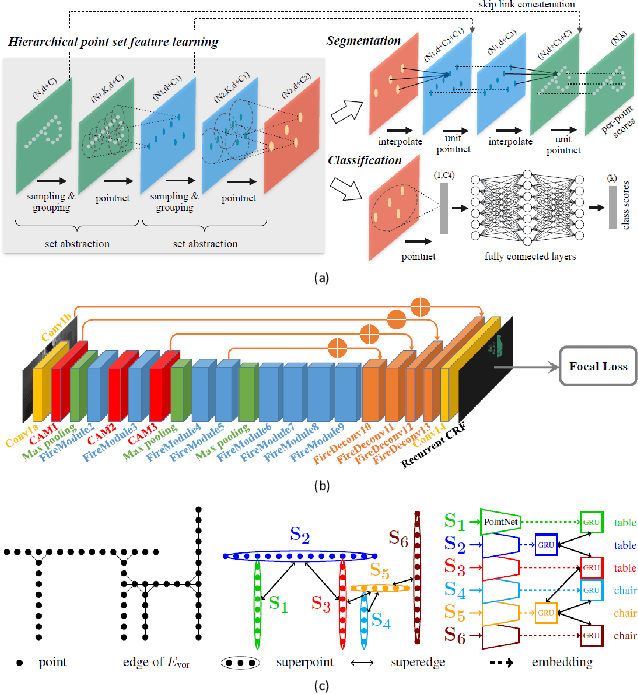
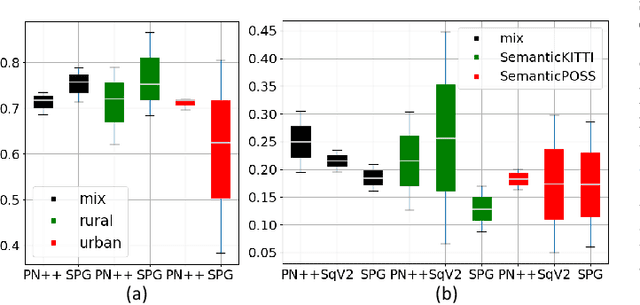
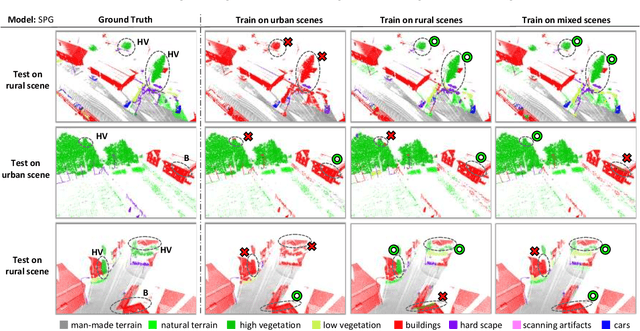
3D LiDAR semantic segmentation is a pivotal task that is widely involved in many applications, such as autonomous driving and robotics. Studies of 3D LiDAR semantic segmentation have recently achieved considerable development, especially in terms of deep learning strategies. However, these studies usually rely heavily on considerable fine annotated data, while point-wise 3D LiDAR datasets are extremely insufficient and expensive to label. The performance limitation caused by the lack of training data is called the data hungry effect. This survey aims to explore whether and how we are hungry for 3D LiDAR data for semantic segmentation. Thus, we first provide an organized review of existing 3D datasets and 3D semantic segmentation methods. Then, we provide an in-depth analysis of three representative datasets and several experiments to evaluate the data hungry effects in different aspects. Efforts to solve data hungry problems are summarized for both 3D LiDAR-focused methods and general-purpose methods. Finally, insightful topics are discussed for future research on data hungry problems and open questions.
Learning from Naturalistic Driving Data for Human-like Autonomous Highway Driving
May 23, 2020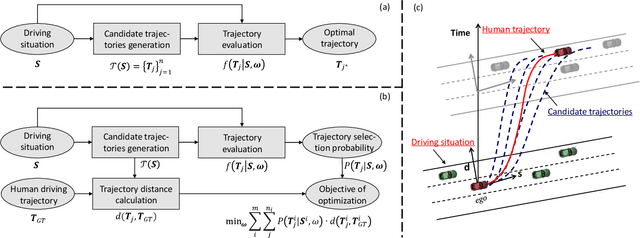
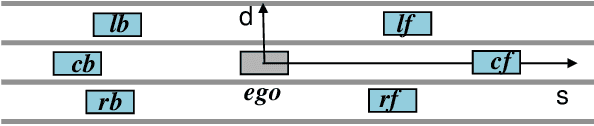

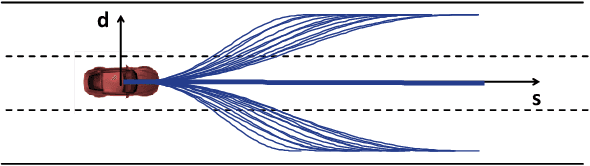
Driving in a human-like manner is important for an autonomous vehicle to be a smart and predictable traffic participant. To achieve this goal, parameters of the motion planning module should be carefully tuned, which needs great effort and expert knowledge. In this study, a method of learning cost parameters of a motion planner from naturalistic driving data is proposed. The learning is achieved by encouraging the selected trajectory to approximate the human driving trajectory under the same traffic situation. The employed motion planner follows a widely accepted methodology that first samples candidate trajectories in the trajectory space, then select the one with minimal cost as the planned trajectory. Moreover, in addition to traditional factors such as comfort, efficiency and safety, the cost function is proposed to incorporate incentive of behavior decision like a human driver, so that both lane change decision and motion planning are coupled into one framework. Two types of lane incentive cost -- heuristic and learning based -- are proposed and implemented. To verify the validity of the proposed method, a data set is developed by using the naturalistic trajectory data of human drivers collected on the motorways in Beijing, containing samples of lane changes to the left and right lanes, and car followings. Experiments are conducted with respect to both lane change decision and motion planning, and promising results are achieved.
Driver Identification through Stochastic Multi-State Car-Following Modeling
May 22, 2020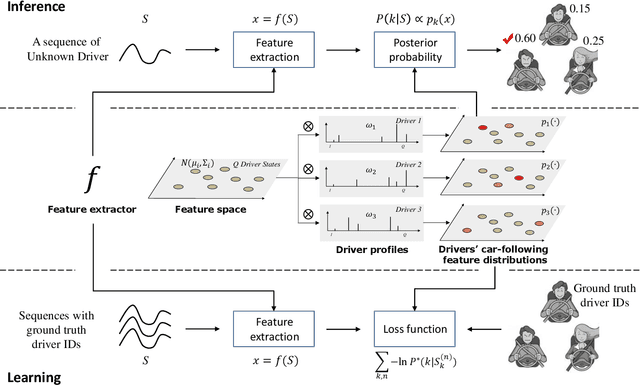
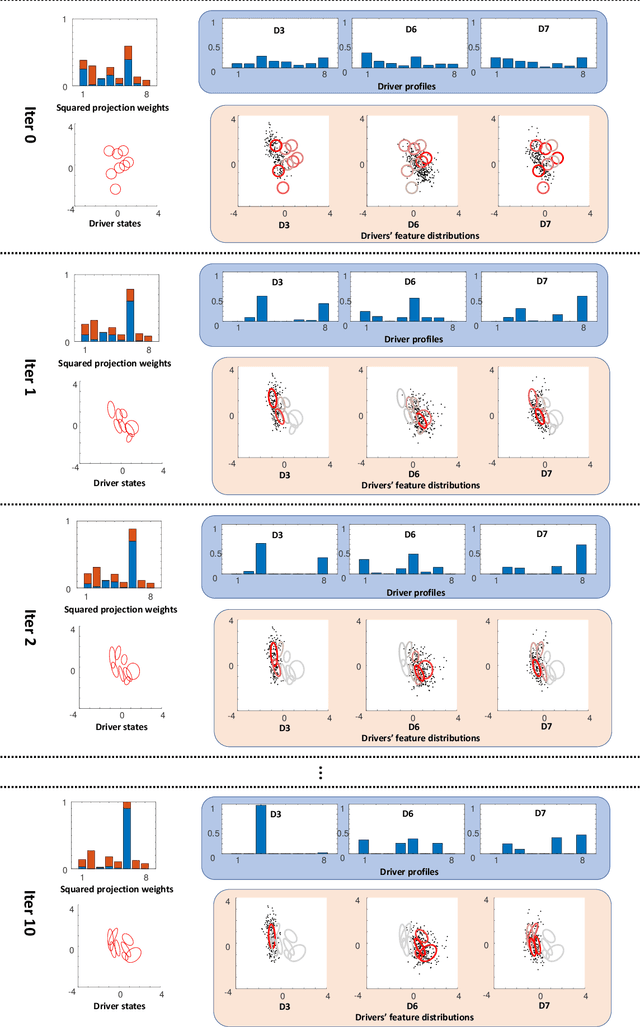
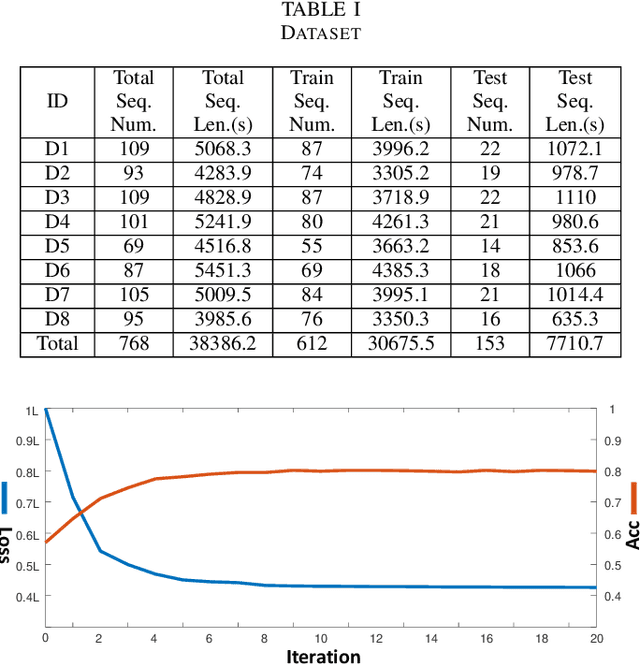
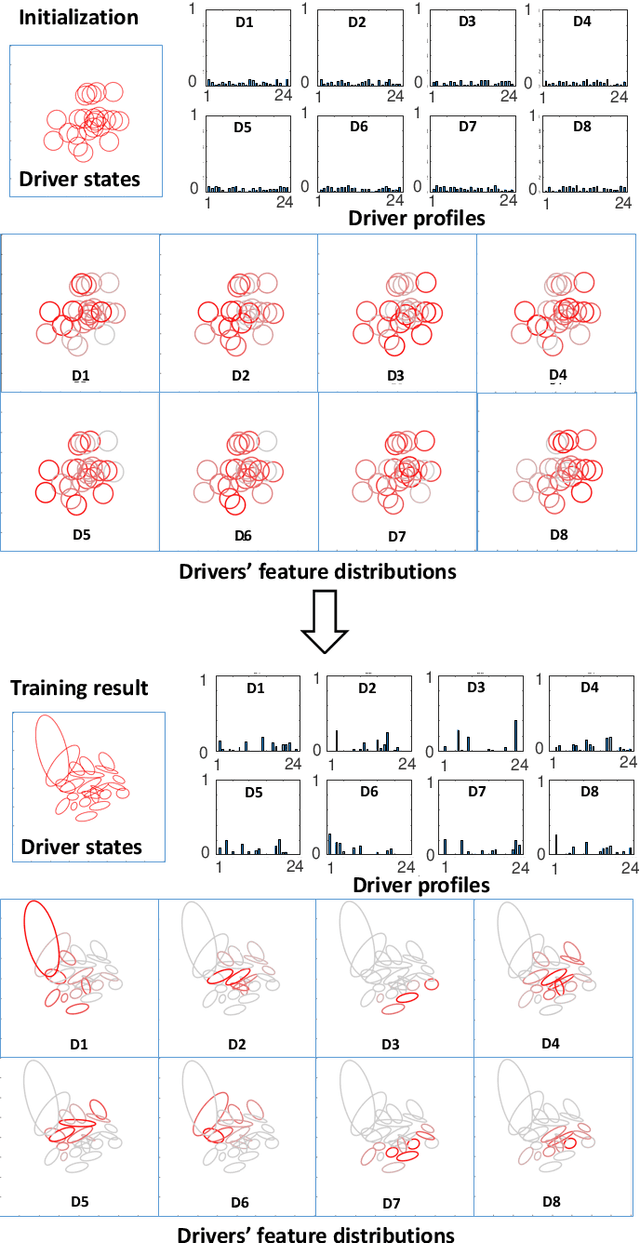
Intra-driver and inter-driver heterogeneity has been confirmed to exist in human driving behaviors by many studies. In this study, a joint model of the two types of heterogeneity in car-following behavior is proposed as an approach of driver profiling and identification. It is assumed that all drivers share a pool of driver states; under each state a car-following data sequence obeys a specific probability distribution in feature space; each driver has his/her own probability distribution over the states, called driver profile, which characterize the intradriver heterogeneity, while the difference between the driver profile of different drivers depict the inter-driver heterogeneity. Thus, the driver profile can be used to distinguish a driver from others. Based on the assumption, a stochastic car-following model is proposed to take both intra-driver and inter-driver heterogeneity into consideration, and a method is proposed to jointly learn parameters in behavioral feature extractor, driver states and driver profiles. Experiments demonstrate the performance of the proposed method in driver identification on naturalistic car-following data: accuracy of 82.3% is achieved in an 8-driver experiment using 10 car-following sequences of duration 15 seconds for online inference. The potential of fast registration of new drivers are demonstrated and discussed.