 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Image-based Approach of Task-driven Driving Scene Categorization
Mar 10, 2021

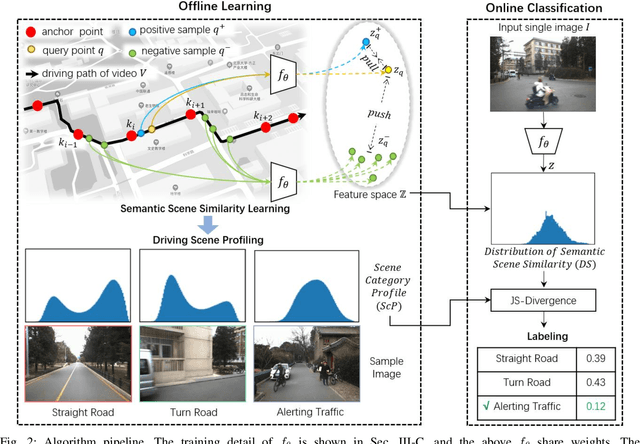
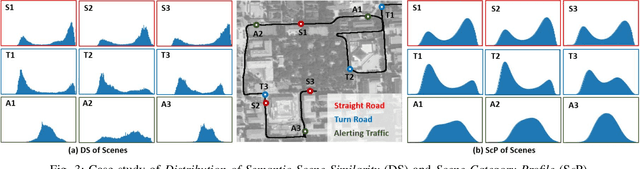
Categorizing driving scenes via visual perception is a key technology for safe driving and the downstream tasks of autonomous vehicles. Traditional methods infer scene category by detecting scene-related objects or using a classifier that is trained on large datasets of fine-labeled scene images. Whereas at cluttered dynamic scenes such as campus or park, human activities are not strongly confined by rules, and the functional attributes of places are not strongly correlated with objects. So how to define, model and infer scene categories is crucial to make the technique really helpful in assisting a robot to pass through the scene. This paper proposes a method of task-driven driving scene categorization using weakly supervised data. Given a front-view video of a driving scene, a set of anchor points is marked by following the decision making of a human driver, where an anchor point is not a semantic label but an indicator meaning the semantic attribute of the scene is different from that of the previous one. A measure is learned to discriminate the scenes of different semantic attributes via contrastive learning, and a driving scene profiling and categorization method is developed based on that measure. Experiments are conducted on a front-view video that is recorded when a vehicle passed through the cluttered dynamic campus of Peking University. The scenes are categorized into straight road, turn road and alerting traffic. The results of semantic scene similarity learning and driving scene categorization are extensively studied, and positive result of scene categorization is 97.17 \% on the learning video and 85.44\% on the video of new scenes.