 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind over Space: Can Multimodal Large Language Models Mentally Navigate?
Mar 23, 2026Despite the widespread adoption of MLLMs in embodied agents, their capabilities remain largely confined to reactive planning from immediate observations, consistently failing in spatial reasoning across extensive spatiotemporal scales. Cognitive science reveals that Biological Intelligence (BI) thrives on "mental navigation": the strategic construction of spatial representations from experience and the subsequent mental simulation of paths prior to action. To bridge the gap between AI and BI, we introduce Video2Mental, a pioneering benchmark for evaluating the mental navigation capabilities of MLLMs. The task requires constructing hierarchical cognitive maps from long egocentric videos and generating landmark-based path plans step by step, with planning accuracy verified through simulator-based physical interaction. Our benchmarking results reveal that mental navigation capability does not naturally emerge from standard pre-training. Frontier MLLMs struggle profoundly with zero-shot structured spatial representation, and their planning accuracy decays precipitously over extended horizons. To overcome this, we propose \textbf{NavMind}, a reasoning model that internalizes mental navigation using explicit, fine-grained cognitive maps as learnable intermediate representations. Through a difficulty-stratified progressive supervised fine-tuning paradigm, NavMind effectively bridges the gap between raw perception and structured planning. Experiments demonstrate that NavMind achieves superior mental navigation capabilities, significantly outperforming frontier commercial and spatial MLLMs.
Explainable Fuzzy Neural Network with Multi-Fidelity Reinforcement Learning for Micro-Architecture Design Space Exploration
Dec 14, 2024With the continuous advancement of processors, modern micro-architecture designs have become increasingly complex. The vast design space presents significant challenges for human designers, making design space exploration (DSE) algorithms a significant tool for $\mu$-arch design. In recent years, efforts have been made in the development of DSE algorithms, and promising results have been achieved. However, the existing DSE algorithms, e.g., Bayesian Optimization and ensemble learning, suffer from poor interpretability, hindering designers' understanding of the decision-making process. To address this limitation, we propose utilizing Fuzzy Neural Networks to induce and summarize knowledge and insights from the DSE process, enhancing interpretability and controllability. Furthermore, to improve efficiency, we introduce a multi-fidelity reinforcement learning approach, which primarily conducts exploration using cheap but less precise data, thereby substantially diminishing the reliance on costly data. Experimental results show that our method achieves excellent results with a very limited sample budget and successfully surpasses the current state-of-the-art. Our DSE framework is open-sourced and available at https://github.com/fanhanwei/FNN\_MFRL\_ArchDSE/\ .
High-dimensional Bayesian Optimization for CNN Auto Pruning with Clustering and Rollback
Sep 22, 2021
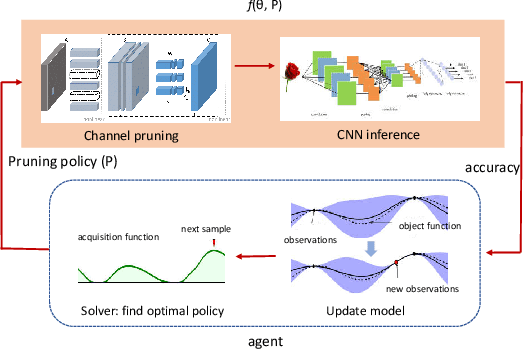

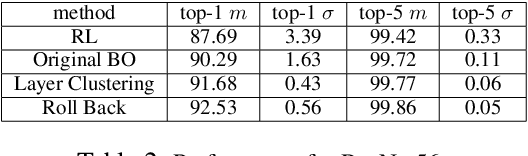
Pruning has been widely used to slim convolutional neural network (CNN) models to achieve a good trade-off between accuracy and model size so that the pruned models become feasible for power-constrained devices such as mobile phones. This process can be automated to avoid the expensive hand-crafted efforts and to explore a large pruning space automatically so that the high-performance pruning policy can be achieved efficiently. Nowadays, reinforcement learning (RL) and Bayesian optimization (BO)-based auto pruners are widely used due to their solid theoretical foundation, universality, and high compressing quality. However, the RL agent suffers from long training times and high variance of results, while the BO agent is time-consuming for high-dimensional design spaces. In this work, we propose an enhanced BO agent to obtain significant acceleration for auto pruning in high-dimensional design spaces. To achieve this, a novel clustering algorithm is proposed to reduce the dimension of the design space to speedup the searching process. Then, a roll-back algorithm is proposed to recover the high-dimensional design space so that higher pruning accuracy can be obtained. We validate our proposed method on ResNet, MobileNet, and VGG models, and our experiments show that the proposed method significantly improves the accuracy of BO when pruning very deep CNN models. Moreover, our method achieves lower variance and shorter time than the RL-based counterpart.
An Image-based Approach of Task-driven Driving Scene Categorization
Mar 10, 2021

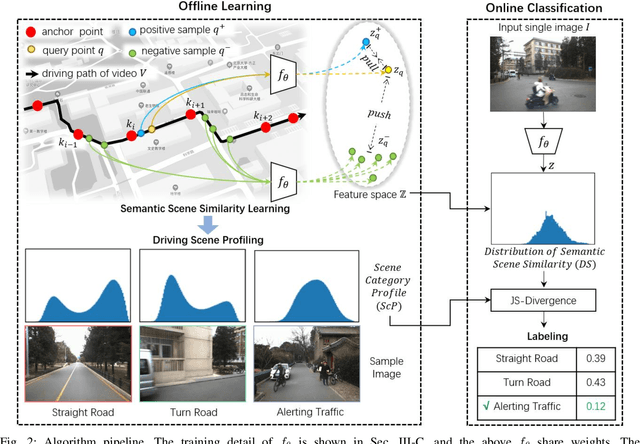
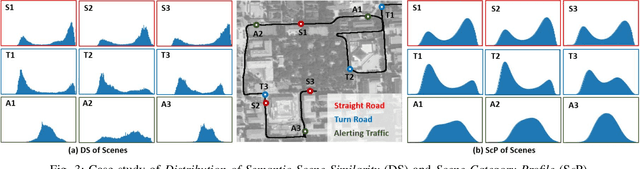
Categorizing driving scenes via visual perception is a key technology for safe driving and the downstream tasks of autonomous vehicles. Traditional methods infer scene category by detecting scene-related objects or using a classifier that is trained on large datasets of fine-labeled scene images. Whereas at cluttered dynamic scenes such as campus or park, human activities are not strongly confined by rules, and the functional attributes of places are not strongly correlated with objects. So how to define, model and infer scene categories is crucial to make the technique really helpful in assisting a robot to pass through the scene. This paper proposes a method of task-driven driving scene categorization using weakly supervised data. Given a front-view video of a driving scene, a set of anchor points is marked by following the decision making of a human driver, where an anchor point is not a semantic label but an indicator meaning the semantic attribute of the scene is different from that of the previous one. A measure is learned to discriminate the scenes of different semantic attributes via contrastive learning, and a driving scene profiling and categorization method is developed based on that measure. Experiments are conducted on a front-view video that is recorded when a vehicle passed through the cluttered dynamic campus of Peking University. The scenes are categorized into straight road, turn road and alerting traffic. The results of semantic scene similarity learning and driving scene categorization are extensively studied, and positive result of scene categorization is 97.17 \% on the learning video and 85.44\% on the video of new scenes.