 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLADY: Linear Attention for Autonomous Driving Efficiency without Transformers
Dec 18, 2025End-to-end paradigms have demonstrated great potential for autonomous driving. Additionally, most existing methods are built upon Transformer architectures. However, transformers incur a quadratic attention cost, limiting their ability to model long spatial and temporal sequences-particularly on resource-constrained edge platforms. As autonomous driving inherently demands efficient temporal modeling, this challenge severely limits their deployment and real-time performance. Recently, linear attention mechanisms have gained increasing attention due to their superior spatiotemporal complexity. However, existing linear attention architectures are limited to self-attention, lacking support for cross-modal and cross-temporal interactions-both crucial for autonomous driving. In this work, we propose LADY, the first fully linear attention-based generative model for end-to-end autonomous driving. LADY enables fusion of long-range temporal context at inference with constant computational and memory costs, regardless of the history length of camera and LiDAR features. Additionally, we introduce a lightweight linear cross-attention mechanism that enables effective cross-modal information exchange. Experiments on the NAVSIM and Bench2Drive benchmarks demonstrate that LADY achieves state-of-the-art performance with constant-time and memory complexity, offering improved planning performance and significantly reduced computational cost. Additionally, the model has been deployed and validated on edge devices, demonstrating its practicality in resource-limited scenarios.
MovieBench: A Hierarchical Movie Level Dataset for Long Video Generation
Nov 22, 2024



Recent advancements in video generation models, like Stable Video Diffusion, show promising results, but primarily focus on short, single-scene videos. These models struggle with generating long videos that involve multiple scenes, coherent narratives, and consistent characters. Furthermore, there is no publicly available dataset tailored for the analysis, evaluation, and training of long video generation models. In this paper, we present MovieBench: A Hierarchical Movie-Level Dataset for Long Video Generation, which addresses these challenges by providing unique contributions: (1) movie-length videos featuring rich, coherent storylines and multi-scene narratives, (2) consistency of character appearance and audio across scenes, and (3) hierarchical data structure contains high-level movie information and detailed shot-level descriptions. Experiments demonstrate that MovieBench brings some new insights and challenges, such as maintaining character ID consistency across multiple scenes for various characters. The dataset will be public and continuously maintained, aiming to advance the field of long video generation. Data can be found at: https://weijiawu.github.io/MovieBench/.
Learning Long-form Video Prior via Generative Pre-Training
Apr 24, 2024



Concepts involved in long-form videos such as people, objects, and their interactions, can be viewed as following an implicit prior. They are notably complex and continue to pose challenges to be comprehensively learned. In recent years, generative pre-training (GPT) has exhibited versatile capacities in modeling any kind of text content even visual locations. Can this manner work for learning long-form video prior? Instead of operating on pixel space, it is efficient to employ visual locations like bounding boxes and keypoints to represent key information in videos, which can be simply discretized and then tokenized for consumption by GPT. Due to the scarcity of suitable data, we create a new dataset called \textbf{Storyboard20K} from movies to serve as a representative. It includes synopses, shot-by-shot keyframes, and fine-grained annotations of film sets and characters with consistent IDs, bounding boxes, and whole body keypoints. In this way, long-form videos can be represented by a set of tokens and be learned via generative pre-training. Experimental results validate that our approach has great potential for learning long-form video prior. Code and data will be released at \url{https://github.com/showlab/Long-form-Video-Prior}.
Asynchronous Collaborative Autoscanning with Mode Switching for Multi-Robot Scene Reconstruction
Oct 10, 2022
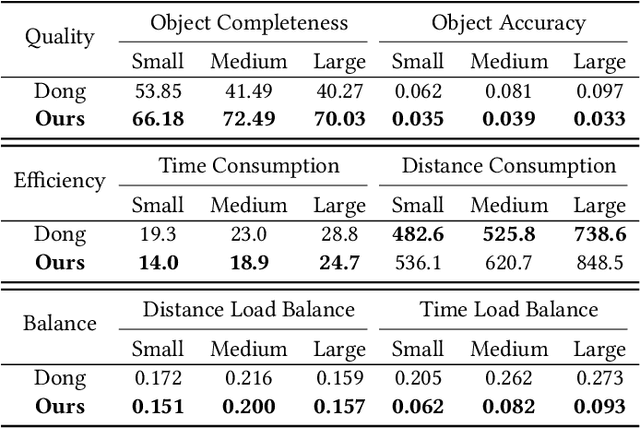
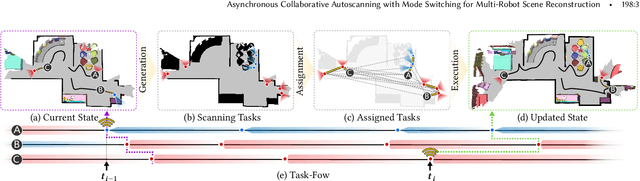
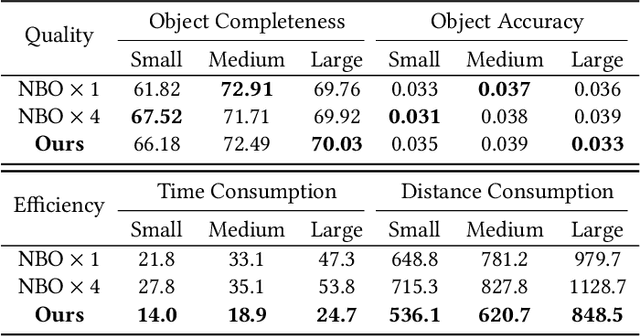
When conducting autonomous scanning for the online reconstruction of unknown indoor environments, robots have to be competent at exploring scene structure and reconstructing objects with high quality. Our key observation is that different tasks demand specialized scanning properties of robots: rapid moving speed and far vision for global exploration and slow moving speed and narrow vision for local object reconstruction, which are referred as two different scanning modes: explorer and reconstructor, respectively. When requiring multiple robots to collaborate for efficient exploration and fine-grained reconstruction, the questions on when to generate and how to assign those tasks should be carefully answered. Therefore, we propose a novel asynchronous collaborative autoscanning method with mode switching, which generates two kinds of scanning tasks with associated scanning modes, i.e., exploration task with explorer mode and reconstruction task with reconstructor mode, and assign them to the robots to execute in an asynchronous collaborative manner to highly boost the scanning efficiency and reconstruction quality. The task assignment is optimized by solving a modified Multi-Depot Multiple Traveling Salesman Problem (MDMTSP). Moreover, to further enhance the collaboration and increase the efficiency, we propose a task-flow model that actives the task generation and assignment process immediately when any of the robots finish all its tasks with no need to wait for all other robots to complete the tasks assigned in the previous iteration. Extensive experiments have been conducted to show the importance of each key component of our method and the superiority over previous methods in scanning efficiency and reconstruction quality.
* 13pages, 12 figures, Conference: SIGGRAPH Asia 2022
Object-Aware Guidance for Autonomous Scene Reconstruction
May 20, 2018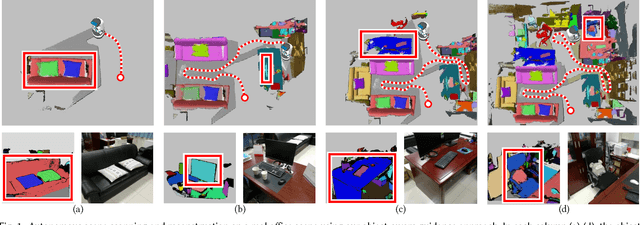
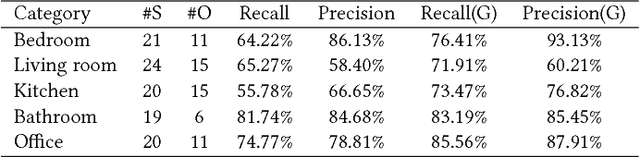
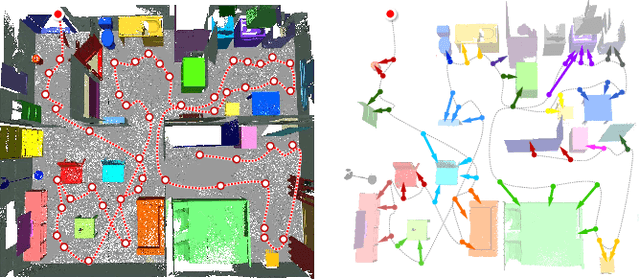
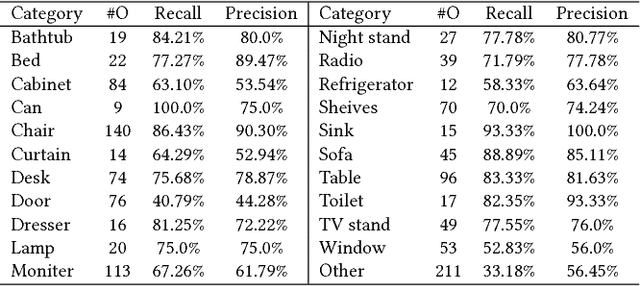
To carry out autonomous 3D scanning and online reconstruction of unknown indoor scenes, one has to find a balance between global exploration of the entire scene and local scanning of the objects within it. In this work, we propose a novel approach, which provides object-aware guidance for autoscanning, for exploring, reconstructing, and understanding an unknown scene within one navigation pass. Our approach interleaves between object analysis to identify the next best object (NBO) for global exploration, and object-aware information gain analysis to plan the next best view (NBV) for local scanning. First, an objectness-based segmentation method is introduced to extract semantic objects from the current scene surface via a multi-class graph cuts minimization. Then, an object of interest (OOI) is identified as the NBO which the robot aims to visit and scan. The robot then conducts fine scanning on the OOI with views determined by the NBV strategy. When the OOI is recognized as a full object, it can be replaced by its most similar 3D model in a shape database. The algorithm iterates until all of the objects are recognized and reconstructed in the scene. Various experiments and comparisons have shown the feasibility of our proposed approach.
* 12 pages, 17 figures