 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMR-LLM: Industrial Multi-Robot Task Planning and Program Generation using Large Language Models
Mar 03, 2026In modern industrial production, multiple robots often collaborate to complete complex manufacturing tasks. Large language models (LLMs), with their strong reasoning capabilities, have shown potential in coordinating robots for simple household and manipulation tasks. However, in industrial scenarios, stricter sequential constraints and more complex dependencies within tasks present new challenges for LLMs. To address this, we propose IMR-LLM, a novel LLM-driven Industrial Multi-Robot task planning and program generation framework. Specifically, we utilize LLMs to assist in constructing disjunctive graphs and employ deterministic solving methods to obtain a feasible and efficient high-level task plan. Based on this, we use a process tree to guide LLMs to generate executable low-level programs. Additionally, we create IMR-Bench, a challenging benchmark that encompasses multi-robot industrial tasks across three levels of complexity. Experimental results indicate that our method significantly surpasses existing methods across all evaluation metrics.
Learning Flexible Job Shop Scheduling under Limited Buffers and Material Kitting Constraints
Feb 27, 2026The Flexible Job Shop Scheduling Problem (FJSP) originates from real production lines, while some practical constraints are often ignored or idealized in current FJSP studies, among which the limited buffer problem has a particular impact on production efficiency. To this end, we study an extended problem that is closer to practical scenarios--the Flexible Job Shop Scheduling Problem with Limited Buffers and Material Kitting. In recent years, deep reinforcement learning (DRL) has demonstrated considerable potential in scheduling tasks. However, its capacity for state modeling remains limited when handling complex dependencies and long-term constraints. To address this, we leverage a heterogeneous graph network within the DRL framework to model the global state. By constructing efficient message passing among machines, operations, and buffers, the network focuses on avoiding decisions that may cause frequent pallet changes during long-sequence scheduling, thereby helping improve buffer utilization and overall decision quality. Experimental results on both synthetic and real production line datasets show that the proposed method outperforms traditional heuristics and advanced DRL methods in terms of makespan and pallet changes, and also achieves a good balance between solution quality and computational cost. Furthermore, a supplementary video is provided to showcase a simulation system that effectively visualizes the progression of the production line.
Deliberate Planning of 3D Bin Packing on Packing Configuration Trees
Apr 06, 2025Online 3D Bin Packing Problem (3D-BPP) has widespread applications in industrial automation. Existing methods usually solve the problem with limited resolution of spatial discretization, and/or cannot deal with complex practical constraints well. We propose to enhance the practical applicability of online 3D-BPP via learning on a novel hierarchical representation, packing configuration tree (PCT). PCT is a full-fledged description of the state and action space of bin packing which can support packing policy learning based on deep reinforcement learning (DRL). The size of the packing action space is proportional to the number of leaf nodes, making the DRL model easy to train and well-performing even with continuous solution space. We further discover the potential of PCT as tree-based planners in deliberately solving packing problems of industrial significance, including large-scale packing and different variations of BPP setting. A recursive packing method is proposed to decompose large-scale packing into smaller sub-trees while a spatial ensemble mechanism integrates local solutions into global. For different BPP variations with additional decision variables, such as lookahead, buffering, and offline packing, we propose a unified planning framework enabling out-of-the-box problem solving. Extensive evaluations demonstrate that our method outperforms existing online BPP baselines and is versatile in incorporating various practical constraints. The planning process excels across large-scale problems and diverse problem variations. We develop a real-world packing robot for industrial warehousing, with careful designs accounting for constrained placement and transportation stability. Our packing robot operates reliably and efficiently on unprotected pallets at 10 seconds per box. It achieves averagely 19 boxes per pallet with 57.4% space utilization for relatively large-size boxes.
FRI-Net: Floorplan Reconstruction via Room-wise Implicit Representation
Jul 15, 2024



In this paper, we introduce a novel method called FRI-Net for 2D floorplan reconstruction from 3D point cloud. Existing methods typically rely on corner regression or box regression, which lack consideration for the global shapes of rooms. To address these issues, we propose a novel approach using a room-wise implicit representation with structural regularization to characterize the shapes of rooms in floorplans. By incorporating geometric priors of room layouts in floorplans into our training strategy, the generated room polygons are more geometrically regular. We have conducted experiments on two challenging datasets, Structured3D and SceneCAD. Our method demonstrates improved performance compared to state-of-the-art methods, validating the effectiveness of our proposed representation for floorplan reconstruction.
Shape-driven Coordinate Ordering for Star Glyph Sets via Reinforcement Learning
Mar 03, 2021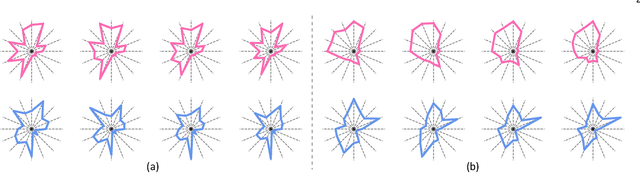
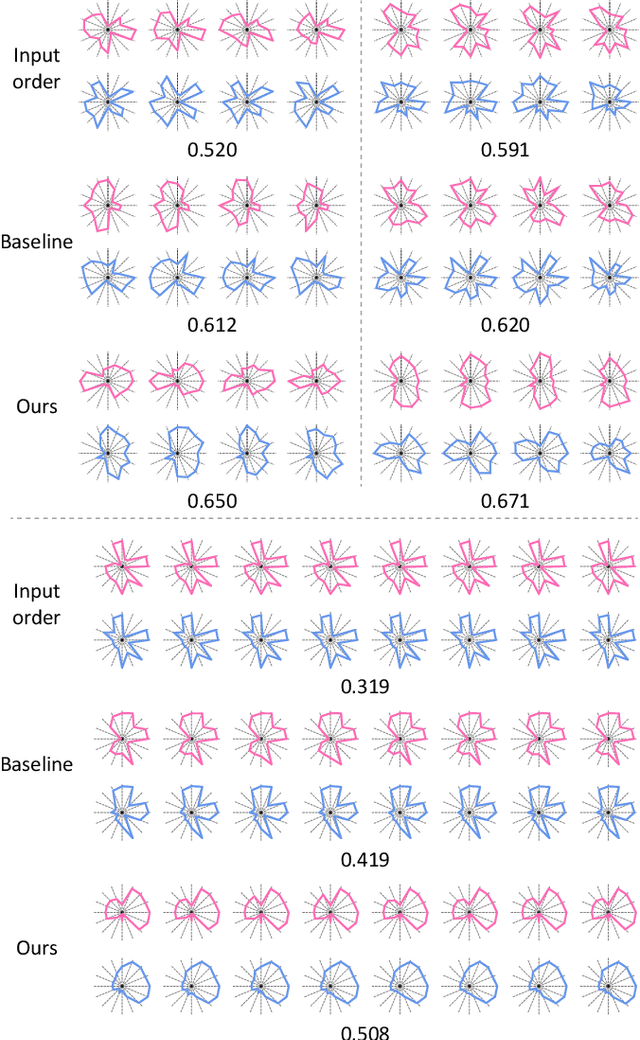
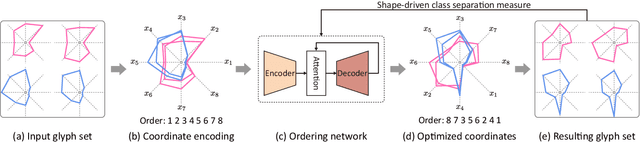
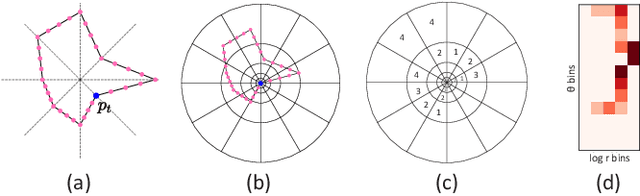
We present a neural optimization model trained with reinforcement learning to solve the coordinate ordering problem for sets of star glyphs. Given a set of star glyphs associated to multiple class labels, we propose to use shape context descriptors to measure the perceptual distance between pairs of glyphs, and use the derived silhouette coefficient to measure the perception of class separability within the entire set. To find the optimal coordinate order for the given set, we train a neural network using reinforcement learning to reward orderings with high silhouette coefficients. The network consists of an encoder and a decoder with an attention mechanism. The encoder employs a recurrent neural network (RNN) to encode input shape and class information, while the decoder together with the attention mechanism employs another RNN to output a sequence with the new coordinate order. In addition, we introduce a neural network to efficiently estimate the similarity between shape context descriptors, which allows to speed up the computation of silhouette coefficients and thus the training of the axis ordering network. Two user studies demonstrate that the orders provided by our method are preferred by users for perceiving class separation. We tested our model on different settings to show its robustness and generalization abilities and demonstrate that it allows to order input sets with unseen data size, data dimension, or number of classes. We also demonstrate that our model can be adapted to coordinate ordering of other types of plots such as RadViz by replacing the proposed shape-aware silhouette coefficient with the corresponding quality metric to guide network training.
TAP-Net: Transport-and-Pack using Reinforcement Learning
Sep 03, 2020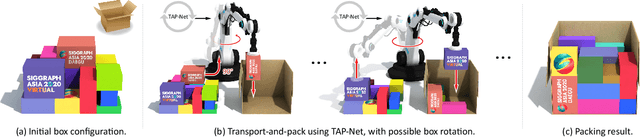
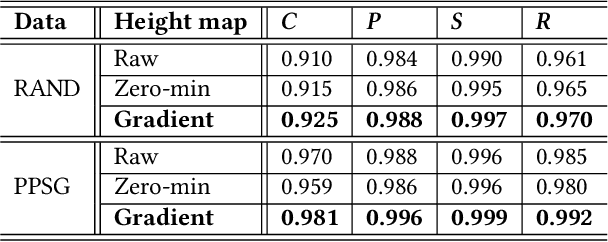
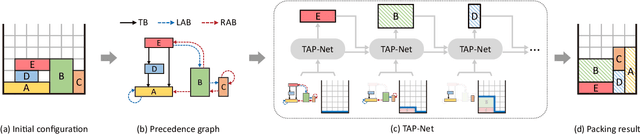
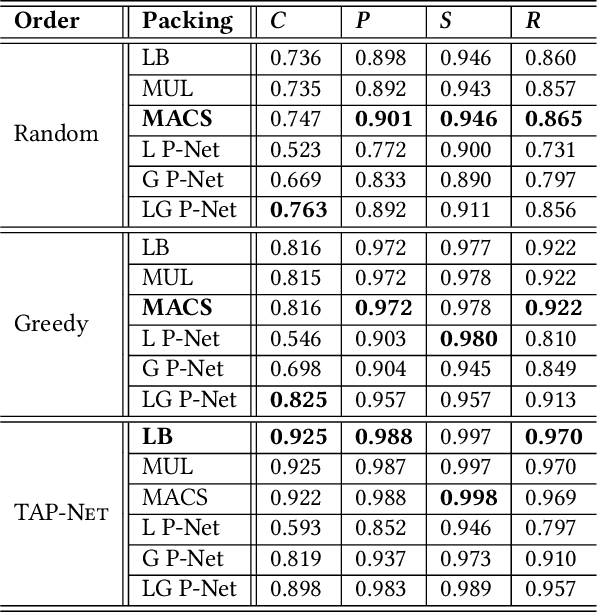
We introduce the transport-and-pack(TAP) problem, a frequently encountered instance of real-world packing, and develop a neural optimization solution based on reinforcement learning. Given an initial spatial configuration of boxes, we seek an efficient method to iteratively transport and pack the boxes compactly into a target container. Due to obstruction and accessibility constraints, our problem has to add a new search dimension, i.e., finding an optimal transport sequence, to the already immense search space for packing alone. Using a learning-based approach, a trained network can learn and encode solution patterns to guide the solution of new problem instances instead of executing an expensive online search. In our work, we represent the transport constraints using a precedence graph and train a neural network, coined TAP-Net, using reinforcement learning to reward efficient and stable packing. The network is built on an encoder-decoder architecture, where the encoder employs convolution layers to encode the box geometry and precedence graph and the decoder is a recurrent neural network (RNN) which inputs the current encoder output, as well as the current box packing state of the target container, and outputs the next box to pack, as well as its orientation. We train our network on randomly generated initial box configurations, without supervision, via policy gradients to learn optimal TAP policies to maximize packing efficiency and stability. We demonstrate the performance of TAP-Net on a variety of examples, evaluating the network through ablation studies and comparisons to baselines and alternative network designs. We also show that our network generalizes well to larger problem instances, when trained on small-sized inputs.
Object-Aware Guidance for Autonomous Scene Reconstruction
May 20, 2018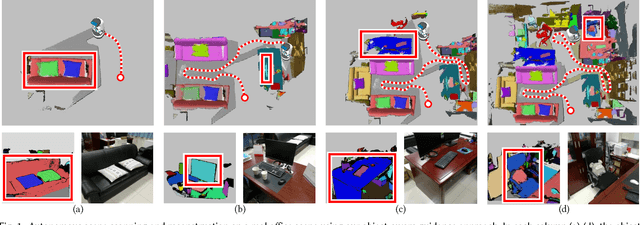
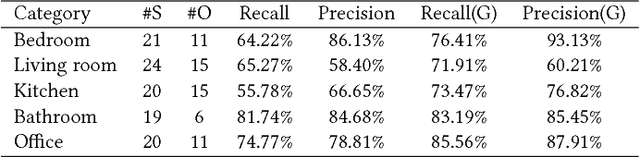
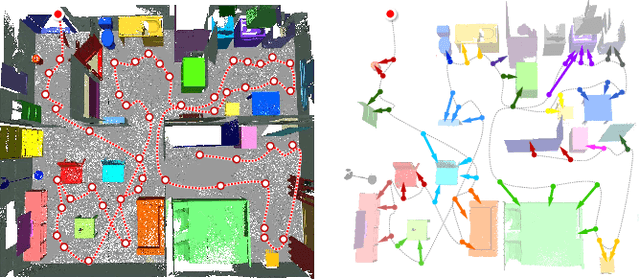
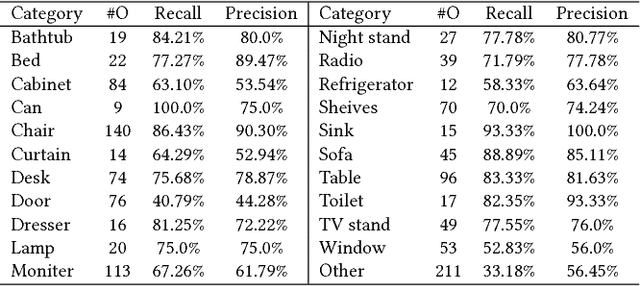
To carry out autonomous 3D scanning and online reconstruction of unknown indoor scenes, one has to find a balance between global exploration of the entire scene and local scanning of the objects within it. In this work, we propose a novel approach, which provides object-aware guidance for autoscanning, for exploring, reconstructing, and understanding an unknown scene within one navigation pass. Our approach interleaves between object analysis to identify the next best object (NBO) for global exploration, and object-aware information gain analysis to plan the next best view (NBV) for local scanning. First, an objectness-based segmentation method is introduced to extract semantic objects from the current scene surface via a multi-class graph cuts minimization. Then, an object of interest (OOI) is identified as the NBO which the robot aims to visit and scan. The robot then conducts fine scanning on the OOI with views determined by the NBV strategy. When the OOI is recognized as a full object, it can be replaced by its most similar 3D model in a shape database. The algorithm iterates until all of the objects are recognized and reconstructed in the scene. Various experiments and comparisons have shown the feasibility of our proposed approach.
* 12 pages, 17 figures