 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectTriGS: Triplane-based Gaussian Splatting Field Representation for 3D Generation
Mar 10, 2025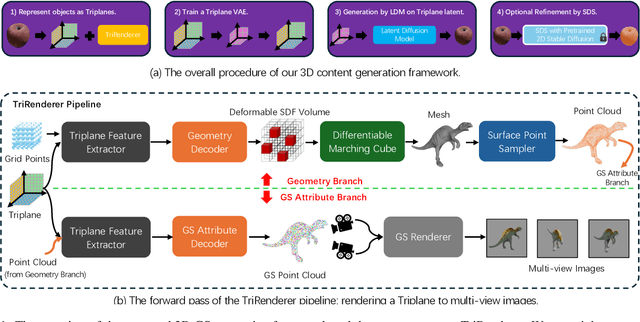
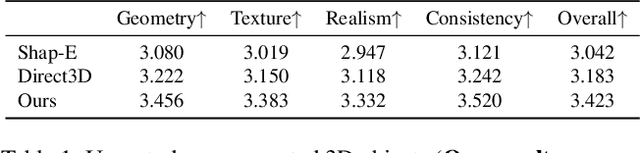
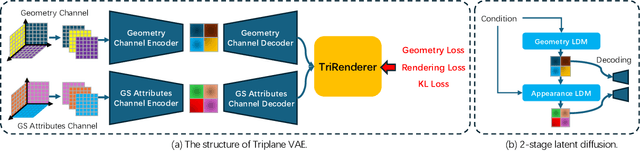
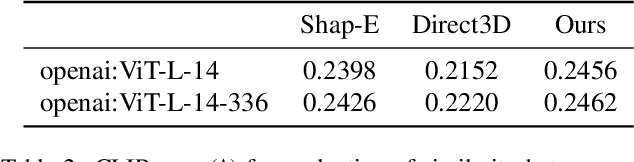
We present DirectTriGS, a novel framework designed for 3D object generation with Gaussian Splatting (GS). GS-based rendering for 3D content has gained considerable attention recently. However, there has been limited exploration in directly generating 3D Gaussians compared to traditional generative modeling approaches. The main challenge lies in the complex data structure of GS represented by discrete point clouds with multiple channels. To overcome this challenge, we propose employing the triplane representation, which allows us to represent Gaussian Splatting as an image-like continuous field. This representation effectively encodes both the geometry and texture information, enabling smooth transformation back to Gaussian point clouds and rendering into images by a TriRenderer, with only 2D supervisions. The proposed TriRenderer is fully differentiable, so that the rendering loss can supervise both texture and geometry encoding. Furthermore, the triplane representation can be compressed using a Variational Autoencoder (VAE), which can subsequently be utilized in latent diffusion to generate 3D objects. The experiments demonstrate that the proposed generation framework can produce high-quality 3D object geometry and rendering results in the text-to-3D task.
DiffRoom: Diffusion-based High-Quality 3D Room Reconstruction and Generation with Occupancy Prior
Jun 15, 2023We present DiffRoom, a novel framework for tackling the problem of high-quality 3D indoor room reconstruction and generation, both of which are challenging due to the complexity and diversity of the room geometry. Although diffusion-based generative models have previously demonstrated impressive performance in image generation and object-level 3D generation, they have not yet been applied to room-level 3D generation due to their computationally intensive costs. In DiffRoom, we propose a sparse 3D diffusion network that is efficient and possesses strong generative performance for Truncated Signed Distance Field (TSDF), based on a rough occupancy prior. Inspired by KinectFusion's incremental alignment and fusion of local SDFs, we propose a diffusion-based TSDF fusion approach that iteratively diffuses and fuses TSDFs, facilitating the reconstruction and generation of an entire room environment. Additionally, to ease training, we introduce a curriculum diffusion learning paradigm that speeds up the training convergence process and enables high-quality reconstruction. According to the user study, the mesh quality generated by our DiffRoom can even outperform the ground truth mesh provided by ScanNet. Please visit our project page for the latest progress and demonstrations: https://akirahero.github.io/DiffRoom/.
Perception Imitation: Towards Synthesis-free Simulator for Autonomous Vehicles
Apr 19, 2023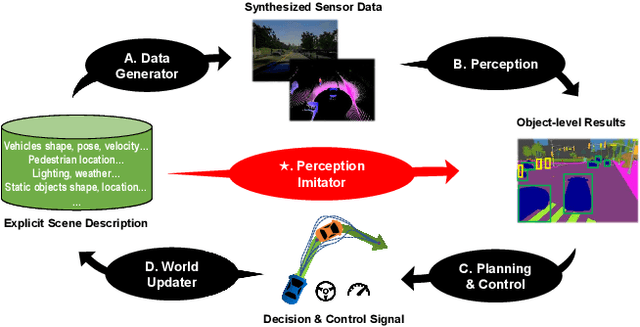
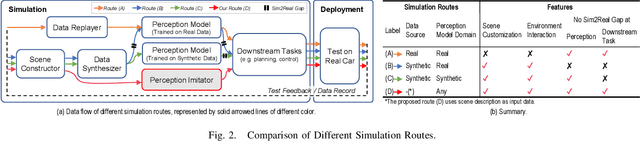
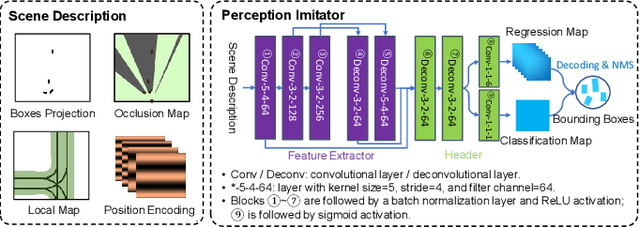
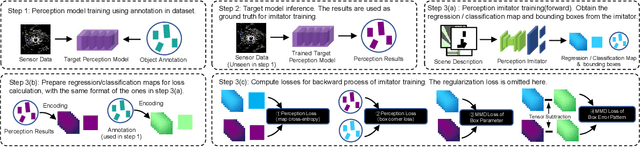
We propose a perception imitation method to simulate results of a certain perception model, and discuss a new heuristic route of autonomous driving simulator without data synthesis. The motivation is that original sensor data is not always necessary for tasks such as planning and control when semantic perception results are ready, so that simulating perception directly is more economic and efficient. In this work, a series of evaluation methods such as matching metric and performance of downstream task are exploited to examine the simulation quality. Experiments show that our method is effective to model the behavior of learning-based perception model, and can be further applied in the proposed simulation route smoothly.
Scene-Aware Error Modeling of LiDAR/Visual Odometry for Fusion-based Vehicle Localization
Mar 29, 2020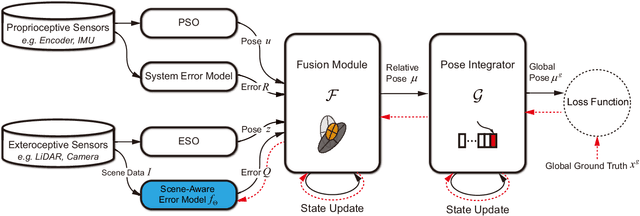
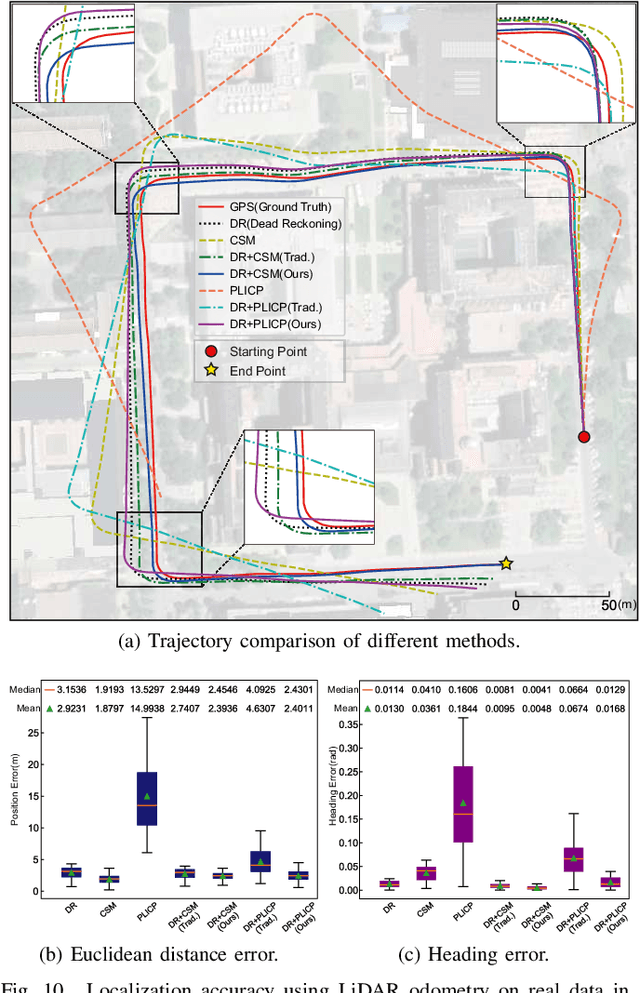
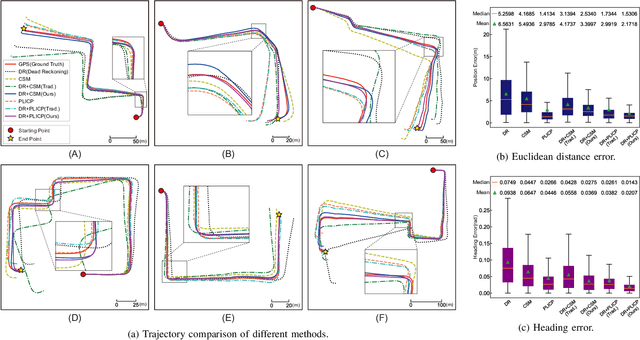
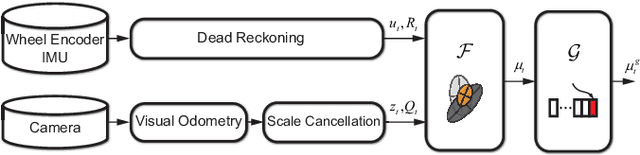
Localization is an essential technique in mobile robotics. In a complex environment, it is necessary to fuse different localization modules to obtain more robust results, in which the error model plays a paramount role. However, exteroceptive sensor-based odometries (ESOs), such as LiDAR/visual odometry, often deliver results with scene-related error, which is difficult to model accurately. To address this problem, this research designs a scene-aware error model for ESO, based on which a multimodal localization fusion framework is developed. In addition, an end-to-end learning method is proposed to train this error model using sparse global poses such as GPS/IMU results. The proposed method is realized for error modeling of LiDAR/visual odometry, and the results are fused with dead reckoning to examine the performance of vehicle localization. Experiments are conducted using both simulation and real-world data of experienced and unexperienced environments, and the experimental results demonstrate that with the learned scene-aware error models, vehicle localization accuracy can be largely improved and shows adaptiveness in unexperienced scenes.