 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Images as Continuous Actions: Numerical Visual Chain-of-Thought
Feb 27, 2026Recent multimodal large language models (MLLMs) increasingly rely on visual chain-of-thought to perform region-grounded reasoning over images. However, existing approaches ground regions via either textified coordinates-causing modality mismatch and semantic fragmentation or fixed-granularity patches that both limit precise region selection and often require non-trivial architectural changes. In this paper, we propose Numerical Visual Chain-of-Thought (NV-CoT), a framework that enables MLLMs to reason over images using continuous numerical coordinates. NV-CoT expands the MLLM action space from discrete vocabulary tokens to a continuous Euclidean space, allowing models to directly generate bounding-box coordinates as actions with only minimal architectural modification. The framework supports both supervised fine-tuning and reinforcement learning. In particular, we replace categorical token policies with a Gaussian (or Laplace) policy over coordinates and introduce stochasticity via reparameterized sampling, making NV-CoT fully compatible with GRPO-style policy optimization. Extensive experiments on three benchmarks against eight representative visual reasoning baselines demonstrate that NV-CoT significantly improves localization precision and final answer accuracy, while also accelerating training convergence, validating the effectiveness of continuous-action visual reasoning in MLLMs. The code is available in https://github.com/kesenzhao/NV-CoT.
NeuSpring: Neural Spring Fields for Reconstruction and Simulation of Deformable Objects from Videos
Nov 11, 2025In this paper, we aim to create physical digital twins of deformable objects under interaction. Existing methods focus more on the physical learning of current state modeling, but generalize worse to future prediction. This is because existing methods ignore the intrinsic physical properties of deformable objects, resulting in the limited physical learning in the current state modeling. To address this, we present NeuSpring, a neural spring field for the reconstruction and simulation of deformable objects from videos. Built upon spring-mass models for realistic physical simulation, our method consists of two major innovations: 1) a piecewise topology solution that efficiently models multi-region spring connection topologies using zero-order optimization, which considers the material heterogeneity of real-world objects. 2) a neural spring field that represents spring physical properties across different frames using a canonical coordinate-based neural network, which effectively leverages the spatial associativity of springs for physical learning. Experiments on real-world datasets demonstrate that our NeuSping achieves superior reconstruction and simulation performance for current state modeling and future prediction, with Chamfer distance improved by 20% and 25%, respectively.
DragNeXt: Rethinking Drag-Based Image Editing
Jun 09, 2025

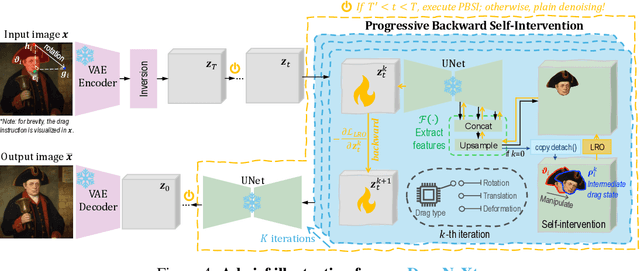

Drag-Based Image Editing (DBIE), which allows users to manipulate images by directly dragging objects within them, has recently attracted much attention from the community. However, it faces two key challenges: (\emph{\textcolor{magenta}{i}}) point-based drag is often highly ambiguous and difficult to align with users' intentions; (\emph{\textcolor{magenta}{ii}}) current DBIE methods primarily rely on alternating between motion supervision and point tracking, which is not only cumbersome but also fails to produce high-quality results. These limitations motivate us to explore DBIE from a new perspective -- redefining it as deformation, rotation, and translation of user-specified handle regions. Thereby, by requiring users to explicitly specify both drag areas and types, we can effectively address the ambiguity issue. Furthermore, we propose a simple-yet-effective editing framework, dubbed \textcolor{SkyBlue}{\textbf{DragNeXt}}. It unifies DBIE as a Latent Region Optimization (LRO) problem and solves it through Progressive Backward Self-Intervention (PBSI), simplifying the overall procedure of DBIE while further enhancing quality by fully leveraging region-level structure information and progressive guidance from intermediate drag states. We validate \textcolor{SkyBlue}{\textbf{DragNeXt}} on our NextBench, and extensive experiments demonstrate that our proposed method can significantly outperform existing approaches. Code will be released on github.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
CARE Transformer: Mobile-Friendly Linear Visual Transformer via Decoupled Dual Interaction
Nov 25, 2024



Recently, large efforts have been made to design efficient linear-complexity visual Transformers. However, current linear attention models are generally unsuitable to be deployed in resource-constrained mobile devices, due to suffering from either few efficiency gains or significant accuracy drops. In this paper, we propose a new de\textbf{C}oupled du\textbf{A}l-interactive linea\textbf{R} att\textbf{E}ntion (CARE) mechanism, revealing that features' decoupling and interaction can fully unleash the power of linear attention. We first propose an asymmetrical feature decoupling strategy that asymmetrically decouples the learning process for local inductive bias and long-range dependencies, thereby preserving sufficient local and global information while effectively enhancing the efficiency of models. Then, a dynamic memory unit is employed to maintain critical information along the network pipeline. Moreover, we design a dual interaction module to effectively facilitate interaction between local inductive bias and long-range information as well as among features at different layers. By adopting a decoupled learning way and fully exploiting complementarity across features, our method can achieve both high efficiency and accuracy. Extensive experiments on ImageNet-1K, COCO, and ADE20K datasets demonstrate the effectiveness of our approach, e.g., achieving $78.4/82.1\%$ top-1 accuracy on ImagegNet-1K at the cost of only $0.7/1.9$ GMACs. Codes will be released on \href{..}{github}.
TeFF: Tracking-enhanced Forgetting-free Few-shot 3D LiDAR Semantic Segmentation
Aug 28, 2024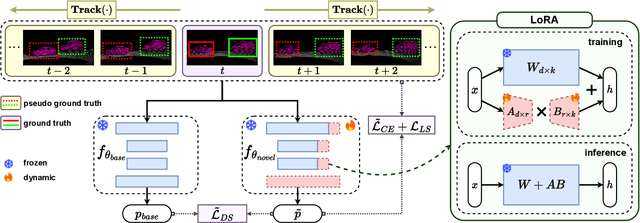
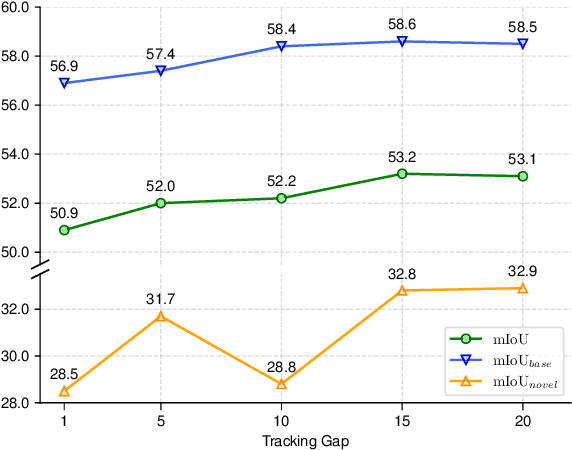
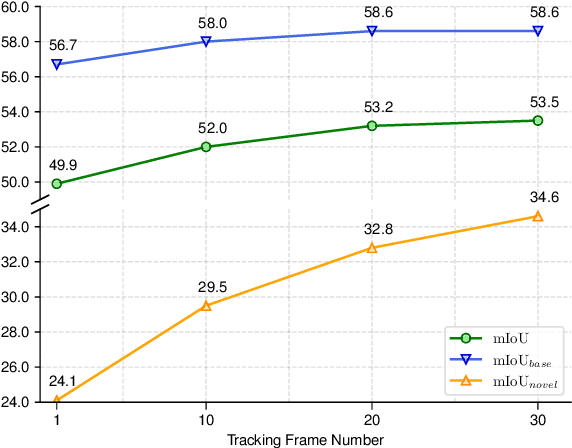
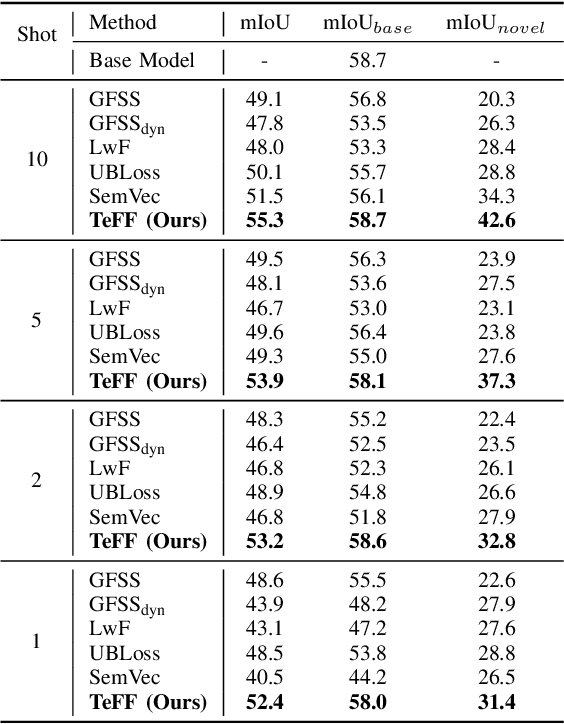
In autonomous driving, 3D LiDAR plays a crucial role in understanding the vehicle's surroundings. However, the newly emerged, unannotated objects presents few-shot learning problem for semantic segmentation. This paper addresses the limitations of current few-shot semantic segmentation by exploiting the temporal continuity of LiDAR data. Employing a tracking model to generate pseudo-ground-truths from a sequence of LiDAR frames, our method significantly augments the dataset, enhancing the model's ability to learn on novel classes. However, this approach introduces a data imbalance biased to novel data that presents a new challenge of catastrophic forgetting. To mitigate this, we incorporate LoRA, a technique that reduces the number of trainable parameters, thereby preserving the model's performance on base classes while improving its adaptability to novel classes. This work represents a significant step forward in few-shot 3D LiDAR semantic segmentation for autonomous driving. Our code is available at https://github.com/junbao-zhou/Track-no-forgetting.
RMem: Restricted Memory Banks Improve Video Object Segmentation
Jun 12, 2024



With recent video object segmentation (VOS) benchmarks evolving to challenging scenarios, we revisit a simple but overlooked strategy: restricting the size of memory banks. This diverges from the prevalent practice of expanding memory banks to accommodate extensive historical information. Our specially designed "memory deciphering" study offers a pivotal insight underpinning such a strategy: expanding memory banks, while seemingly beneficial, actually increases the difficulty for VOS modules to decode relevant features due to the confusion from redundant information. By restricting memory banks to a limited number of essential frames, we achieve a notable improvement in VOS accuracy. This process balances the importance and freshness of frames to maintain an informative memory bank within a bounded capacity. Additionally, restricted memory banks reduce the training-inference discrepancy in memory lengths compared with continuous expansion. This fosters new opportunities in temporal reasoning and enables us to introduce the previously overlooked "temporal positional embedding." Finally, our insights are embodied in "RMem" ("R" for restricted), a simple yet effective VOS modification that excels at challenging VOS scenarios and establishes new state of the art for object state changes (on the VOST dataset) and long videos (on the Long Videos dataset). Our code and demo are available at https://restricted-memory.github.io/.
Few-shot 3D LiDAR Semantic Segmentation for Autonomous Driving
Feb 17, 2023



In autonomous driving, the novel objects and lack of annotations challenge the traditional 3D LiDAR semantic segmentation based on deep learning. Few-shot learning is a feasible way to solve these issues. However, currently few-shot semantic segmentation methods focus on camera data, and most of them only predict the novel classes without considering the base classes. This setting cannot be directly applied to autonomous driving due to safety concerns. Thus, we propose a few-shot 3D LiDAR semantic segmentation method that predicts both novel classes and base classes simultaneously. Our method tries to solve the background ambiguity problem in generalized few-shot semantic segmentation. We first review the original cross-entropy and knowledge distillation losses, then propose a new loss function that incorporates the background information to achieve 3D LiDAR few-shot semantic segmentation. Extensive experiments on SemanticKITTI demonstrate the effectiveness of our method.