 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation
Dec 28, 2025This paper presents JavisGPT, the first unified multimodal large language model (MLLM) for Joint Audio-Video (JAV) comprehension and generation. JavisGPT adopts a concise encoder-LLM-decoder architecture, featuring a SyncFusion module for spatio-temporal audio-video fusion and synchrony-aware learnable queries to bridge a pretrained JAV-DiT generator. This design enables temporally coherent video-audio understanding and generation from multimodal instructions. We design an effective three-stage training pipeline consisting of multimodal pretraining, audio-video fine-tuning, and large-scale instruction-tuning, to progressively build multimodal comprehension and generation from existing vision-language models. To support this, we further construct JavisInst-Omni, a high-quality instruction dataset with over 200K GPT-4o-curated audio-video-text dialogues that span diverse and multi-level comprehension and generation scenarios. Extensive experiments on JAV comprehension and generation benchmarks show that JavisGPT outperforms existing MLLMs, particularly in complex and temporally synchronized settings.
Training LLMs with LogicReward for Faithful and Rigorous Reasoning
Dec 20, 2025
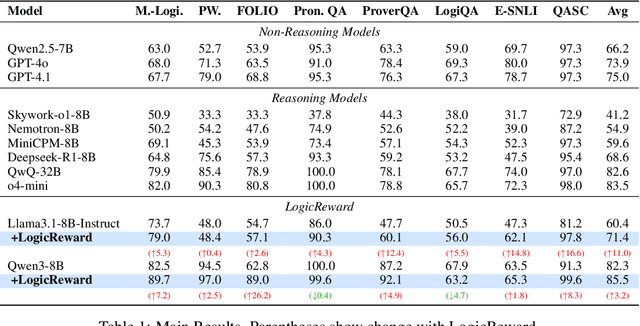
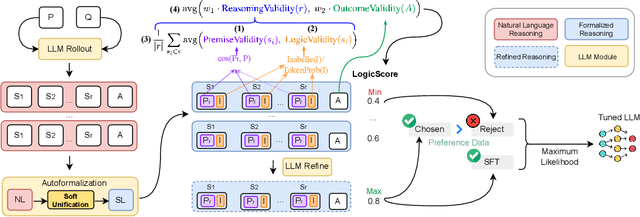

Although LLMs exhibit strong reasoning capabilities, existing training methods largely depend on outcome-based feedback, which can produce correct answers with flawed reasoning. Prior work introduces supervision on intermediate steps but still lacks guarantees of logical soundness, which is crucial in high-stakes scenarios where logical consistency is paramount. To address this, we propose LogicReward, a novel reward system that guides model training by enforcing step-level logical correctness with a theorem prover. We further introduce Autoformalization with Soft Unification, which reduces natural language ambiguity and improves formalization quality, enabling more effective use of the theorem prover. An 8B model trained on data constructed with LogicReward surpasses GPT-4o and o4-mini by 11.6\% and 2\% on natural language inference and logical reasoning tasks with simple training procedures. Further analysis shows that LogicReward enhances reasoning faithfulness, improves generalizability to unseen tasks such as math and commonsense reasoning, and provides a reliable reward signal even without ground-truth labels. We will release all data and code at https://llm-symbol.github.io/LogicReward.
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
Nov 11, 2025While specialized AI models excel at isolated video tasks like generation or understanding, real-world applications demand complex, iterative workflows that combine these capabilities. To bridge this gap, we introduce UniVA, an open-source, omni-capable multi-agent framework for next-generation video generalists that unifies video understanding, segmentation, editing, and generation into cohesive workflows. UniVA employs a Plan-and-Act dual-agent architecture that drives a highly automated and proactive workflow: a planner agent interprets user intentions and decomposes them into structured video-processing steps, while executor agents execute these through modular, MCP-based tool servers (for analysis, generation, editing, tracking, etc.). Through a hierarchical multi-level memory (global knowledge, task context, and user-specific preferences), UniVA sustains long-horizon reasoning, contextual continuity, and inter-agent communication, enabling interactive and self-reflective video creation with full traceability. This design enables iterative and any-conditioned video workflows (e.g., text/image/video-conditioned generation $\rightarrow$ multi-round editing $\rightarrow$ object segmentation $\rightarrow$ compositional synthesis) that were previously cumbersome to achieve with single-purpose models or monolithic video-language models. We also introduce UniVA-Bench, a benchmark suite of multi-step video tasks spanning understanding, editing, segmentation, and generation, to rigorously evaluate such agentic video systems. Both UniVA and UniVA-Bench are fully open-sourced, aiming to catalyze research on interactive, agentic, and general-purpose video intelligence for the next generation of multimodal AI systems. (https://univa.online/)
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
VistaDPO: Video Hierarchical Spatial-Temporal Direct Preference Optimization for Large Video Models
Apr 17, 2025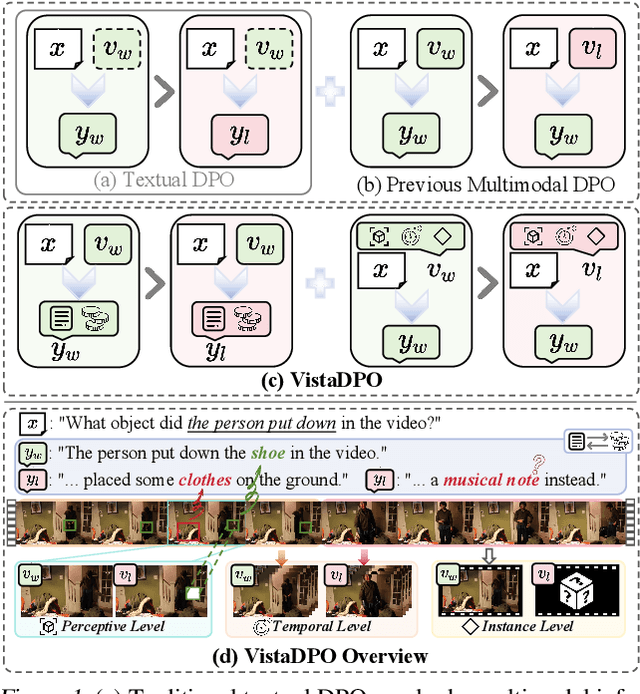
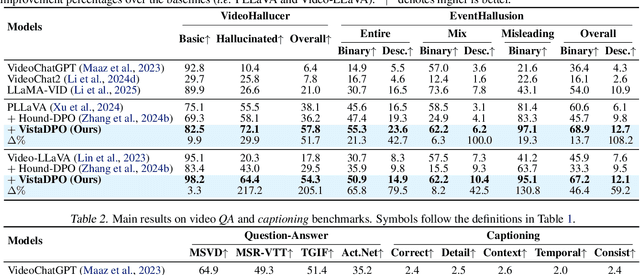
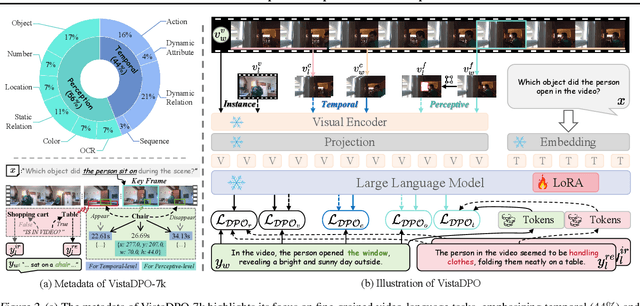
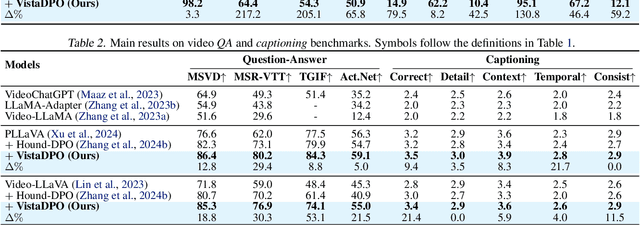
Large Video Models (LVMs) built upon Large Language Models (LLMs) have shown promise in video understanding but often suffer from misalignment with human intuition and video hallucination issues. To address these challenges, we introduce VistaDPO, a novel framework for Video Hierarchical Spatial-Temporal Direct Preference Optimization. VistaDPO enhances text-video preference alignment across three hierarchical levels: i) Instance Level, aligning overall video content with responses; ii) Temporal Level, aligning video temporal semantics with event descriptions; and iii) Perceptive Level, aligning spatial objects with language tokens. Given the lack of datasets for fine-grained video-language preference alignment, we construct VistaDPO-7k, a dataset of 7.2K QA pairs annotated with chosen and rejected responses, along with spatial-temporal grounding information such as timestamps, keyframes, and bounding boxes. Extensive experiments on benchmarks such as Video Hallucination, Video QA, and Captioning performance tasks demonstrate that VistaDPO significantly improves the performance of existing LVMs, effectively mitigating video-language misalignment and hallucination. The code and data are available at https://github.com/HaroldChen19/VistaDPO.
Any2Caption:Interpreting Any Condition to Caption for Controllable Video Generation
Mar 31, 2025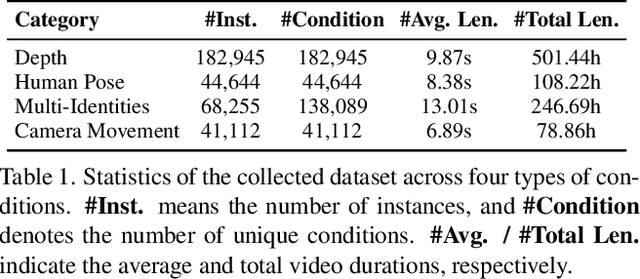



To address the bottleneck of accurate user intent interpretation within the current video generation community, we present Any2Caption, a novel framework for controllable video generation under any condition. The key idea is to decouple various condition interpretation steps from the video synthesis step. By leveraging modern multimodal large language models (MLLMs), Any2Caption interprets diverse inputs--text, images, videos, and specialized cues such as region, motion, and camera poses--into dense, structured captions that offer backbone video generators with better guidance. We also introduce Any2CapIns, a large-scale dataset with 337K instances and 407K conditions for any-condition-to-caption instruction tuning. Comprehensive evaluations demonstrate significant improvements of our system in controllability and video quality across various aspects of existing video generation models. Project Page: https://sqwu.top/Any2Cap/
JavisDiT: Joint Audio-Video Diffusion Transformer with Hierarchical Spatio-Temporal Prior Synchronization
Mar 30, 2025This paper introduces JavisDiT, a novel Joint Audio-Video Diffusion Transformer designed for synchronized audio-video generation (JAVG). Built upon the powerful Diffusion Transformer (DiT) architecture, JavisDiT is able to generate high-quality audio and video content simultaneously from open-ended user prompts. To ensure optimal synchronization, we introduce a fine-grained spatio-temporal alignment mechanism through a Hierarchical Spatial-Temporal Synchronized Prior (HiST-Sypo) Estimator. This module extracts both global and fine-grained spatio-temporal priors, guiding the synchronization between the visual and auditory components. Furthermore, we propose a new benchmark, JavisBench, consisting of 10,140 high-quality text-captioned sounding videos spanning diverse scenes and complex real-world scenarios. Further, we specifically devise a robust metric for evaluating the synchronization between generated audio-video pairs in real-world complex content. Experimental results demonstrate that JavisDiT significantly outperforms existing methods by ensuring both high-quality generation and precise synchronization, setting a new standard for JAVG tasks. Our code, model, and dataset will be made publicly available at https://javisdit.github.io/.
Universal Scene Graph Generation
Mar 19, 2025



Scene graph (SG) representations can neatly and efficiently describe scene semantics, which has driven sustained intensive research in SG generation. In the real world, multiple modalities often coexist, with different types, such as images, text, video, and 3D data, expressing distinct characteristics. Unfortunately, current SG research is largely confined to single-modality scene modeling, preventing the full utilization of the complementary strengths of different modality SG representations in depicting holistic scene semantics. To this end, we introduce Universal SG (USG), a novel representation capable of fully characterizing comprehensive semantic scenes from any given combination of modality inputs, encompassing modality-invariant and modality-specific scenes. Further, we tailor a niche-targeting USG parser, USG-Par, which effectively addresses two key bottlenecks of cross-modal object alignment and out-of-domain challenges. We design the USG-Par with modular architecture for end-to-end USG generation, in which we devise an object associator to relieve the modality gap for cross-modal object alignment. Further, we propose a text-centric scene contrasting learning mechanism to mitigate domain imbalances by aligning multimodal objects and relations with textual SGs. Through extensive experiments, we demonstrate that USG offers a stronger capability for expressing scene semantics than standalone SGs, and also that our USG-Par achieves higher efficacy and performance.
Learning 4D Panoptic Scene Graph Generation from Rich 2D Visual Scene
Mar 19, 2025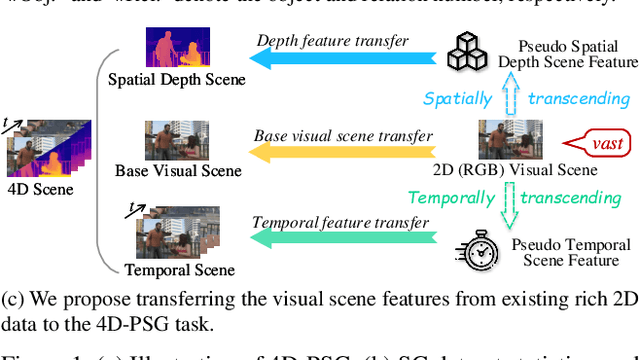

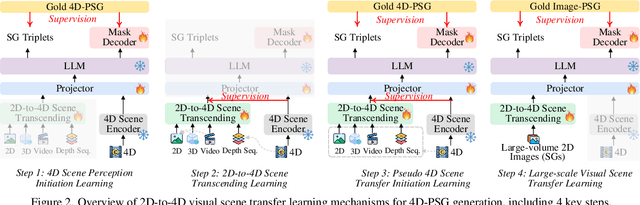

The latest emerged 4D Panoptic Scene Graph (4D-PSG) provides an advanced-ever representation for comprehensively modeling the dynamic 4D visual real world. Unfortunately, current pioneering 4D-PSG research can primarily suffer from data scarcity issues severely, as well as the resulting out-of-vocabulary problems; also, the pipeline nature of the benchmark generation method can lead to suboptimal performance. To address these challenges, this paper investigates a novel framework for 4D-PSG generation that leverages rich 2D visual scene annotations to enhance 4D scene learning. First, we introduce a 4D Large Language Model (4D-LLM) integrated with a 3D mask decoder for end-to-end generation of 4D-PSG. A chained SG inference mechanism is further designed to exploit LLMs' open-vocabulary capabilities to infer accurate and comprehensive object and relation labels iteratively. Most importantly, we propose a 2D-to-4D visual scene transfer learning framework, where a spatial-temporal scene transcending strategy effectively transfers dimension-invariant features from abundant 2D SG annotations to 4D scenes, effectively compensating for data scarcity in 4D-PSG. Extensive experiments on the benchmark data demonstrate that we strikingly outperform baseline models by a large margin, highlighting the effectiveness of our method.
Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey
Mar 16, 2025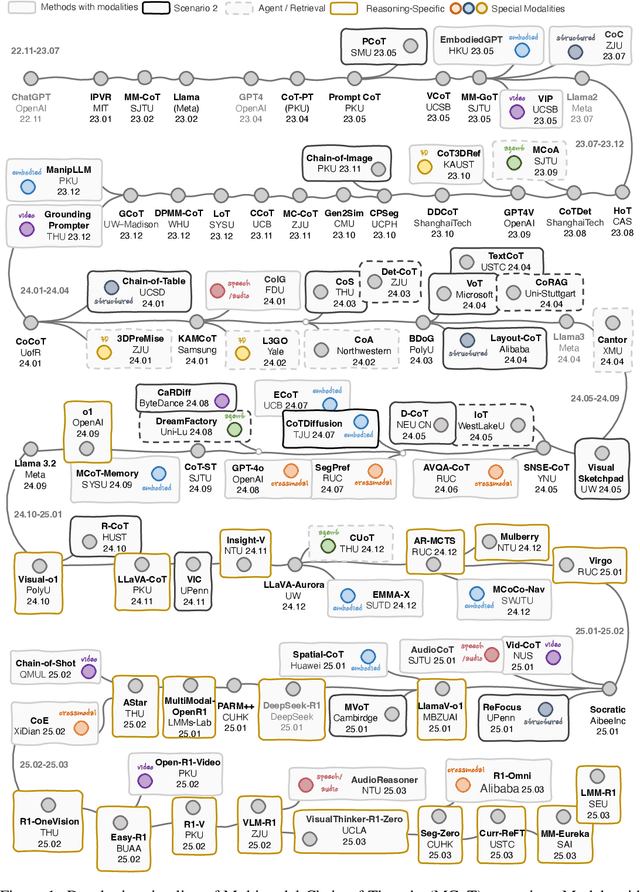

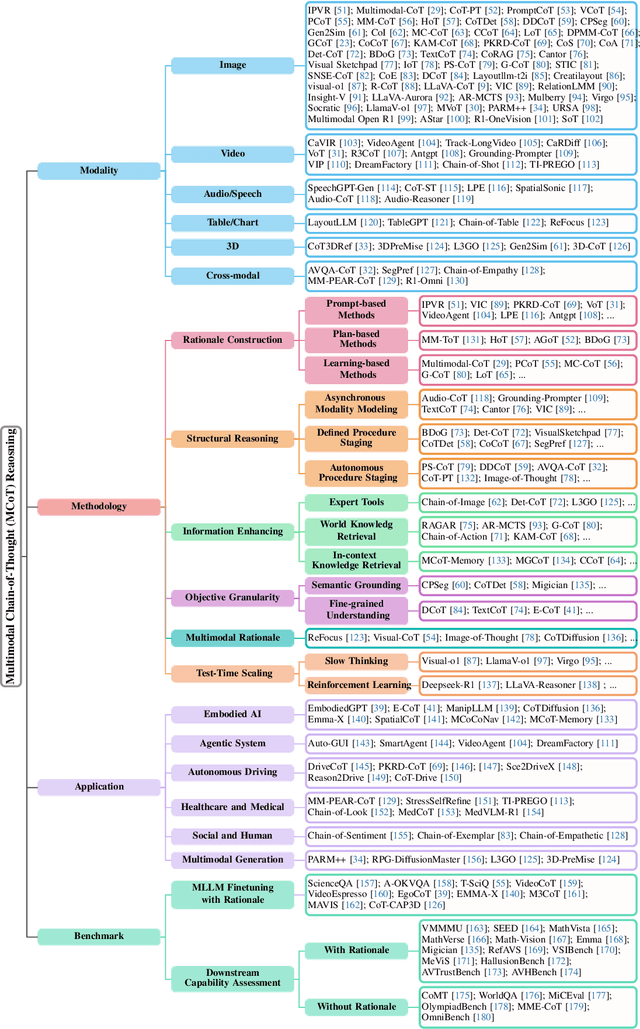
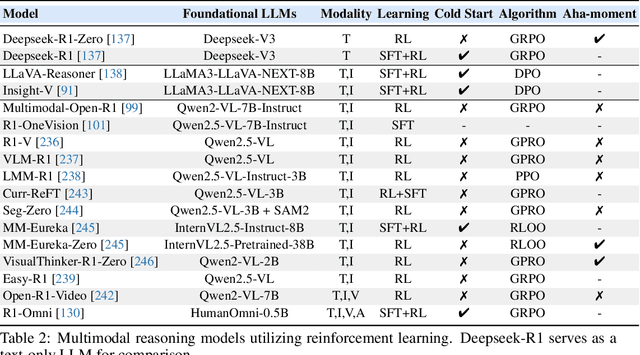
By extending the advantage of chain-of-thought (CoT) reasoning in human-like step-by-step processes to multimodal contexts, multimodal CoT (MCoT) reasoning has recently garnered significant research attention, especially in the integration with multimodal large language models (MLLMs). Existing MCoT studies design various methodologies and innovative reasoning paradigms to address the unique challenges of image, video, speech, audio, 3D, and structured data across different modalities, achieving extensive success in applications such as robotics, healthcare, autonomous driving, and multimodal generation. However, MCoT still presents distinct challenges and opportunities that require further focus to ensure consistent thriving in this field, where, unfortunately, an up-to-date review of this domain is lacking. To bridge this gap, we present the first systematic survey of MCoT reasoning, elucidating the relevant foundational concepts and definitions. We offer a comprehensive taxonomy and an in-depth analysis of current methodologies from diverse perspectives across various application scenarios. Furthermore, we provide insights into existing challenges and future research directions, aiming to foster innovation toward multimodal AGI.