 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Multimodal LLM Hallucination via Bottom-up Holistic Reasoning
Paper and Code
Dec 15, 2024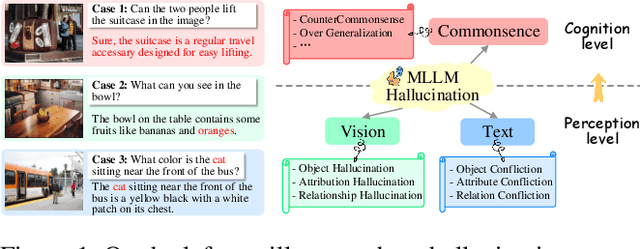
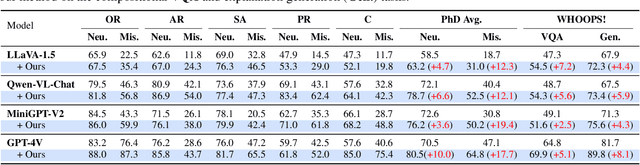
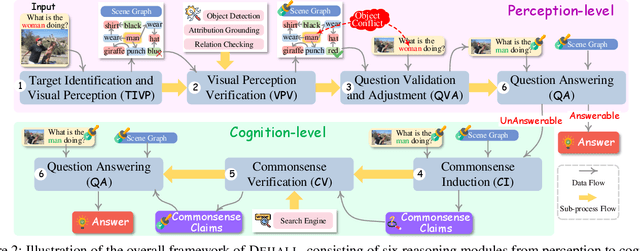
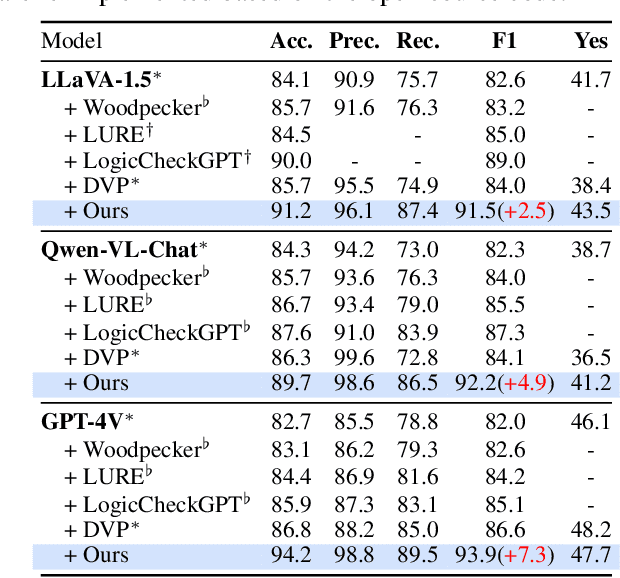
Recent advancements in multimodal large language models (MLLMs) have shown unprecedented capabilities in advancing various vision-language tasks. However, MLLMs face significant challenges with hallucinations, and misleading outputs that do not align with the input data. While existing efforts are paid to combat MLLM hallucinations, several pivotal challenges are still unsolved. First, while current approaches aggressively focus on addressing errors at the perception level, another important type at the cognition level requiring factual commonsense can be overlooked. In addition, existing methods might fall short in finding a more effective way to represent visual input, which is yet a key bottleneck that triggers visual hallucinations. Moreover, MLLMs can frequently be misled by faulty textual inputs and cause hallucinations, while unfortunately, this type of issue has long been overlooked by existing studies. Inspired by human intuition in handling hallucinations, this paper introduces a novel bottom-up reasoning framework. Our framework systematically addresses potential issues in both visual and textual inputs by verifying and integrating perception-level information with cognition-level commonsense knowledge, ensuring more reliable outputs. Extensive experiments demonstrate significant improvements in multiple hallucination benchmarks after integrating MLLMs with the proposed framework. In-depth analyses reveal the great potential of our methods in addressing perception- and cognition-level hallucinations.