 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergizing Understanding and Generation with Interleaved Analyzing-Drafting Thinking
Feb 24, 2026Unified Vision-Language Models (UVLMs) aim to advance multimodal learning by supporting both understanding and generation within a single framework. However, existing approaches largely focus on architectural unification while overlooking the need for explicit interaction between the two capabilities during task solving. As a result, current models treat understanding and generation as parallel skills rather than synergistic processes. To achieve real synergy, we introduce the interleaved Analyzing-Drafting problem-solving loop (AD-Loop), a new think paradigm that dynamically alternates between analytic and drafting operations. By interleaving textual thoughts with visual thoughts, AD-Loop enables models to iteratively refine both comprehension and outputs, fostering genuine synergy. To train this mechanism, we design a two-stage strategy: supervised learning on interleaved thought data to initialize alternation, followed by reinforcement learning to promote adaptive and autonomous control. Extensive experiments demonstrate that AD-Loop consistently improves performance across standard benchmarks for both understanding and generation, with strong transferability to various UVLMs architectures. Visual analyses further validate the effectiveness of implicit visual thoughts. These results highlight AD-Loop as a principled and broadly applicable strategy for synergizing comprehension and creation. The project page is at https://sqwu.top/AD-Loop.
Learning 4D Panoptic Scene Graph Generation from Rich 2D Visual Scene
Mar 19, 2025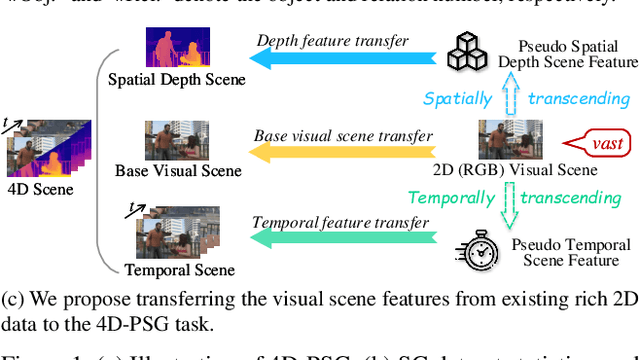

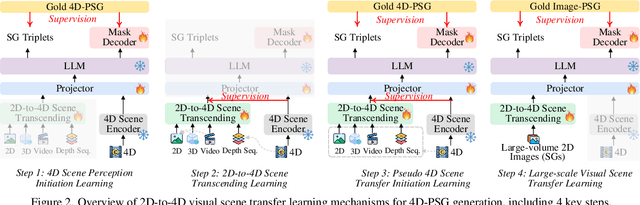

The latest emerged 4D Panoptic Scene Graph (4D-PSG) provides an advanced-ever representation for comprehensively modeling the dynamic 4D visual real world. Unfortunately, current pioneering 4D-PSG research can primarily suffer from data scarcity issues severely, as well as the resulting out-of-vocabulary problems; also, the pipeline nature of the benchmark generation method can lead to suboptimal performance. To address these challenges, this paper investigates a novel framework for 4D-PSG generation that leverages rich 2D visual scene annotations to enhance 4D scene learning. First, we introduce a 4D Large Language Model (4D-LLM) integrated with a 3D mask decoder for end-to-end generation of 4D-PSG. A chained SG inference mechanism is further designed to exploit LLMs' open-vocabulary capabilities to infer accurate and comprehensive object and relation labels iteratively. Most importantly, we propose a 2D-to-4D visual scene transfer learning framework, where a spatial-temporal scene transcending strategy effectively transfers dimension-invariant features from abundant 2D SG annotations to 4D scenes, effectively compensating for data scarcity in 4D-PSG. Extensive experiments on the benchmark data demonstrate that we strikingly outperform baseline models by a large margin, highlighting the effectiveness of our method.
AnyEdit: Edit Any Knowledge Encoded in Language Models
Feb 08, 2025



Large language models (LLMs) often produce incorrect or outdated information, necessitating efficient and precise knowledge updates. Current model editing methods, however, struggle with long-form knowledge in diverse formats, such as poetry, code snippets, and mathematical derivations. These limitations arise from their reliance on editing a single token's hidden state, a limitation we term "efficacy barrier". To solve this, we propose AnyEdit, a new autoregressive editing paradigm. It decomposes long-form knowledge into sequential chunks and iteratively edits the key token in each chunk, ensuring consistent and accurate outputs. Theoretically, we ground AnyEdit in the Chain Rule of Mutual Information, showing its ability to update any knowledge within LLMs. Empirically, it outperforms strong baselines by 21.5% on benchmarks including UnKEBench, AKEW, and our new EditEverything dataset for long-form diverse-formatted knowledge. Additionally, AnyEdit serves as a plug-and-play framework, enabling current editing methods to update knowledge with arbitrary length and format, significantly advancing the scope and practicality of LLM knowledge editing.
Preference Diffusion for Recommendation
Oct 17, 2024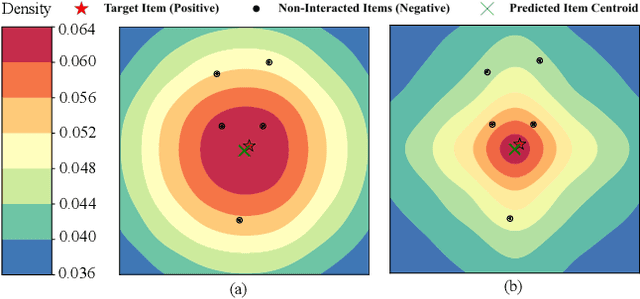
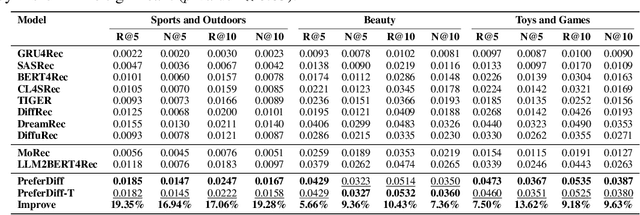

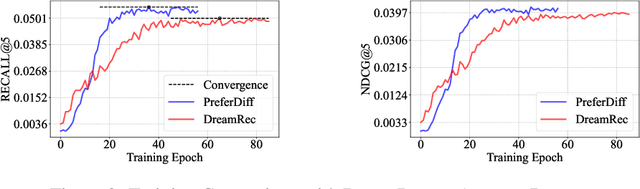
Recommender systems predict personalized item rankings based on user preference distributions derived from historical behavior data. Recently, diffusion models (DMs) have gained attention in recommendation for their ability to model complex distributions, yet current DM-based recommenders often rely on traditional objectives like mean squared error (MSE) or recommendation objectives, which are not optimized for personalized ranking tasks or fail to fully leverage DM's generative potential. To address this, we propose PreferDiff, a tailored optimization objective for DM-based recommenders. PreferDiff transforms BPR into a log-likelihood ranking objective and integrates multiple negative samples to better capture user preferences. Specifically, we employ variational inference to handle the intractability through minimizing the variational upper bound and replaces MSE with cosine error to improve alignment with recommendation tasks. Finally, we balance learning generation and preference to enhance the training stability of DMs. PreferDiff offers three key benefits: it is the first personalized ranking loss designed specifically for DM-based recommenders and it improves ranking and faster convergence by addressing hard negatives. We also prove that it is theoretically connected to Direct Preference Optimization which indicates that it has the potential to align user preferences in DM-based recommenders via generative modeling. Extensive experiments across three benchmarks validate its superior recommendation performance and commendable general sequential recommendation capabilities. Our codes are available at \url{https://github.com/lswhim/PreferDiff}.
AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models
Oct 03, 2024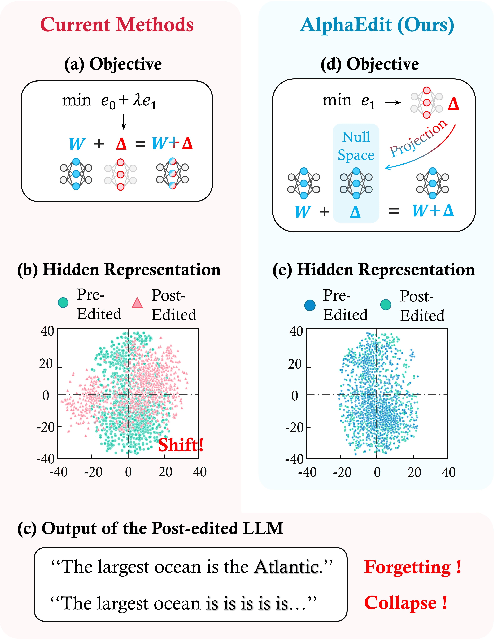



Large language models (LLMs) often exhibit hallucinations due to incorrect or outdated knowledge. Hence, model editing methods have emerged to enable targeted knowledge updates. To achieve this, a prevailing paradigm is the locating-then-editing approach, which first locates influential parameters and then edits them by introducing a perturbation. While effective, current studies have demonstrated that this perturbation inevitably disrupt the originally preserved knowledge within LLMs, especially in sequential editing scenarios. To address this, we introduce AlphaEdit, a novel solution that projects perturbation onto the null space of the preserved knowledge before applying it to the parameters. We theoretically prove that this projection ensures the output of post-edited LLMs remains unchanged when queried about the preserved knowledge, thereby mitigating the issue of disruption. Extensive experiments on various LLMs, including LLaMA3, GPT2-XL, and GPT-J, show that AlphaEdit boosts the performance of most locating-then-editing methods by an average of 36.4% with a single line of additional code for projection solely. Our code is available at: https://github.com/jianghoucheng/AlphaEdit.
Harnessing Large Language Models for Multimodal Product Bundling
Jul 16, 2024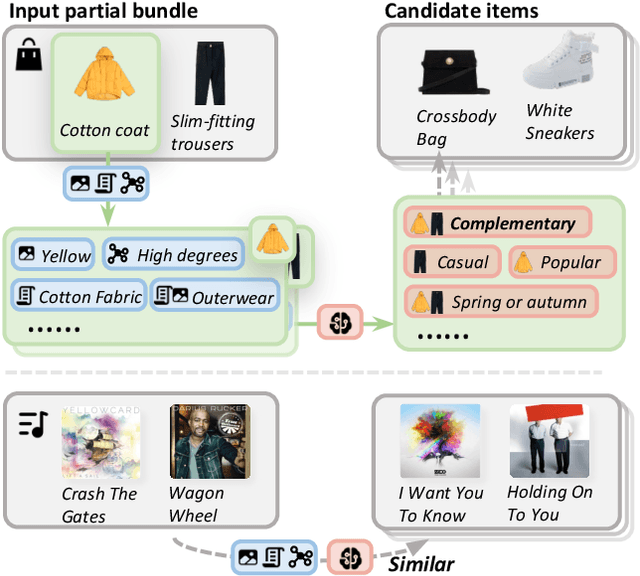

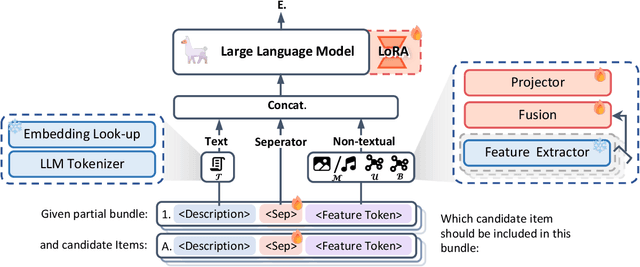
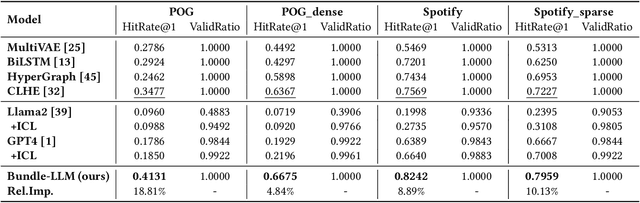
Product bundling provides clients with a strategic combination of individual items.And it has gained significant attention in recent years as a fundamental prerequisite for online services. Recent methods utilize multimodal information through sophisticated extractors for bundling, but remain limited by inferior semantic understanding, the restricted scope of knowledge, and an inability to handle cold-start issues.Despite the extensive knowledge and complex reasoning capabilities of large language models (LLMs), their direct utilization fails to process multimodalities and exploit their knowledge for multimodal product bundling. Adapting LLMs for this purpose involves demonstrating the synergies among different modalities and designing an effective optimization strategy for bundling, which remains challenging.To this end, we introduce Bundle-LLM to bridge the gap between LLMs and product bundling tasks. Sepcifically, we utilize a hybrid item tokenization to integrate multimodal information, where a simple yet powerful multimodal fusion module followed by a trainable projector embeds all non-textual features into a single token. This module not only explicitly exhibits the interplays among modalities but also shortens the prompt length, thereby boosting efficiency.By designing a prompt template, we formulate product bundling as a multiple-choice question given candidate items. Furthermore, we adopt progressive optimization strategy to fine-tune the LLMs for disentangled objectives, achieving effective product bundling capability with comprehensive multimodal semantic understanding.Extensive experiments on four datasets from two application domains show that our approach outperforms a range of state-of-the-art (SOTA) methods.
Instilling Multi-round Thinking to Text-guided Image Generation
Jan 16, 2024


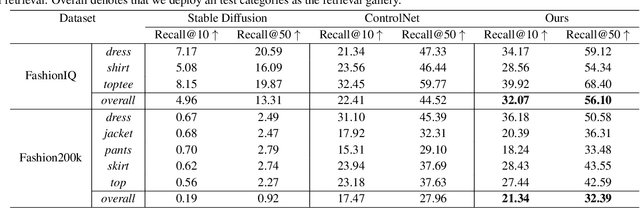
In this paper, we study the text-guided image generation task. Our focus lies in the modification of a reference image, given user text feedback, to imbue it with specific desired properties. Despite recent strides in this field, a persistent challenge remains that single-round optimization often overlooks crucial details, particularly in the realm of fine-grained changes like shoes or sleeves. This misalignment accumulation significantly hampers multi-round customization during interaction. In an attempt to address this challenge, we introduce a new self-supervised regularization into the existing framework, i.e., multi-round regularization. It builds upon the observation that the modification order does not affect the final result. As the name suggests, the multi-round regularization encourages the model to maintain consistency across different modification orders. Specifically, our proposed approach addresses the issue where an initial failure to capture fine-grained details leads to substantial discrepancies after multiple rounds, as opposed to traditional one-round learning. Both qualitative and quantitative experiments show the proposed method achieves high-fidelity generation quality over the text-guided generation task, especially the local modification. Furthermore, we extend the evaluation to semantic alignment with text by applying our method to text-guided retrieval datasets, such as FahisonIQ, where it demonstrates competitive performance.
Robust Collaborative Filtering to Popularity Distribution Shift
Oct 16, 2023



In leading collaborative filtering (CF) models, representations of users and items are prone to learn popularity bias in the training data as shortcuts. The popularity shortcut tricks are good for in-distribution (ID) performance but poorly generalized to out-of-distribution (OOD) data, i.e., when popularity distribution of test data shifts w.r.t. the training one. To close the gap, debiasing strategies try to assess the shortcut degrees and mitigate them from the representations. However, there exist two deficiencies: (1) when measuring the shortcut degrees, most strategies only use statistical metrics on a single aspect (i.e., item frequency on item and user frequency on user aspect), failing to accommodate the compositional degree of a user-item pair; (2) when mitigating shortcuts, many strategies assume that the test distribution is known in advance. This results in low-quality debiased representations. Worse still, these strategies achieve OOD generalizability with a sacrifice on ID performance. In this work, we present a simple yet effective debiasing strategy, PopGo, which quantifies and reduces the interaction-wise popularity shortcut without any assumptions on the test data. It first learns a shortcut model, which yields a shortcut degree of a user-item pair based on their popularity representations. Then, it trains the CF model by adjusting the predictions with the interaction-wise shortcut degrees. By taking both causal- and information-theoretical looks at PopGo, we can justify why it encourages the CF model to capture the critical popularity-agnostic features while leaving the spurious popularity-relevant patterns out. We use PopGo to debias two high-performing CF models (MF, LightGCN) on four benchmark datasets. On both ID and OOD test sets, PopGo achieves significant gains over the state-of-the-art debiasing strategies (e.g., DICE, MACR).
Progressive Text-to-3D Generation for Automatic 3D Prototyping
Sep 26, 2023



Text-to-3D generation is to craft a 3D object according to a natural language description. This can significantly reduce the workload for manually designing 3D models and provide a more natural way of interaction for users. However, this problem remains challenging in recovering the fine-grained details effectively and optimizing a large-size 3D output efficiently. Inspired by the success of progressive learning, we propose a Multi-Scale Triplane Network (MTN) and a new progressive learning strategy. As the name implies, the Multi-Scale Triplane Network consists of four triplanes transitioning from low to high resolution. The low-resolution triplane could serve as an initial shape for the high-resolution ones, easing the optimization difficulty. To further enable the fine-grained details, we also introduce the progressive learning strategy, which explicitly demands the network to shift its focus of attention from simple coarse-grained patterns to difficult fine-grained patterns. Our experiment verifies that the proposed method performs favorably against existing methods. For even the most challenging descriptions, where most existing methods struggle to produce a viable shape, our proposed method consistently delivers. We aspire for our work to pave the way for automatic 3D prototyping via natural language descriptions.
Search-in-the-Chain: Towards Accurate, Credible and Traceable Large Language Models for Knowledge-intensive Tasks
May 05, 2023With the wide application of Large Language Models (LLMs) such as ChatGPT, how to make the contents generated by LLM accurate and credible becomes very important, especially in complex knowledge-intensive tasks. In this paper, we propose a novel framework called Search-in-the-Chain (SearChain) to improve the accuracy, credibility and traceability of LLM-generated content for multi-hop question answering, which is a typical complex knowledge-intensive task. SearChain is a framework that deeply integrates LLM and information retrieval (IR). In SearChain, LLM constructs a chain-of-query, which is the decomposition of the multi-hop question. Each node of the chain is a query-answer pair consisting of an IR-oriented query and the answer generated by LLM for this query. IR verifies, completes, and traces the information of each node of the chain, so as to guide LLM to construct the correct chain-of-query, and finally answer the multi-hop question. SearChain makes LLM change from trying to give a answer to trying to construct the chain-of-query when faced with the multi-hop question, which can stimulate the knowledge-reasoning ability and provides the interface for IR to be deeply involved in reasoning process of LLM. IR interacts with each node of chain-of-query of LLM. It verifies the information of the node and provides the unknown knowledge to LLM, which ensures the accuracy of the whole chain in the process of LLM generating the answer. Besides, the contents returned by LLM to the user include not only the final answer but also the reasoning process for the question, that is, the chain-of-query and the supporting documents retrieved by IR for each node of the chain, which improves the credibility and traceability of the contents generated by LLM. Experimental results show SearChain outperforms related baselines on four multi-hop question-answering datasets.