 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstilling Multi-round Thinking to Text-guided Image Generation
Jan 16, 2024


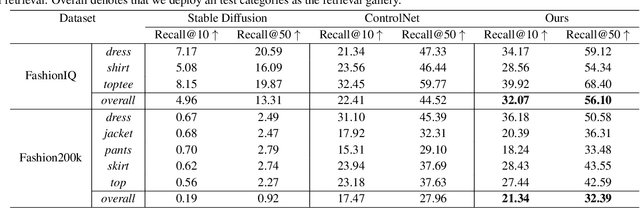
In this paper, we study the text-guided image generation task. Our focus lies in the modification of a reference image, given user text feedback, to imbue it with specific desired properties. Despite recent strides in this field, a persistent challenge remains that single-round optimization often overlooks crucial details, particularly in the realm of fine-grained changes like shoes or sleeves. This misalignment accumulation significantly hampers multi-round customization during interaction. In an attempt to address this challenge, we introduce a new self-supervised regularization into the existing framework, i.e., multi-round regularization. It builds upon the observation that the modification order does not affect the final result. As the name suggests, the multi-round regularization encourages the model to maintain consistency across different modification orders. Specifically, our proposed approach addresses the issue where an initial failure to capture fine-grained details leads to substantial discrepancies after multiple rounds, as opposed to traditional one-round learning. Both qualitative and quantitative experiments show the proposed method achieves high-fidelity generation quality over the text-guided generation task, especially the local modification. Furthermore, we extend the evaluation to semantic alignment with text by applying our method to text-guided retrieval datasets, such as FahisonIQ, where it demonstrates competitive performance.