 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Diffusion for Recommendation
Paper and Code
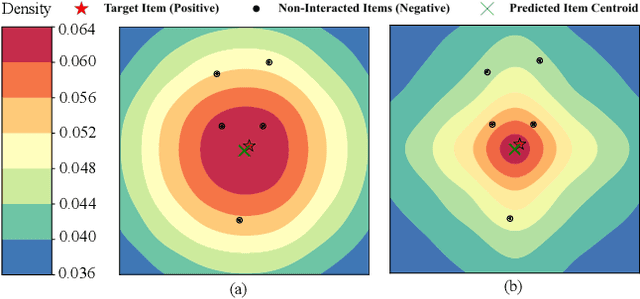
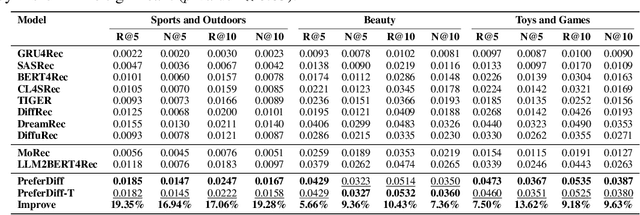

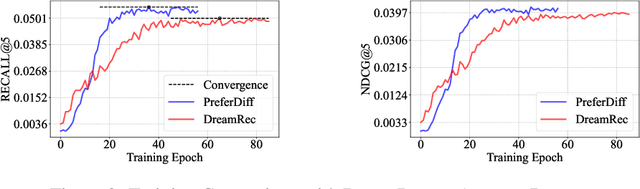
Recommender systems predict personalized item rankings based on user preference distributions derived from historical behavior data. Recently, diffusion models (DMs) have gained attention in recommendation for their ability to model complex distributions, yet current DM-based recommenders often rely on traditional objectives like mean squared error (MSE) or recommendation objectives, which are not optimized for personalized ranking tasks or fail to fully leverage DM's generative potential. To address this, we propose PreferDiff, a tailored optimization objective for DM-based recommenders. PreferDiff transforms BPR into a log-likelihood ranking objective and integrates multiple negative samples to better capture user preferences. Specifically, we employ variational inference to handle the intractability through minimizing the variational upper bound and replaces MSE with cosine error to improve alignment with recommendation tasks. Finally, we balance learning generation and preference to enhance the training stability of DMs. PreferDiff offers three key benefits: it is the first personalized ranking loss designed specifically for DM-based recommenders and it improves ranking and faster convergence by addressing hard negatives. We also prove that it is theoretically connected to Direct Preference Optimization which indicates that it has the potential to align user preferences in DM-based recommenders via generative modeling. Extensive experiments across three benchmarks validate its superior recommendation performance and commendable general sequential recommendation capabilities. Our codes are available at \url{https://github.com/lswhim/PreferDiff}.