 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaFuse: Learn ID Embeddings for Sequential Recommendation in Null Space of Language Embeddings
Apr 29, 2025
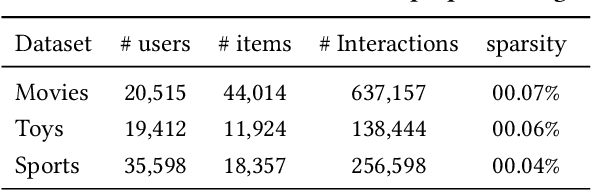

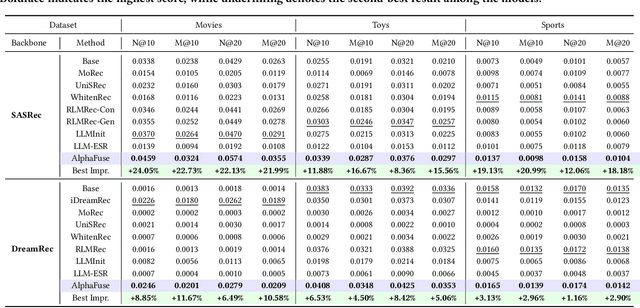
Recent advancements in sequential recommendation have underscored the potential of Large Language Models (LLMs) for enhancing item embeddings. However, existing approaches face three key limitations: 1) the degradation of the semantic space when high-dimensional language embeddings are mapped to lower-dimensional ID embeddings, 2) the underutilization of language embeddings, and 3) the reliance on additional trainable parameters, such as an adapter, to bridge the gap between the semantic and behavior spaces. In this paper, we introduce AlphaFuse, a simple but effective language-guided learning strategy that addresses these challenges by learning ID embeddings within the null space of language embeddings. Specifically, we decompose the semantic space of language embeddings via Singular Value Decomposition (SVD), distinguishing it into a semantic-rich row space and a semantic-sparse null space. Collaborative signals are then injected into the null space, while preserving the rich semantics of the row space. AlphaFuse prevents degradation of the semantic space, integrates the retained language embeddings into the final item embeddings, and eliminates the need for auxiliary trainable modules, enabling seamless adaptation to any sequential recommendation framework. We validate the effectiveness and flexibility of AlphaFuse through extensive experiments on three benchmark datasets, including cold-start user and long-tail settings, showcasing significant improvements in both discriminative and diffusion-based generative sequential recommenders. Our codes and datasets are available at https://github.com/Hugo-Chinn/AlphaFuse.
Preference Diffusion for Recommendation
Oct 17, 2024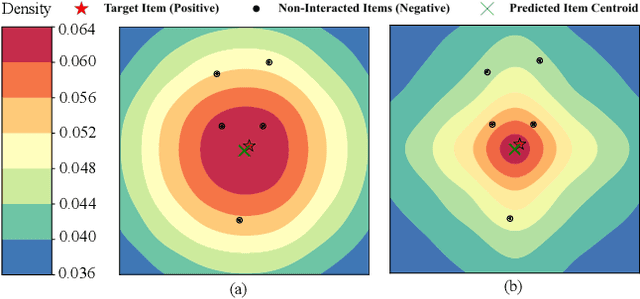
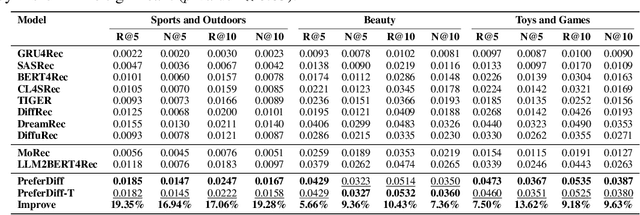

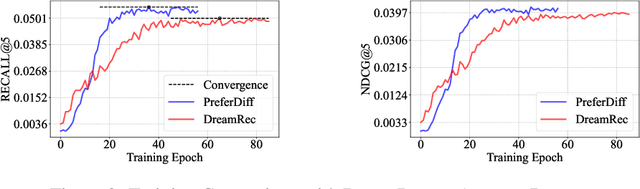
Recommender systems predict personalized item rankings based on user preference distributions derived from historical behavior data. Recently, diffusion models (DMs) have gained attention in recommendation for their ability to model complex distributions, yet current DM-based recommenders often rely on traditional objectives like mean squared error (MSE) or recommendation objectives, which are not optimized for personalized ranking tasks or fail to fully leverage DM's generative potential. To address this, we propose PreferDiff, a tailored optimization objective for DM-based recommenders. PreferDiff transforms BPR into a log-likelihood ranking objective and integrates multiple negative samples to better capture user preferences. Specifically, we employ variational inference to handle the intractability through minimizing the variational upper bound and replaces MSE with cosine error to improve alignment with recommendation tasks. Finally, we balance learning generation and preference to enhance the training stability of DMs. PreferDiff offers three key benefits: it is the first personalized ranking loss designed specifically for DM-based recommenders and it improves ranking and faster convergence by addressing hard negatives. We also prove that it is theoretically connected to Direct Preference Optimization which indicates that it has the potential to align user preferences in DM-based recommenders via generative modeling. Extensive experiments across three benchmarks validate its superior recommendation performance and commendable general sequential recommendation capabilities. Our codes are available at \url{https://github.com/lswhim/PreferDiff}.
Generate and Instantiate What You Prefer: Text-Guided Diffusion for Sequential Recommendation
Oct 17, 2024
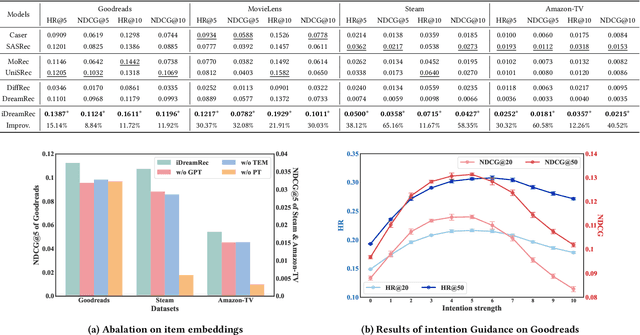

Recent advancements in generative recommendation systems, particularly in the realm of sequential recommendation tasks, have shown promise in enhancing generalization to new items. Among these approaches, diffusion-based generative recommendation has emerged as an effective tool, leveraging its ability to capture data distributions and generate high-quality samples. Despite effectiveness, two primary challenges have been identified: 1) the lack of consistent modeling of data distribution for oracle items; and 2) the difficulty in scaling to more informative control signals beyond historical interactions. These issues stem from the uninformative nature of ID embeddings, which necessitate random initialization and limit the incorporation of additional control signals. To address these limitations, we propose iDreamRe } to involve more concrete prior knowledge to establish item embeddings, particularly through detailed item text descriptions and advanced Text Embedding Models (TEM). More importantly, by converting item descriptions into embeddings aligned with TEM, we enable the integration of intention instructions as control signals to guide the generation of oracle items. Experimental results on four datasets demonstrate that iDreamRec not only outperforms existing diffusion-based generative recommenders but also facilitates the incorporation of intention instructions for more precise and effective recommendation generation.
Multi-View Attention Learning for Residual Disease Prediction of Ovarian Cancer
Jun 26, 2023In the treatment of ovarian cancer, precise residual disease prediction is significant for clinical and surgical decision-making. However, traditional methods are either invasive (e.g., laparoscopy) or time-consuming (e.g., manual analysis). Recently, deep learning methods make many efforts in automatic analysis of medical images. Despite the remarkable progress, most of them underestimated the importance of 3D image information of disease, which might brings a limited performance for residual disease prediction, especially in small-scale datasets. To this end, in this paper, we propose a novel Multi-View Attention Learning (MuVAL) method for residual disease prediction, which focuses on the comprehensive learning of 3D Computed Tomography (CT) images in a multi-view manner. Specifically, we first obtain multi-view of 3D CT images from transverse, coronal and sagittal views. To better represent the image features in a multi-view manner, we further leverage attention mechanism to help find the more relevant slices in each view. Extensive experiments on a dataset of 111 patients show that our method outperforms existing deep-learning methods.