 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaFuse: Learn ID Embeddings for Sequential Recommendation in Null Space of Language Embeddings
Apr 29, 2025

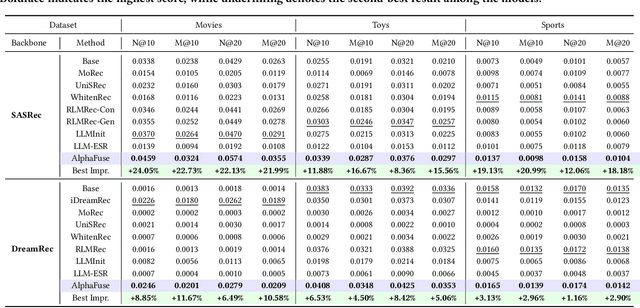
Recent advancements in sequential recommendation have underscored the potential of Large Language Models (LLMs) for enhancing item embeddings. However, existing approaches face three key limitations: 1) the degradation of the semantic space when high-dimensional language embeddings are mapped to lower-dimensional ID embeddings, 2) the underutilization of language embeddings, and 3) the reliance on additional trainable parameters, such as an adapter, to bridge the gap between the semantic and behavior spaces. In this paper, we introduce AlphaFuse, a simple but effective language-guided learning strategy that addresses these challenges by learning ID embeddings within the null space of language embeddings. Specifically, we decompose the semantic space of language embeddings via Singular Value Decomposition (SVD), distinguishing it into a semantic-rich row space and a semantic-sparse null space. Collaborative signals are then injected into the null space, while preserving the rich semantics of the row space. AlphaFuse prevents degradation of the semantic space, integrates the retained language embeddings into the final item embeddings, and eliminates the need for auxiliary trainable modules, enabling seamless adaptation to any sequential recommendation framework. We validate the effectiveness and flexibility of AlphaFuse through extensive experiments on three benchmark datasets, including cold-start user and long-tail settings, showcasing significant improvements in both discriminative and diffusion-based generative sequential recommenders. Our codes and datasets are available at https://github.com/Hugo-Chinn/AlphaFuse.
Generate and Instantiate What You Prefer: Text-Guided Diffusion for Sequential Recommendation
Oct 17, 2024
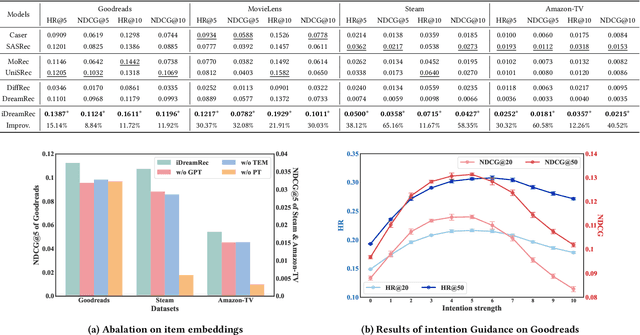

Recent advancements in generative recommendation systems, particularly in the realm of sequential recommendation tasks, have shown promise in enhancing generalization to new items. Among these approaches, diffusion-based generative recommendation has emerged as an effective tool, leveraging its ability to capture data distributions and generate high-quality samples. Despite effectiveness, two primary challenges have been identified: 1) the lack of consistent modeling of data distribution for oracle items; and 2) the difficulty in scaling to more informative control signals beyond historical interactions. These issues stem from the uninformative nature of ID embeddings, which necessitate random initialization and limit the incorporation of additional control signals. To address these limitations, we propose iDreamRe } to involve more concrete prior knowledge to establish item embeddings, particularly through detailed item text descriptions and advanced Text Embedding Models (TEM). More importantly, by converting item descriptions into embeddings aligned with TEM, we enable the integration of intention instructions as control signals to guide the generation of oracle items. Experimental results on four datasets demonstrate that iDreamRec not only outperforms existing diffusion-based generative recommenders but also facilitates the incorporation of intention instructions for more precise and effective recommendation generation.
An Adaptive Dimension Reduction Estimation Method for High-dimensional Bayesian Optimization
Mar 08, 2024Bayesian optimization (BO) has shown impressive results in a variety of applications within low-to-moderate dimensional Euclidean spaces. However, extending BO to high-dimensional settings remains a significant challenge. We address this challenge by proposing a two-step optimization framework. Initially, we identify the effective dimension reduction (EDR) subspace for the objective function using the minimum average variance estimation (MAVE) method. Subsequently, we construct a Gaussian process model within this EDR subspace and optimize it using the expected improvement criterion. Our algorithm offers the flexibility to operate these steps either concurrently or in sequence. In the sequential approach, we meticulously balance the exploration-exploitation trade-off by distributing the sampling budget between subspace estimation and function optimization, and the convergence rate of our algorithm in high-dimensional contexts has been established. Numerical experiments validate the efficacy of our method in challenging scenarios.
Empowering Collaborative Filtering with Principled Adversarial Contrastive Loss
Oct 28, 2023

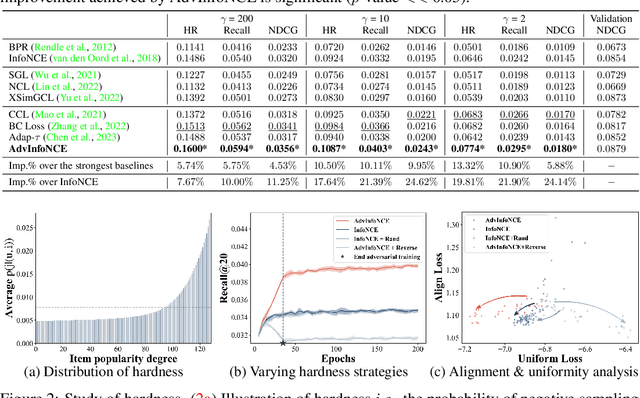

Contrastive Learning (CL) has achieved impressive performance in self-supervised learning tasks, showing superior generalization ability. Inspired by the success, adopting CL into collaborative filtering (CF) is prevailing in semi-supervised top-K recommendations. The basic idea is to routinely conduct heuristic-based data augmentation and apply contrastive losses (e.g., InfoNCE) on the augmented views. Yet, some CF-tailored challenges make this adoption suboptimal, such as the issue of out-of-distribution, the risk of false negatives, and the nature of top-K evaluation. They necessitate the CL-based CF scheme to focus more on mining hard negatives and distinguishing false negatives from the vast unlabeled user-item interactions, for informative contrast signals. Worse still, there is limited understanding of contrastive loss in CF methods, especially w.r.t. its generalization ability. To bridge the gap, we delve into the reasons underpinning the success of contrastive loss in CF, and propose a principled Adversarial InfoNCE loss (AdvInfoNCE), which is a variant of InfoNCE, specially tailored for CF methods. AdvInfoNCE adaptively explores and assigns hardness to each negative instance in an adversarial fashion and further utilizes a fine-grained hardness-aware ranking criterion to empower the recommender's generalization ability. Training CF models with AdvInfoNCE, we validate the effectiveness of AdvInfoNCE on both synthetic and real-world benchmark datasets, thus showing its generalization ability to mitigate out-of-distribution problems. Given the theoretical guarantees and empirical superiority of AdvInfoNCE over most contrastive loss functions, we advocate its adoption as a standard loss in recommender systems, particularly for the out-of-distribution tasks. Codes are available at https://github.com/LehengTHU/AdvInfoNCE.
Boosting Differentiable Causal Discovery via Adaptive Sample Reweighting
Mar 06, 2023



Under stringent model type and variable distribution assumptions, differentiable score-based causal discovery methods learn a directed acyclic graph (DAG) from observational data by evaluating candidate graphs over an average score function. Despite great success in low-dimensional linear systems, it has been observed that these approaches overly exploit easier-to-fit samples, thus inevitably learning spurious edges. Worse still, inherent mostly in these methods the common homogeneity assumption can be easily violated, due to the widespread existence of heterogeneous data in the real world, resulting in performance vulnerability when noise distributions vary. We propose a simple yet effective model-agnostic framework to boost causal discovery performance by dynamically learning the adaptive weights for the Reweighted Score function, ReScore for short, where the weights tailor quantitatively to the importance degree of each sample. Intuitively, we leverage the bilevel optimization scheme to \wx{alternately train a standard DAG learner and reweight samples -- that is, upweight the samples the learner fails to fit and downweight the samples that the learner easily extracts the spurious information from. Extensive experiments on both synthetic and real-world datasets are carried out to validate the effectiveness of ReScore. We observe consistent and significant boosts in structure learning performance. Furthermore, we visualize that ReScore concurrently mitigates the influence of spurious edges and generalizes to heterogeneous data. Finally, we perform the theoretical analysis to guarantee the structure identifiability and the weight adaptive properties of ReScore in linear systems. Our codes are available at https://github.com/anzhang314/ReScore.