 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Reasoning Strength Planning in Large Reasoning Models
Jun 10, 2025Recent studies empirically reveal that large reasoning models (LRMs) can automatically allocate more reasoning strengths (i.e., the number of reasoning tokens) for harder problems, exhibiting difficulty-awareness for better task performance. While this automatic reasoning strength allocation phenomenon has been widely observed, its underlying mechanism remains largely unexplored. To this end, we provide explanations for this phenomenon from the perspective of model activations. We find evidence that LRMs pre-plan the reasoning strengths in their activations even before generation, with this reasoning strength causally controlled by the magnitude of a pre-allocated directional vector. Specifically, we show that the number of reasoning tokens is predictable solely based on the question activations using linear probes, indicating that LRMs estimate the required reasoning strength in advance. We then uncover that LRMs encode this reasoning strength through a pre-allocated directional vector embedded in the activations of the model, where the vector's magnitude modulates the reasoning strength. Subtracting this vector can lead to reduced reasoning token number and performance, while adding this vector can lead to increased reasoning token number and even improved performance. We further reveal that this direction vector consistently yields positive reasoning length prediction, and it modifies the logits of end-of-reasoning token </think> to affect the reasoning length. Finally, we demonstrate two potential applications of our findings: overthinking behavior detection and enabling efficient reasoning on simple problems. Our work provides new insights into the internal mechanisms of reasoning in LRMs and offers practical tools for controlling their reasoning behaviors. Our code is available at https://github.com/AlphaLab-USTC/LRM-plans-CoT.
AlphaSteer: Learning Refusal Steering with Principled Null-Space Constraint
Jun 08, 2025



As LLMs are increasingly deployed in real-world applications, ensuring their ability to refuse malicious prompts, especially jailbreak attacks, is essential for safe and reliable use. Recently, activation steering has emerged as an effective approach for enhancing LLM safety by adding a refusal direction vector to internal activations of LLMs during inference, which will further induce the refusal behaviors of LLMs. However, indiscriminately applying activation steering fundamentally suffers from the trade-off between safety and utility, since the same steering vector can also lead to over-refusal and degraded performance on benign prompts. Although prior efforts, such as vector calibration and conditional steering, have attempted to mitigate this trade-off, their lack of theoretical grounding limits their robustness and effectiveness. To better address the trade-off between safety and utility, we present a theoretically grounded and empirically effective activation steering method called AlphaSteer. Specifically, it considers activation steering as a learnable process with two principled learning objectives: utility preservation and safety enhancement. For utility preservation, it learns to construct a nearly zero vector for steering benign data, with the null-space constraints. For safety enhancement, it learns to construct a refusal direction vector for steering malicious data, with the help of linear regression. Experiments across multiple jailbreak attacks and utility benchmarks demonstrate the effectiveness of AlphaSteer, which significantly improves the safety of LLMs without compromising general capabilities. Our codes are available at https://github.com/AlphaLab-USTC/AlphaSteer.
AgentRecBench: Benchmarking LLM Agent-based Personalized Recommender Systems
May 26, 2025



The emergence of agentic recommender systems powered by Large Language Models (LLMs) represents a paradigm shift in personalized recommendations, leveraging LLMs' advanced reasoning and role-playing capabilities to enable autonomous, adaptive decision-making. Unlike traditional recommendation approaches, agentic recommender systems can dynamically gather and interpret user-item interactions from complex environments, generating robust recommendation strategies that generalize across diverse scenarios. However, the field currently lacks standardized evaluation protocols to systematically assess these methods. To address this critical gap, we propose: (1) an interactive textual recommendation simulator incorporating rich user and item metadata and three typical evaluation scenarios (classic, evolving-interest, and cold-start recommendation tasks); (2) a unified modular framework for developing and studying agentic recommender systems; and (3) the first comprehensive benchmark comparing 10 classical and agentic recommendation methods. Our findings demonstrate the superiority of agentic systems and establish actionable design guidelines for their core components. The benchmark environment has been rigorously validated through an open challenge and remains publicly available with a continuously maintained leaderboard~\footnote[2]{https://tsinghua-fib-lab.github.io/AgentSocietyChallenge/pages/overview.html}, fostering ongoing community engagement and reproducible research. The benchmark is available at: \hyperlink{https://huggingface.co/datasets/SGJQovo/AgentRecBench}{https://huggingface.co/datasets/SGJQovo/AgentRecBench}.
Customizing Language Models with Instance-wise LoRA for Sequential Recommendation
Aug 19, 2024



Sequential recommendation systems predict a user's next item of interest by analyzing past interactions, aligning recommendations with individual preferences. Leveraging the strengths of Large Language Models (LLMs) in knowledge comprehension and reasoning, recent approaches have applied LLMs to sequential recommendation through language generation paradigms. These methods convert user behavior sequences into prompts for LLM fine-tuning, utilizing Low-Rank Adaptation (LoRA) modules to refine recommendations. However, the uniform application of LoRA across diverse user behaviors sometimes fails to capture individual variability, leading to suboptimal performance and negative transfer between disparate sequences. To address these challenges, we propose Instance-wise LoRA (iLoRA), integrating LoRA with the Mixture of Experts (MoE) framework. iLoRA creates a diverse array of experts, each capturing specific aspects of user preferences, and introduces a sequence representation guided gate function. This gate function processes historical interaction sequences to generate enriched representations, guiding the gating network to output customized expert participation weights. This tailored approach mitigates negative transfer and dynamically adjusts to diverse behavior patterns. Extensive experiments on three benchmark datasets demonstrate the effectiveness of iLoRA, highlighting its superior performance compared to existing methods in capturing user-specific preferences and improving recommendation accuracy.
Language Models Encode Collaborative Signals in Recommendation
Jul 07, 2024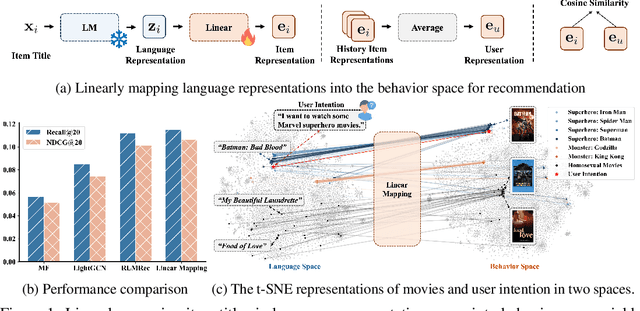
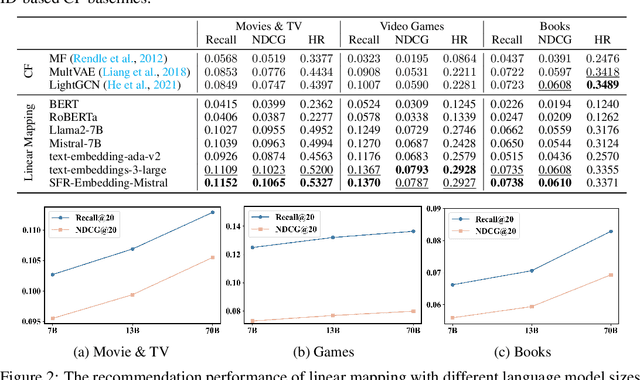

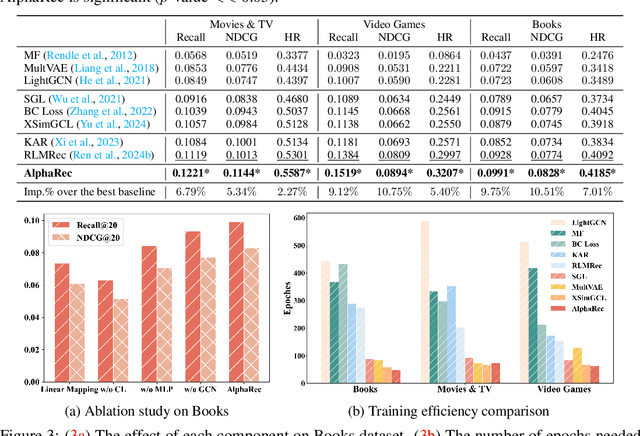
Recent studies empirically indicate that language models (LMs) encode rich world knowledge beyond mere semantics, attracting significant attention across various fields. However, in the recommendation domain, it remains uncertain whether LMs implicitly encode user preference information. Contrary to the prevailing understanding that LMs and traditional recommender models learn two distinct representation spaces due to a huge gap in language and behavior modeling objectives, this work rethinks such understanding and explores extracting a recommendation space directly from the language representation space. Surprisingly, our findings demonstrate that item representations, when linearly mapped from advanced LM representations, yield superior recommendation performance. This outcome suggests the homomorphism between the language representation space and an effective recommendation space, implying that collaborative signals may indeed be encoded within advanced LMs. Motivated by these findings, we propose a simple yet effective collaborative filtering (CF) model named AlphaRec, which utilizes language representations of item textual metadata (e.g., titles) instead of traditional ID-based embeddings. Specifically, AlphaRec is comprised of three main components: a multilayer perceptron (MLP), graph convolution, and contrastive learning (CL) loss function, making it extremely easy to implement and train. Our empirical results show that AlphaRec outperforms leading ID-based CF models on multiple datasets, marking the first instance of such a recommender with text embeddings achieving this level of performance. Moreover, AlphaRec introduces a new language-representation-based CF paradigm with several desirable advantages: being easy to implement, lightweight, rapid convergence, superior zero-shot recommendation abilities in new domains, and being aware of user intention.
On Softmax Direct Preference Optimization for Recommendation
Jun 14, 2024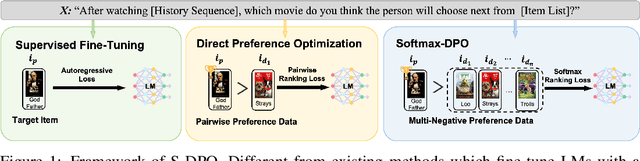
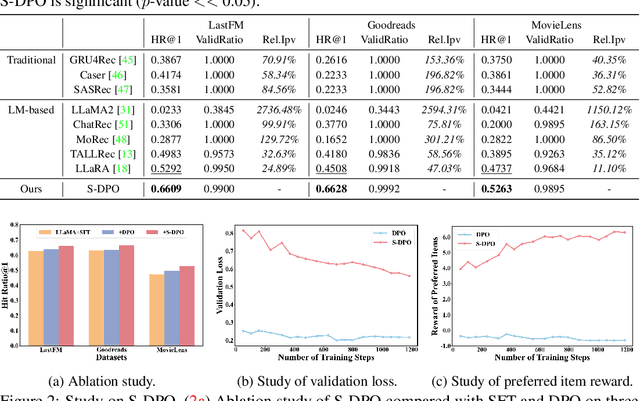
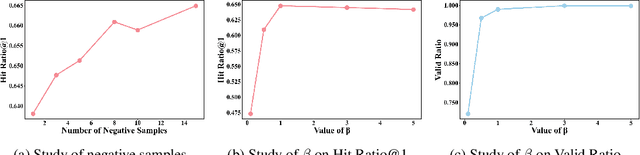
Recommender systems aim to predict personalized rankings based on user preference data. With the rise of Language Models (LMs), LM-based recommenders have been widely explored due to their extensive world knowledge and powerful reasoning abilities. Most of the LM-based recommenders convert historical interactions into language prompts, pairing with a positive item as the target response and fine-tuning LM with a language modeling loss. However, the current objective fails to fully leverage preference data and is not optimized for personalized ranking tasks, which hinders the performance of LM-based recommenders. Inspired by the current advancement of Direct Preference Optimization (DPO) in human preference alignment and the success of softmax loss in recommendations, we propose Softmax-DPO (S-DPO) to instill ranking information into the LM to help LM-based recommenders distinguish preferred items from negatives, rather than solely focusing on positives. Specifically, we incorporate multiple negatives in user preference data and devise an alternative version of DPO loss tailored for LM-based recommenders, connected to softmax sampling strategies. Theoretically, we bridge S-DPO with the softmax loss over negative sampling and find that it has a side effect of mining hard negatives, which assures its exceptional capabilities in recommendation tasks. Empirically, extensive experiments conducted on three real-world datasets demonstrate the superiority of S-DPO to effectively model user preference and further boost recommendation performance while mitigating the data likelihood decline issue of DPO. Our codes are available at https://github.com/chenyuxin1999/S-DPO.
General Debiasing for Graph-based Collaborative Filtering via Adversarial Graph Dropout
Feb 21, 2024Graph neural networks (GNNs) have shown impressive performance in recommender systems, particularly in collaborative filtering (CF). The key lies in aggregating neighborhood information on a user-item interaction graph to enhance user/item representations. However, we have discovered that this aggregation mechanism comes with a drawback, which amplifies biases present in the interaction graph. For instance, a user's interactions with items can be driven by both unbiased true interest and various biased factors like item popularity or exposure. However, the current aggregation approach combines all information, both biased and unbiased, leading to biased representation learning. Consequently, graph-based recommenders can learn distorted views of users/items, hindering the modeling of their true preferences and generalizations. To address this issue, we introduce a novel framework called Adversarial Graph Dropout (AdvDrop). It differentiates between unbiased and biased interactions, enabling unbiased representation learning. For each user/item, AdvDrop employs adversarial learning to split the neighborhood into two views: one with bias-mitigated interactions and the other with bias-aware interactions. After view-specific aggregation, AdvDrop ensures that the bias-mitigated and bias-aware representations remain invariant, shielding them from the influence of bias. We validate AdvDrop's effectiveness on five public datasets that cover both general and specific biases, demonstrating significant improvements. Furthermore, our method exhibits meaningful separation of subgraphs and achieves unbiased representations for graph-based CF models, as revealed by in-depth analysis. Our code is publicly available at https://github.com/Arthurma71/AdvDrop.
Empowering Collaborative Filtering with Principled Adversarial Contrastive Loss
Oct 28, 2023

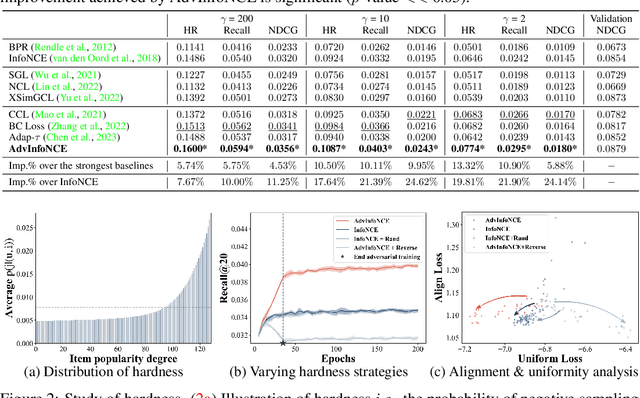

Contrastive Learning (CL) has achieved impressive performance in self-supervised learning tasks, showing superior generalization ability. Inspired by the success, adopting CL into collaborative filtering (CF) is prevailing in semi-supervised top-K recommendations. The basic idea is to routinely conduct heuristic-based data augmentation and apply contrastive losses (e.g., InfoNCE) on the augmented views. Yet, some CF-tailored challenges make this adoption suboptimal, such as the issue of out-of-distribution, the risk of false negatives, and the nature of top-K evaluation. They necessitate the CL-based CF scheme to focus more on mining hard negatives and distinguishing false negatives from the vast unlabeled user-item interactions, for informative contrast signals. Worse still, there is limited understanding of contrastive loss in CF methods, especially w.r.t. its generalization ability. To bridge the gap, we delve into the reasons underpinning the success of contrastive loss in CF, and propose a principled Adversarial InfoNCE loss (AdvInfoNCE), which is a variant of InfoNCE, specially tailored for CF methods. AdvInfoNCE adaptively explores and assigns hardness to each negative instance in an adversarial fashion and further utilizes a fine-grained hardness-aware ranking criterion to empower the recommender's generalization ability. Training CF models with AdvInfoNCE, we validate the effectiveness of AdvInfoNCE on both synthetic and real-world benchmark datasets, thus showing its generalization ability to mitigate out-of-distribution problems. Given the theoretical guarantees and empirical superiority of AdvInfoNCE over most contrastive loss functions, we advocate its adoption as a standard loss in recommender systems, particularly for the out-of-distribution tasks. Codes are available at https://github.com/LehengTHU/AdvInfoNCE.
On Generative Agents in Recommendation
Oct 16, 2023Recommender systems are the cornerstone of today's information dissemination, yet a disconnect between offline metrics and online performance greatly hinders their development. Addressing this challenge, we envision a recommendation simulator, capitalizing on recent breakthroughs in human-level intelligence exhibited by Large Language Models (LLMs). We propose Agent4Rec, a novel movie recommendation simulator, leveraging LLM-empowered generative agents equipped with user profile, memory, and actions modules specifically tailored for the recommender system. In particular, these agents' profile modules are initialized using the MovieLens dataset, capturing users' unique tastes and social traits; memory modules log both factual and emotional memories and are integrated with an emotion-driven reflection mechanism; action modules support a wide variety of behaviors, spanning both taste-driven and emotion-driven actions. Each agent interacts with personalized movie recommendations in a page-by-page manner, relying on a pre-implemented collaborative filtering-based recommendation algorithm. We delve into both the capabilities and limitations of Agent4Rec, aiming to explore an essential research question: to what extent can LLM-empowered generative agents faithfully simulate the behavior of real, autonomous humans in recommender systems? Extensive and multi-faceted evaluations of Agent4Rec highlight both the alignment and deviation between agents and user-personalized preferences. Beyond mere performance comparison, we explore insightful experiments, such as emulating the filter bubble effect and discovering the underlying causal relationships in recommendation tasks. Our codes are available at https://github.com/LehengTHU/Agent4Rec.