 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Encode Collaborative Signals in Recommendation
Paper and Code
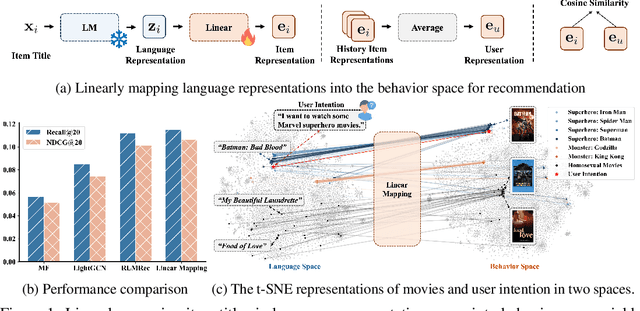
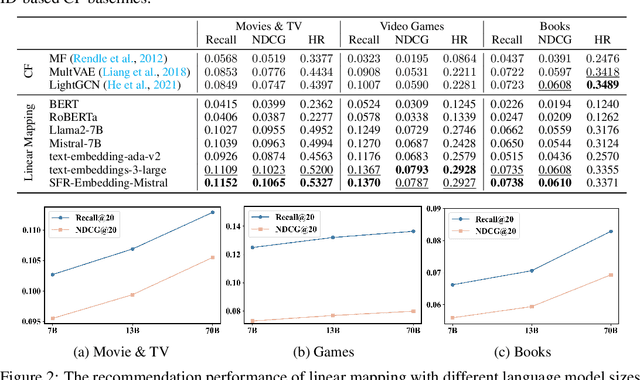

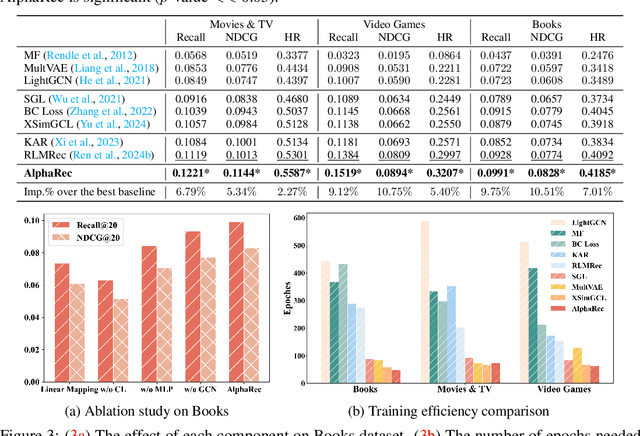
Recent studies empirically indicate that language models (LMs) encode rich world knowledge beyond mere semantics, attracting significant attention across various fields. However, in the recommendation domain, it remains uncertain whether LMs implicitly encode user preference information. Contrary to the prevailing understanding that LMs and traditional recommender models learn two distinct representation spaces due to a huge gap in language and behavior modeling objectives, this work rethinks such understanding and explores extracting a recommendation space directly from the language representation space. Surprisingly, our findings demonstrate that item representations, when linearly mapped from advanced LM representations, yield superior recommendation performance. This outcome suggests the homomorphism between the language representation space and an effective recommendation space, implying that collaborative signals may indeed be encoded within advanced LMs. Motivated by these findings, we propose a simple yet effective collaborative filtering (CF) model named AlphaRec, which utilizes language representations of item textual metadata (e.g., titles) instead of traditional ID-based embeddings. Specifically, AlphaRec is comprised of three main components: a multilayer perceptron (MLP), graph convolution, and contrastive learning (CL) loss function, making it extremely easy to implement and train. Our empirical results show that AlphaRec outperforms leading ID-based CF models on multiple datasets, marking the first instance of such a recommender with text embeddings achieving this level of performance. Moreover, AlphaRec introduces a new language-representation-based CF paradigm with several desirable advantages: being easy to implement, lightweight, rapid convergence, superior zero-shot recommendation abilities in new domains, and being aware of user intention.