 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-ICSO-NAS: Shifting Gears between Gradient and Swarm for Robust Neural Architecture Search
Apr 01, 2026Neural Architecture Search (NAS) has become a pivotal technique in automated machine learning. Evolutionary Algorithm (EA)-based methods demonstrate superior search quality but suffer from prohibitive computational costs, while gradient-based approaches like DARTS offer high efficiency but are prone to premature convergence and performance collapse. To bridge this gap, we propose G-ICSO-NAS, a hybrid framework implementing a three-stage optimization strategy. The Warm-up Phase pre-trains supernet weights ($w$) via differentiable methods while architecture parameters ($α$) remain frozen. The Exploration Phase adopts a hybrid co-optimization mechanism: an Improved Competitive Swarm Optimizer (ICSO) with diversity-aware fitness navigates the architecture space to update $α$, while gradient descent concurrently updates $w$. The Stability Phase employs fine-grained gradient-based search with early stopping to converge to the optimal architecture. By synergizing ICSO's global navigation capability with differentiable methods' efficiency, G-ICSO-NAS achieves remarkable performance with minimal cost. In the context of the DARTS search space, an accuracy of 97.46\% is achieved on CIFAR-10 with a computational budget of just 0.15 GPU-Days. The method also exhibits strong transfer potential, recording accuracies of 83.1\% (CIFAR-100) and 75.02\% (ImageNet). Furthermore, regarding the NAS-Bench-201 benchmark, G-ICSO-NAS is shown to deliver state-of-the-art results across all evaluated datasets.
NExT-Mol: 3D Diffusion Meets 1D Language Modeling for 3D Molecule Generation
Feb 18, 20253D molecule generation is crucial for drug discovery and material design. While prior efforts focus on 3D diffusion models for their benefits in modeling continuous 3D conformers, they overlook the advantages of 1D SELFIES-based Language Models (LMs), which can generate 100% valid molecules and leverage the billion-scale 1D molecule datasets. To combine these advantages for 3D molecule generation, we propose a foundation model -- NExT-Mol: 3D Diffusion Meets 1D Language Modeling for 3D Molecule Generation. NExT-Mol uses an extensively pretrained molecule LM for 1D molecule generation, and subsequently predicts the generated molecule's 3D conformers with a 3D diffusion model. We enhance NExT-Mol's performance by scaling up the LM's model size, refining the diffusion neural architecture, and applying 1D to 3D transfer learning. Notably, our 1D molecule LM significantly outperforms baselines in distributional similarity while ensuring validity, and our 3D diffusion model achieves leading performances in conformer prediction. Given these improvements in 1D and 3D modeling, NExT-Mol achieves a 26% relative improvement in 3D FCD for de novo 3D generation on GEOM-DRUGS, and a 13% average relative gain for conditional 3D generation on QM9-2014. Our codes and pretrained checkpoints are available at https://github.com/acharkq/NExT-Mol.
On Softmax Direct Preference Optimization for Recommendation
Jun 14, 2024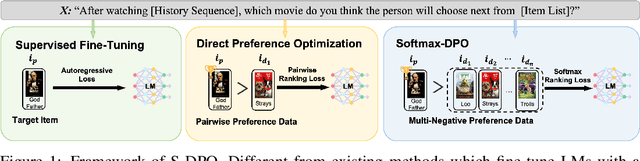
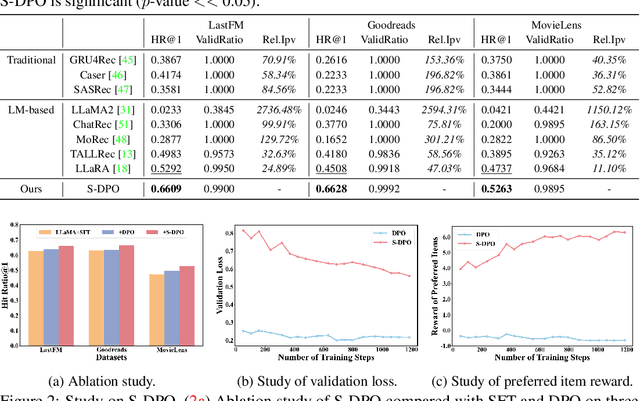
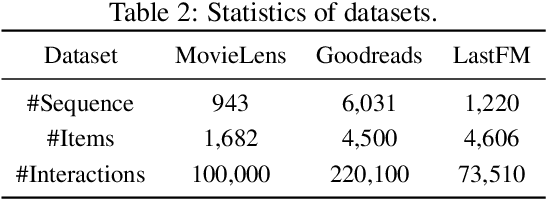
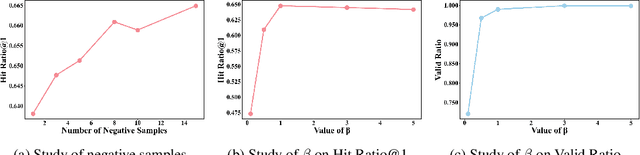
Recommender systems aim to predict personalized rankings based on user preference data. With the rise of Language Models (LMs), LM-based recommenders have been widely explored due to their extensive world knowledge and powerful reasoning abilities. Most of the LM-based recommenders convert historical interactions into language prompts, pairing with a positive item as the target response and fine-tuning LM with a language modeling loss. However, the current objective fails to fully leverage preference data and is not optimized for personalized ranking tasks, which hinders the performance of LM-based recommenders. Inspired by the current advancement of Direct Preference Optimization (DPO) in human preference alignment and the success of softmax loss in recommendations, we propose Softmax-DPO (S-DPO) to instill ranking information into the LM to help LM-based recommenders distinguish preferred items from negatives, rather than solely focusing on positives. Specifically, we incorporate multiple negatives in user preference data and devise an alternative version of DPO loss tailored for LM-based recommenders, connected to softmax sampling strategies. Theoretically, we bridge S-DPO with the softmax loss over negative sampling and find that it has a side effect of mining hard negatives, which assures its exceptional capabilities in recommendation tasks. Empirically, extensive experiments conducted on three real-world datasets demonstrate the superiority of S-DPO to effectively model user preference and further boost recommendation performance while mitigating the data likelihood decline issue of DPO. Our codes are available at https://github.com/chenyuxin1999/S-DPO.
Introducing Competitive Mechanism to Differential Evolution for Numerical Optimization
Jun 08, 2024



This paper introduces a novel competitive mechanism into differential evolution (DE), presenting an effective DE variant named competitive DE (CDE). CDE features a simple yet efficient mutation strategy: DE/winner-to-best/1. Essentially, the proposed DE/winner-to-best/1 strategy can be recognized as an intelligent integration of the existing mutation strategies of DE/rand-to-best/1 and DE/cur-to-best/1. The incorporation of DE/winner-to-best/1 and the competitive mechanism provide new avenues for advancing DE techniques. Moreover, in CDE, the scaling factor $F$ and mutation rate $Cr$ are determined by a random number generator following a normal distribution, as suggested by previous research. To investigate the performance of the proposed CDE, comprehensive numerical experiments are conducted on CEC2017 and engineering simulation optimization tasks, with CMA-ES, JADE, and other state-of-the-art optimizers and DE variants employed as competitor algorithms. The experimental results and statistical analyses highlight the promising potential of CDE as an alternative optimizer for addressing diverse optimization challenges.
ReactXT: Understanding Molecular "Reaction-ship" via Reaction-Contextualized Molecule-Text Pretraining
May 23, 2024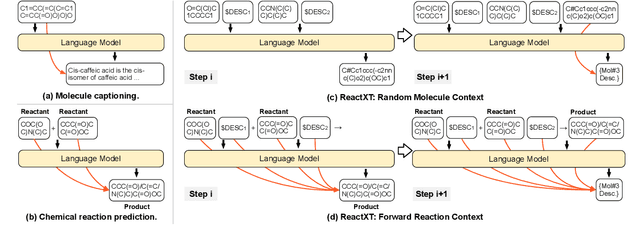

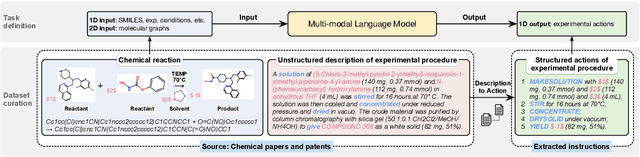
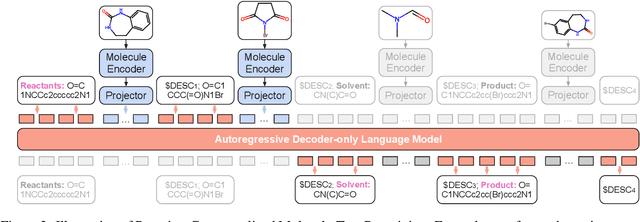
Molecule-text modeling, which aims to facilitate molecule-relevant tasks with a textual interface and textual knowledge, is an emerging research direction. Beyond single molecules, studying reaction-text modeling holds promise for helping the synthesis of new materials and drugs. However, previous works mostly neglect reaction-text modeling: they primarily focus on modeling individual molecule-text pairs or learning chemical reactions without texts in context. Additionally, one key task of reaction-text modeling -- experimental procedure prediction -- is less explored due to the absence of an open-source dataset. The task is to predict step-by-step actions of conducting chemical experiments and is crucial to automating chemical synthesis. To resolve the challenges above, we propose a new pretraining method, ReactXT, for reaction-text modeling, and a new dataset, OpenExp, for experimental procedure prediction. Specifically, ReactXT features three types of input contexts to incrementally pretrain LMs. Each of the three input contexts corresponds to a pretraining task to improve the text-based understanding of either reactions or single molecules. ReactXT demonstrates consistent improvements in experimental procedure prediction and molecule captioning and offers competitive results in retrosynthesis. Our code is available at https://github.com/syr-cn/ReactXT.
ProtT3: Protein-to-Text Generation for Text-based Protein Understanding
May 21, 2024


Language Models (LMs) excel in understanding textual descriptions of proteins, as evident in biomedical question-answering tasks. However, their capability falters with raw protein data, such as amino acid sequences, due to a deficit in pretraining on such data. Conversely, Protein Language Models (PLMs) can understand and convert protein data into high-quality representations, but struggle to process texts. To address their limitations, we introduce ProtT3, a framework for Protein-to-Text Generation for Text-based Protein Understanding. ProtT3 empowers an LM to understand protein sequences of amino acids by incorporating a PLM as its protein understanding module, enabling effective protein-to-text generation. This collaboration between PLM and LM is facilitated by a cross-modal projector (i.e., Q-Former) that bridges the modality gap between the PLM's representation space and the LM's input space. Unlike previous studies focusing on protein property prediction and protein-text retrieval, we delve into the largely unexplored field of protein-to-text generation. To facilitate comprehensive benchmarks and promote future research, we establish quantitative evaluations for protein-text modeling tasks, including protein captioning, protein question-answering, and protein-text retrieval. Our experiments show that ProtT3 substantially surpasses current baselines, with ablation studies further highlighting the efficacy of its core components. Our code is available at https://github.com/acharkq/ProtT3.
Adaptive Patching for High-resolution Image Segmentation with Transformers
Apr 15, 2024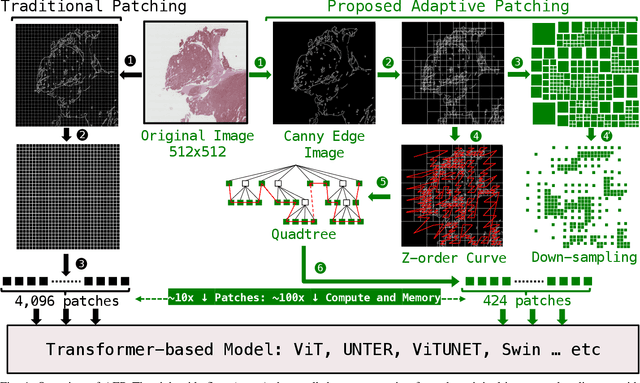



Attention-based models are proliferating in the space of image analytics, including segmentation. The standard method of feeding images to transformer encoders is to divide the images into patches and then feed the patches to the model as a linear sequence of tokens. For high-resolution images, e.g. microscopic pathology images, the quadratic compute and memory cost prohibits the use of an attention-based model, if we are to use smaller patch sizes that are favorable in segmentation. The solution is to either use custom complex multi-resolution models or approximate attention schemes. We take inspiration from Adapative Mesh Refinement (AMR) methods in HPC by adaptively patching the images, as a pre-processing step, based on the image details to reduce the number of patches being fed to the model, by orders of magnitude. This method has a negligible overhead, and works seamlessly with any attention-based model, i.e. it is a pre-processing step that can be adopted by any attention-based model without friction. We demonstrate superior segmentation quality over SoTA segmentation models for real-world pathology datasets while gaining a geomean speedup of $6.9\times$ for resolutions up to $64K^2$, on up to $2,048$ GPUs.
Rethinking Tokenizer and Decoder in Masked Graph Modeling for Molecules
Oct 23, 2023



Masked graph modeling excels in the self-supervised representation learning of molecular graphs. Scrutinizing previous studies, we can reveal a common scheme consisting of three key components: (1) graph tokenizer, which breaks a molecular graph into smaller fragments (i.e., subgraphs) and converts them into tokens; (2) graph masking, which corrupts the graph with masks; (3) graph autoencoder, which first applies an encoder on the masked graph to generate the representations, and then employs a decoder on the representations to recover the tokens of the original graph. However, the previous MGM studies focus extensively on graph masking and encoder, while there is limited understanding of tokenizer and decoder. To bridge the gap, we first summarize popular molecule tokenizers at the granularity of node, edge, motif, and Graph Neural Networks (GNNs), and then examine their roles as the MGM's reconstruction targets. Further, we explore the potential of adopting an expressive decoder in MGM. Our results show that a subgraph-level tokenizer and a sufficiently expressive decoder with remask decoding have a large impact on the encoder's representation learning. Finally, we propose a novel MGM method SimSGT, featuring a Simple GNN-based Tokenizer (SGT) and an effective decoding strategy. We empirically validate that our method outperforms the existing molecule self-supervised learning methods. Our codes and checkpoints are available at https://github.com/syr-cn/SimSGT.
ReLM: Leveraging Language Models for Enhanced Chemical Reaction Prediction
Oct 20, 2023



Predicting chemical reactions, a fundamental challenge in chemistry, involves forecasting the resulting products from a given reaction process. Conventional techniques, notably those employing Graph Neural Networks (GNNs), are often limited by insufficient training data and their inability to utilize textual information, undermining their applicability in real-world applications. In this work, we propose ReLM, a novel framework that leverages the chemical knowledge encoded in language models (LMs) to assist GNNs, thereby enhancing the accuracy of real-world chemical reaction predictions. To further enhance the model's robustness and interpretability, we incorporate the confidence score strategy, enabling the LMs to self-assess the reliability of their predictions. Our experimental results demonstrate that ReLM improves the performance of state-of-the-art GNN-based methods across various chemical reaction datasets, especially in out-of-distribution settings. Codes are available at https://github.com/syr-cn/ReLM.
Accelerating the Evolutionary Algorithms by Gaussian Process Regression with $ε$-greedy acquisition function
Oct 13, 2022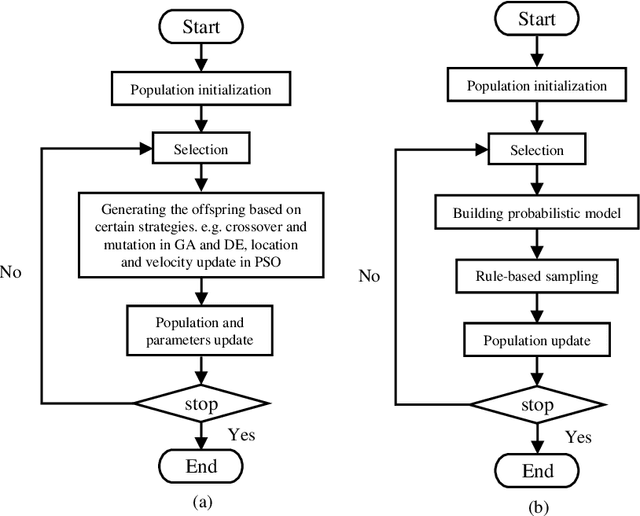
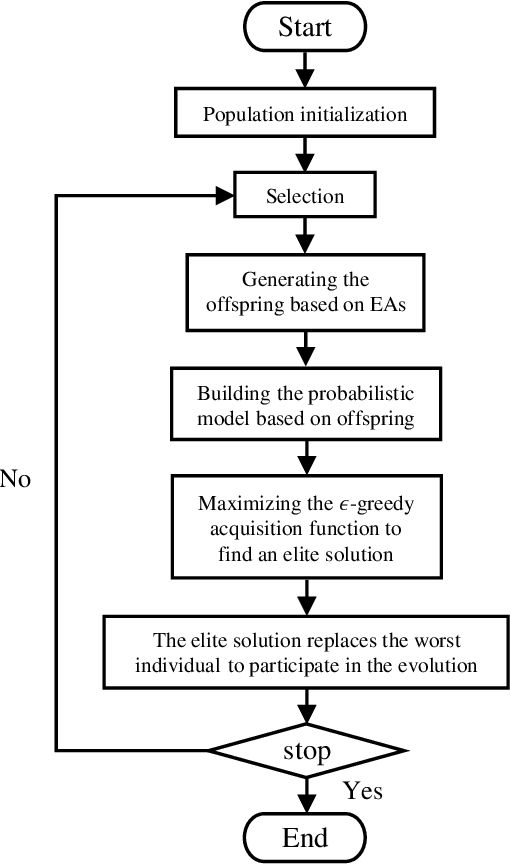
In this paper, we propose a novel method to estimate the elite individual to accelerate the convergence of optimization. Inspired by the Bayesian Optimization Algorithm (BOA), the Gaussian Process Regression (GPR) is applied to approximate the fitness landscape of original problems based on every generation of optimization. And simple but efficient $\epsilon$-greedy acquisition function is employed to find a promising solution in the surrogate model. Proximity Optimal Principle (POP) states that well-performed solutions have a similar structure, and there is a high probability of better solutions existing around the elite individual. Based on this hypothesis, in each generation of optimization, we replace the worst individual in Evolutionary Algorithms (EAs) with the elite individual to participate in the evolution process. To illustrate the scalability of our proposal, we combine our proposal with the Genetic Algorithm (GA), Differential Evolution (DE), and CMA-ES. Experimental results in CEC2013 benchmark functions show our proposal has a broad prospect to estimate the elite individual and accelerate the convergence of optimization.