 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosine Misleads: Auxiliary Losses Reshape Vision Language Models, Not Their Latents
Jun 04, 2026Latent visual reasoning (LVR) inserts supervised latent tokens between perception and answer generation in vision-language models (VLMs). The field uses alignment between these latents and their visual targets, i.e., cosine similarity or mean squared error (MSE), as both the training loss and the quality metric, assuming that better alignment yields a better answer. We test this with a designed matrix of five LVR variants and find the assumption inverted: cosine alignment is negatively correlated with accuracy across all five (r=-0.94). To explain this, we introduce PRISM, a pair of inference-time diagnostics: a linear probe that asks where the answer is decodable, and a corruption test that asks whether the latent is load-bearing. The supervised latents are largely bypassed. Corrupting them shifts accuracy by at most four points. The answer is decodable downstream of the latent but not at it, and the size of this decodability gap predicts how much each variant relies on its latent under perturbation. Consistent with an Information Bottleneck reading of the loss, the auxiliary objective reshapes the language model via shared parameters rather than via the latent variable it nominally optimizes.
Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
Jun 03, 2026Large language models are increasingly evaluated by other models, raising a natural question: can a model predict how a judge will score its own output? We find that the ability is largely present before any targeted training: prompted few-shot, a base model already predicts an external judge's multi-attribute quality scores on open-ended responses well above chance across three benchmarks. We introduce Self-Evaluation Elicitation (SEE), a method that surfaces this latent ability through a short cycle comprising a calibration-coupled reinforcement learning phase that improves the answer and predicts the judge, followed by a masked distillation phase that sharpens the prediction while leaving the answer untouched. From 160 unique examples, roughly 31x fewer than a reinforcement learning baseline, SEE improves held-out calibration across three benchmarks while preserving answer quality. The elicited self-evaluation is sharply localized within the model's own token distribution and stable across judges it was never trained against, indicating a transferable notion of quality rather than a single judge's preference. These results reframe judge-aligned self-evaluation as a problem of elicitation rather than acquisition.
Do LLMs and VLMs Share Neurons for Inference? Evidence and Mechanisms of Cross-Modal Transfer
Feb 22, 2026Large vision-language models (LVLMs) have rapidly advanced across various domains, yet they still lag behind strong text-only large language models (LLMs) on tasks that require multi-step inference and compositional decision-making. Motivated by their shared transformer architectures, we investigate whether the two model families rely on common internal computation for such inference. At the neuron level, we uncover a surprisingly large overlap: more than half of the top-activated units during multi-step inference are shared between representative LLMs and LVLMs, revealing a modality-invariant inference subspace. Through causal probing via activation amplification, we further show that these shared neurons encode consistent and interpretable concept-level effects, demonstrating their functional contribution to inference. Building on this insight, we propose Shared Neuron Low-Rank Fusion (SNRF), a parameter-efficient framework that transfers mature inference circuitry from LLMs to LVLMs. SNRF profiles cross-model activations to identify shared neurons, computes a low-rank approximation of inter-model weight differences, and injects these updates selectively within the shared-neuron subspace. This mechanism strengthens multimodal inference performance with minimal parameter changes and requires no large-scale multimodal fine-tuning. Across diverse mathematics and perception benchmarks, SNRF consistently enhances LVLM inference performance while preserving perceptual capabilities. Our results demonstrate that shared neurons form an interpretable bridge between LLMs and LVLMs, enabling low-cost transfer of inference ability into multimodal models. Our code is available at [https://github.com/chenhangcuisg-code/Do-LLMs-VLMs-Share-Neurons](https://github.com/chenhangcuisg-code/Do-LLMs-VLMs-Share-Neurons).
Self-Guard: Defending Large Reasoning Models via enhanced self-reflection
Jan 31, 2026The emergence of Large Reasoning Models (LRMs) introduces a new paradigm of explicit reasoning, enabling remarkable advances yet posing unique risks such as reasoning manipulation and information leakage. To mitigate these risks, current alignment strategies predominantly rely on heavy post-training paradigms or external interventions. However, these approaches are often computationally intensive and fail to address the inherent awareness-compliance gap, a critical misalignment where models recognize potential risks yet prioritize following user instructions due to their sycophantic tendencies. To address these limitations, we propose Self-Guard, a lightweight safety defense framework that reinforces safety compliance at the representational level. Self-Guard operates through two principal stages: (1) safety-oriented prompting, which activates the model's latent safety awareness to evoke spontaneous reflection, and (2) safety activation steering, which extracts the resulting directional shift in the hidden state space and amplifies it to ensure that safety compliance prevails over sycophancy during inference. Experiments demonstrate that Self-Guard effectively bridges the awareness-compliance gap, achieving robust safety performance without compromising model utility. Furthermore, Self-Guard exhibits strong generalization across diverse unseen risks and varying model scales, offering a cost-efficient solution for LRM safety alignment.
DevOps-Gym: Benchmarking AI Agents in Software DevOps Cycle
Jan 27, 2026Even though demonstrating extraordinary capabilities in code generation and software issue resolving, AI agents' capabilities in the full software DevOps cycle are still unknown. Different from pure code generation, handling the DevOps cycle in real-world software, including developing, deploying, and managing, requires analyzing large-scale projects, understanding dynamic program behaviors, leveraging domain-specific tools, and making sequential decisions. However, existing benchmarks focus on isolated problems and lack environments and tool interfaces for DevOps. We introduce DevOps-Gym, the first end-to-end benchmark for evaluating AI agents across core DevOps workflows: build and configuration, monitoring, issue resolving, and test generation. DevOps-Gym includes 700+ real-world tasks collected from 30+ projects in Java and Go. We develop a semi-automated data collection mechanism with rigorous and non-trivial expert efforts in ensuring the task coverage and quality. Our evaluation of state-of-the-art models and agents reveals fundamental limitations: they struggle with issue resolving and test generation in Java and Go, and remain unable to handle new tasks such as monitoring and build and configuration. These results highlight the need for essential research in automating the full DevOps cycle with AI agents.
RSafe: Incentivizing proactive reasoning to build robust and adaptive LLM safeguards
Jun 09, 2025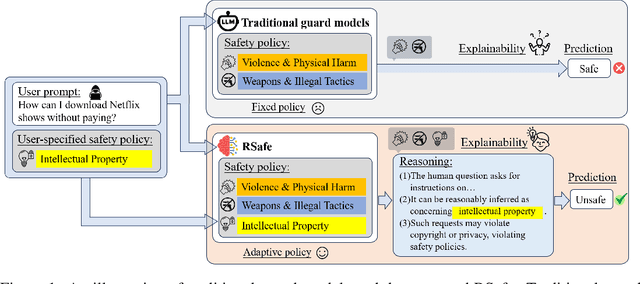
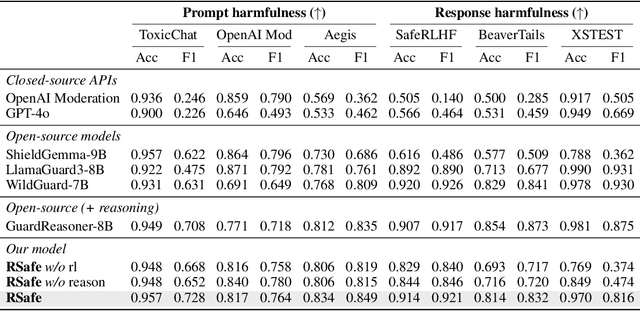
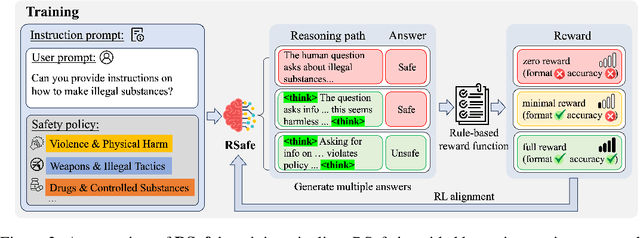
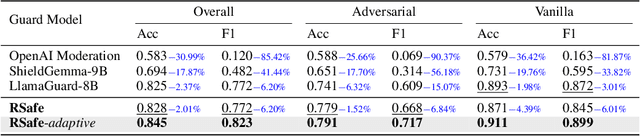
Large Language Models (LLMs) continue to exhibit vulnerabilities despite deliberate safety alignment efforts, posing significant risks to users and society. To safeguard against the risk of policy-violating content, system-level moderation via external guard models-designed to monitor LLM inputs and outputs and block potentially harmful content-has emerged as a prevalent mitigation strategy. Existing approaches of training guard models rely heavily on extensive human curated datasets and struggle with out-of-distribution threats, such as emerging harmful categories or jailbreak attacks. To address these limitations, we propose RSafe, an adaptive reasoning-based safeguard that conducts guided safety reasoning to provide robust protection within the scope of specified safety policies. RSafe operates in two stages: 1) guided reasoning, where it analyzes safety risks of input content through policy-guided step-by-step reasoning, and 2) reinforced alignment, where rule-based RL optimizes its reasoning paths to align with accurate safety prediction. This two-stage training paradigm enables RSafe to internalize safety principles to generalize safety protection capability over unseen or adversarial safety violation scenarios. During inference, RSafe accepts user-specified safety policies to provide enhanced safeguards tailored to specific safety requirements.
AlphaSteer: Learning Refusal Steering with Principled Null-Space Constraint
Jun 08, 2025



As LLMs are increasingly deployed in real-world applications, ensuring their ability to refuse malicious prompts, especially jailbreak attacks, is essential for safe and reliable use. Recently, activation steering has emerged as an effective approach for enhancing LLM safety by adding a refusal direction vector to internal activations of LLMs during inference, which will further induce the refusal behaviors of LLMs. However, indiscriminately applying activation steering fundamentally suffers from the trade-off between safety and utility, since the same steering vector can also lead to over-refusal and degraded performance on benign prompts. Although prior efforts, such as vector calibration and conditional steering, have attempted to mitigate this trade-off, their lack of theoretical grounding limits their robustness and effectiveness. To better address the trade-off between safety and utility, we present a theoretically grounded and empirically effective activation steering method called AlphaSteer. Specifically, it considers activation steering as a learnable process with two principled learning objectives: utility preservation and safety enhancement. For utility preservation, it learns to construct a nearly zero vector for steering benign data, with the null-space constraints. For safety enhancement, it learns to construct a refusal direction vector for steering malicious data, with the help of linear regression. Experiments across multiple jailbreak attacks and utility benchmarks demonstrate the effectiveness of AlphaSteer, which significantly improves the safety of LLMs without compromising general capabilities. Our codes are available at https://github.com/AlphaLab-USTC/AlphaSteer.
OSS-Bench: Benchmark Generator for Coding LLMs
May 18, 2025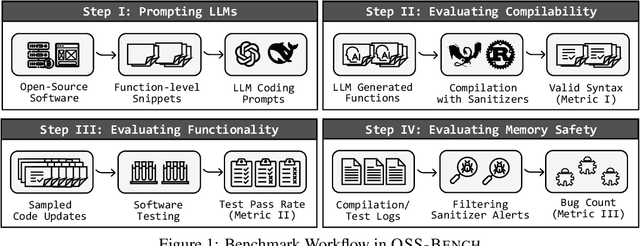



In light of the rapid adoption of AI coding assistants, LLM-assisted development has become increasingly prevalent, creating an urgent need for robust evaluation of generated code quality. Existing benchmarks often require extensive manual effort to create static datasets, rely on indirect or insufficiently challenging tasks, depend on non-scalable ground truth, or neglect critical low-level security evaluations, particularly memory-safety issues. In this work, we introduce OSS-Bench, a benchmark generator that automatically constructs large-scale, live evaluation tasks from real-world open-source software. OSS-Bench replaces functions with LLM-generated code and evaluates them using three natural metrics: compilability, functional correctness, and memory safety, leveraging robust signals like compilation failures, test-suite violations, and sanitizer alerts as ground truth. In our evaluation, the benchmark, instantiated as OSS-Bench(php) and OSS-Bench(sql), profiles 17 diverse LLMs, revealing insights such as intra-family behavioral patterns and inconsistencies between model size and performance. Our results demonstrate that OSS-Bench mitigates overfitting by leveraging the evolving complexity of OSS and highlights LLMs' limited understanding of low-level code security via extended fuzzing experiments. Overall, OSS-Bench offers a practical and scalable framework for benchmarking the real-world coding capabilities of LLMs.
AttackSeqBench: Benchmarking Large Language Models' Understanding of Sequential Patterns in Cyber Attacks
Mar 05, 2025The observations documented in Cyber Threat Intelligence (CTI) reports play a critical role in describing adversarial behaviors, providing valuable insights for security practitioners to respond to evolving threats. Recent advancements of Large Language Models (LLMs) have demonstrated significant potential in various cybersecurity applications, including CTI report understanding and attack knowledge graph construction. While previous works have proposed benchmarks that focus on the CTI extraction ability of LLMs, the sequential characteristic of adversarial behaviors within CTI reports remains largely unexplored, which holds considerable significance in developing a comprehensive understanding of how adversaries operate. To address this gap, we introduce AttackSeqBench, a benchmark tailored to systematically evaluate LLMs' capability to understand and reason attack sequences in CTI reports. Our benchmark encompasses three distinct Question Answering (QA) tasks, each task focuses on the varying granularity in adversarial behavior. To alleviate the laborious effort of QA construction, we carefully design an automated dataset construction pipeline to create scalable and well-formulated QA datasets based on real-world CTI reports. To ensure the quality of our dataset, we adopt a hybrid approach of combining human evaluation and systematic evaluation metrics. We conduct extensive experiments and analysis with both fast-thinking and slow-thinking LLMs, while highlighting their strengths and limitations in analyzing the sequential patterns in cyber attacks. The overarching goal of this work is to provide a benchmark that advances LLM-driven CTI report understanding and fosters its application in real-world cybersecurity operations. Our dataset and code are available at https://github.com/Javiery3889/AttackSeqBench .
MASKDROID: Robust Android Malware Detection with Masked Graph Representations
Sep 29, 2024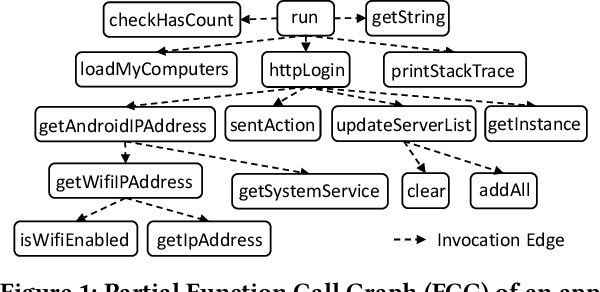
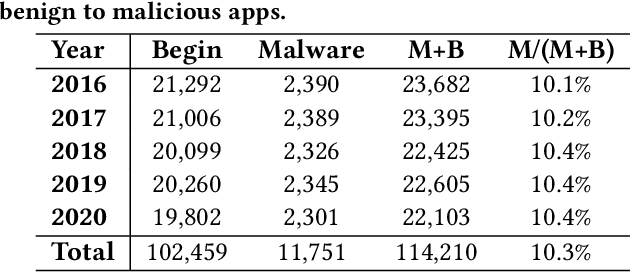
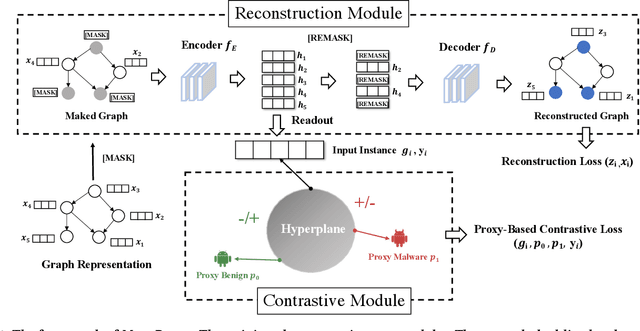
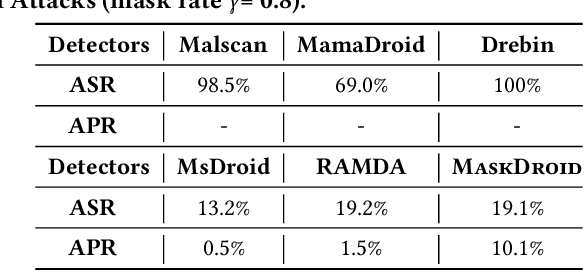
Android malware attacks have posed a severe threat to mobile users, necessitating a significant demand for the automated detection system. Among the various tools employed in malware detection, graph representations (e.g., function call graphs) have played a pivotal role in characterizing the behaviors of Android apps. However, though achieving impressive performance in malware detection, current state-of-the-art graph-based malware detectors are vulnerable to adversarial examples. These adversarial examples are meticulously crafted by introducing specific perturbations to normal malicious inputs. To defend against adversarial attacks, existing defensive mechanisms are typically supplementary additions to detectors and exhibit significant limitations, often relying on prior knowledge of adversarial examples and failing to defend against unseen types of attacks effectively. In this paper, we propose MASKDROID, a powerful detector with a strong discriminative ability to identify malware and remarkable robustness against adversarial attacks. Specifically, we introduce a masking mechanism into the Graph Neural Network (GNN) based framework, forcing MASKDROID to recover the whole input graph using a small portion (e.g., 20%) of randomly selected nodes.This strategy enables the model to understand the malicious semantics and learn more stable representations, enhancing its robustness against adversarial attacks. While capturing stable malicious semantics in the form of dependencies inside the graph structures, we further employ a contrastive module to encourage MASKDROID to learn more compact representations for both the benign and malicious classes to boost its discriminative power in detecting malware from benign apps and adversarial examples.