 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongSeeker: Elastic Context Orchestration for Long-Horizon Search Agents
May 06, 2026Long-horizon search agents must manage a rapidly growing working context as they reason, call tools, and observe information. Naively accumulating all intermediate content can overwhelm the agent, increasing costs and the risk of errors. We propose that effective context management should be adaptive: parts of the agent's trajectory are maintained at different levels of detail depending on their current relevance to the task. To operationalize this principle, we introduce Context-ReAct, a general agentic paradigm for elastic context orchestration that integrates reasoning, context management, and tool use in a unified loop. Context-ReAct provides five atomic operations: Skip, Compress, Rollback, Snippet and Delete, which allow the agent to dynamically reshape its working context, preserving important evidence, summarizing resolved information, discarding unhelpful branches, and controlling context size. We prove that the Compress operator is expressively complete, while the other specialized operators provide efficiency and fidelity guarantees that reduce generation cost and hallucination risk. Building on this paradigm, we develop LongSeeker, a long-horizon search agent fine-tuned from Qwen3-30B-A3B on 10k synthesized trajectories. Across four representative search benchmarks, LongSeeker achieves 61.5% on BrowseComp and 62.5% on BrowseComp-ZH, substantially outperforming Tongyi DeepResearch (43.2% and 46.7%) and AgentFold (36.2% and 47.3%). These results highlight the potential of adaptive context management, showing that agents can achieve more reliable and efficient long-horizon reasoning by actively shaping their working memory.
OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data
Mar 16, 2026Deep search capabilities have become an indispensable competency for frontier Large Language Model (LLM) agents, yet the development of high-performance search agents remains dominated by industrial giants due to a lack of transparent, high-quality training data. This persistent data scarcity has fundamentally hindered the progress of the broader research community in developing and innovating within this domain. To bridge this gap, we introduce OpenSeeker, the first fully open-source search agent (i.e., model and data) that achieves frontier-level performance through two core technical innovations: (1) Fact-grounded scalable controllable QA synthesis, which reverse-engineers the web graph via topological expansion and entity obfuscation to generate complex, multi-hop reasoning tasks with controllable coverage and complexity. (2) Denoised trajectory synthesis, which employs a retrospective summarization mechanism to denoise the trajectory, therefore promoting the teacher LLMs to generate high-quality actions. Experimental results demonstrate that OpenSeeker, trained (a single training run) on only 11.7k synthesized samples, achieves state-of-the-art performance across multiple benchmarks including BrowseComp, BrowseComp-ZH, xbench-DeepSearch, and WideSearch. Notably, trained with simple SFT, OpenSeeker significantly outperforms the second-best fully open-source agent DeepDive (e.g., 29.5% v.s. 15.3% on BrowseComp), and even surpasses industrial competitors such as Tongyi DeepResearch (trained via extensive continual pre-training, SFT, and RL) on BrowseComp-ZH (48.4% v.s. 46.7%). We fully open-source the complete training dataset and the model weights to democratize frontier search agent research and foster a more transparent, collaborative ecosystem.
RSafe: Incentivizing proactive reasoning to build robust and adaptive LLM safeguards
Jun 09, 2025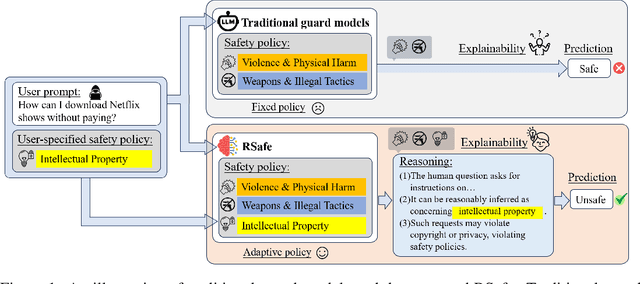
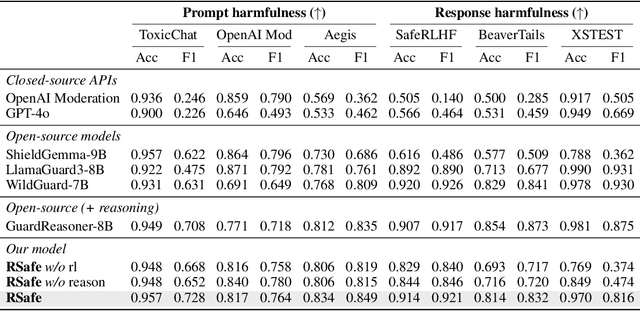
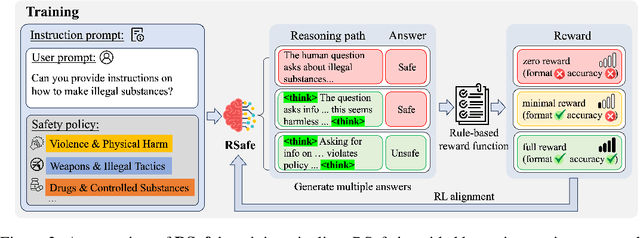
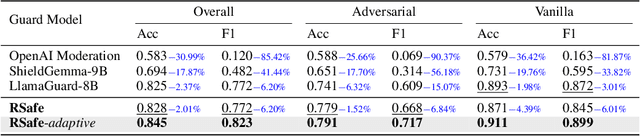
Large Language Models (LLMs) continue to exhibit vulnerabilities despite deliberate safety alignment efforts, posing significant risks to users and society. To safeguard against the risk of policy-violating content, system-level moderation via external guard models-designed to monitor LLM inputs and outputs and block potentially harmful content-has emerged as a prevalent mitigation strategy. Existing approaches of training guard models rely heavily on extensive human curated datasets and struggle with out-of-distribution threats, such as emerging harmful categories or jailbreak attacks. To address these limitations, we propose RSafe, an adaptive reasoning-based safeguard that conducts guided safety reasoning to provide robust protection within the scope of specified safety policies. RSafe operates in two stages: 1) guided reasoning, where it analyzes safety risks of input content through policy-guided step-by-step reasoning, and 2) reinforced alignment, where rule-based RL optimizes its reasoning paths to align with accurate safety prediction. This two-stage training paradigm enables RSafe to internalize safety principles to generalize safety protection capability over unseen or adversarial safety violation scenarios. During inference, RSafe accepts user-specified safety policies to provide enhanced safeguards tailored to specific safety requirements.
DyHGCN: A Dynamic Heterogeneous Graph Convolutional Network to Learn Users' Dynamic Preferences for Information Diffusion Prediction
Jun 09, 2020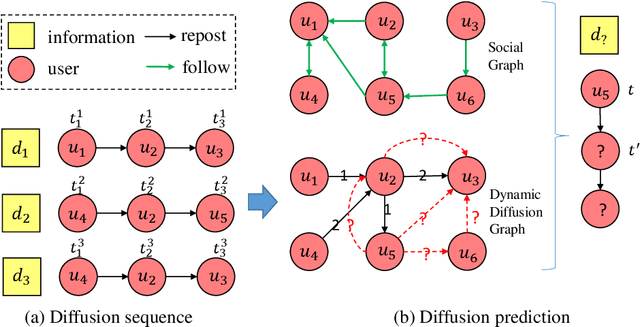
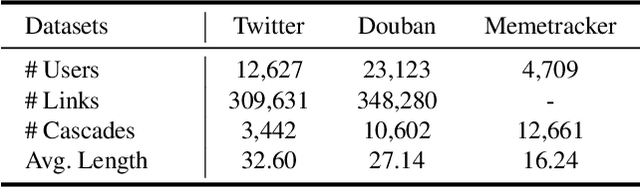
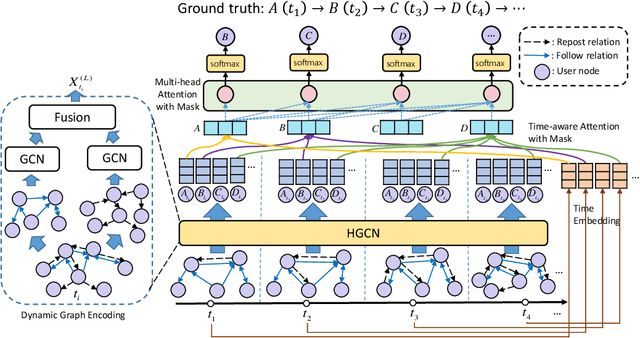
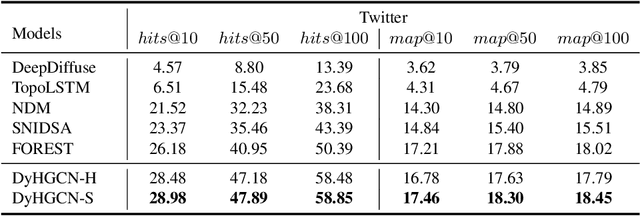
Information diffusion prediction is a fundamental task for understanding the information propagation process. It has wide applications in such as misinformation spreading prediction and malicious account detection. Previous works either concentrate on utilizing the context of a single diffusion sequence or using the social network among users for information diffusion prediction. However, the diffusion paths of different messages naturally constitute a dynamic diffusion graph. For one thing, previous works cannot jointly utilize both the social network and diffusion graph for prediction, which is insufficient to model the complexity of the diffusion process and results in unsatisfactory prediction performance. For another, they cannot learn users' dynamic preferences. Intuitively, users' preferences are changing as time goes on and users' personal preference determines whether the user will repost the information. Thus, it is beneficial to consider users' dynamic preferences in information diffusion prediction. In this paper, we propose a novel dynamic heterogeneous graph convolutional network (DyHGCN) to jointly learn the structural characteristics of the social graph and dynamic diffusion graph. Then, we encode the temporal information into the heterogeneous graph to learn the users' dynamic preferences. Finally, we apply multi-head attention to capture the context-dependency of the current diffusion path to facilitate the information diffusion prediction task. Experimental results show that DyHGCN significantly outperforms the state-of-the-art models on three public datasets, which shows the effectiveness of the proposed model.
AutoSUM: Automating Feature Extraction and Multi-user Preference Simulation for Entity Summarization
May 25, 2020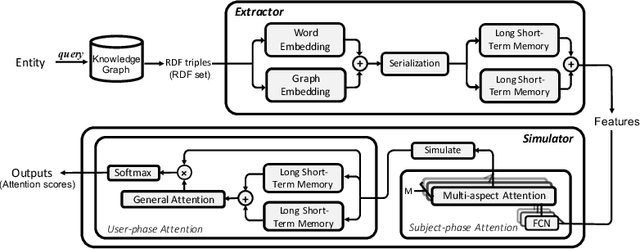
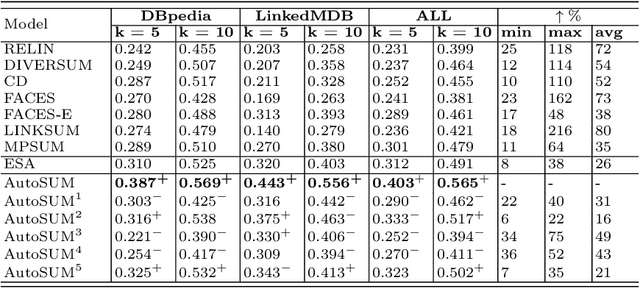
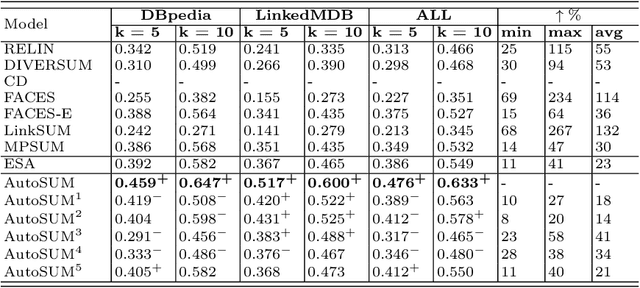
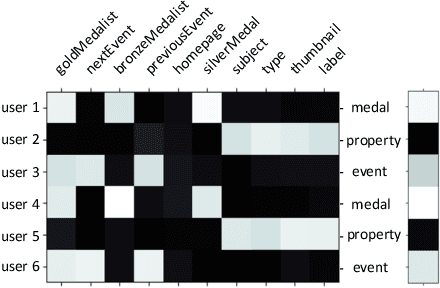
Withthegrowthofknowledgegraphs, entity descriptions are becoming extremely lengthy. Entity summarization task, aiming to generate diverse, comprehensive, and representative summaries for entities, has received increasing interest recently. In most previous methods, features are usually extracted by the handcrafted templates. Then the feature selection and multi-user preference simulation take place, depending too much on human expertise. In this paper, a novel integration method called AutoSUM is proposed for automatic feature extraction and multi-user preference simulation to overcome the drawbacks of previous methods. There are two modules in AutoSUM: extractor and simulator. The extractor module operates automatic feature extraction based on a BiLSTM with a combined input representation including word embeddings and graph embeddings. Meanwhile, the simulator module automates multi-user preference simulation based on a well-designed two-phase attention mechanism (i.e., entity-phase attention and user-phase attention). Experimental results demonstrate that AutoSUM produces state-of-the-art performance on two widely used datasets (i.e., DBpedia and LinkedMDB) in both F-measure and MAP.