 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVitaBench 2.0: Evaluating Personalized and Proactive Agents in Long-Term User Interactions
May 26, 2026Large language models (LLMs) have evolved into interactive agents that collaborate with users in real-world tasks. Effective collaboration in such settings increasingly depends on understanding the user beyond what is explicitly stated, as user intent is often reflected in fragmented daily interactions and requires both personalized modeling and proactive interaction. However, existing agent benchmarks primarily evaluate reasoning and tool use, largely overlooking the challenges of inferring and leveraging user preferences in realistic scenarios. To address this gap, we introduce VitaBench 2.0, a benchmark for evaluating personalized and proactive agent behavior in long-term user interactions. In VitaBench 2.0, tasks are organized as temporally ordered sequences for individual users, where preferences are embedded in fragmented and heterogeneous interactions. Successful completion of tasks requires the agent to continuously extract, utilize, and update user preferences from these interactions. We further evaluate proactiveness through tasks that require agents to recognize missing information and actively acquire it from users or environments before making decisions. To support systematic analysis, we provide an extensible memory interface that enables controlled comparison across different memory architectures. We benchmark a diverse set of frontier proprietary and open-source LLMs. Results show that real-world personalization remains highly challenging even for state-of-the-art models, revealing a substantial gap between current capabilities and practical requirements. Extensive analysis further reveals the failure modes and capability bottlenecks of current agents in real-world personalized decision-making, providing insights for future model improvements.
Do LLMs and VLMs Share Neurons for Inference? Evidence and Mechanisms of Cross-Modal Transfer
Feb 22, 2026Large vision-language models (LVLMs) have rapidly advanced across various domains, yet they still lag behind strong text-only large language models (LLMs) on tasks that require multi-step inference and compositional decision-making. Motivated by their shared transformer architectures, we investigate whether the two model families rely on common internal computation for such inference. At the neuron level, we uncover a surprisingly large overlap: more than half of the top-activated units during multi-step inference are shared between representative LLMs and LVLMs, revealing a modality-invariant inference subspace. Through causal probing via activation amplification, we further show that these shared neurons encode consistent and interpretable concept-level effects, demonstrating their functional contribution to inference. Building on this insight, we propose Shared Neuron Low-Rank Fusion (SNRF), a parameter-efficient framework that transfers mature inference circuitry from LLMs to LVLMs. SNRF profiles cross-model activations to identify shared neurons, computes a low-rank approximation of inter-model weight differences, and injects these updates selectively within the shared-neuron subspace. This mechanism strengthens multimodal inference performance with minimal parameter changes and requires no large-scale multimodal fine-tuning. Across diverse mathematics and perception benchmarks, SNRF consistently enhances LVLM inference performance while preserving perceptual capabilities. Our results demonstrate that shared neurons form an interpretable bridge between LLMs and LVLMs, enabling low-cost transfer of inference ability into multimodal models. Our code is available at [https://github.com/chenhangcuisg-code/Do-LLMs-VLMs-Share-Neurons](https://github.com/chenhangcuisg-code/Do-LLMs-VLMs-Share-Neurons).
Transport and Merge: Cross-Architecture Merging for Large Language Models
Feb 05, 2026Large language models (LLMs) achieve strong capabilities by scaling model capacity and training data, yet many real-world deployments rely on smaller models trained or adapted from low-resource data. This gap motivates the need for mechanisms to transfer knowledge from large, high-resource models to smaller, low-resource targets. While model merging provides an effective transfer mechanism, most existing approaches assume architecture-compatible models and therefore cannot directly transfer knowledge from large high-resource LLMs to heterogeneous low-resource targets. In this work, we propose a cross-architecture merging framework based on optimal transport (OT) that aligns activations to infer cross-neuron correspondences between heterogeneous models. The resulting transport plans are then used to guide direct weight-space fusion, enabling effective high-resource to low-resource transfer using only a small set of inputs. Extensive experiments across low-resource languages and specialized domains demonstrate consistent improvements over target models.
Risky-Bench: Probing Agentic Safety Risks under Real-World Deployment
Feb 03, 2026Large Language Models (LLMs) are increasingly deployed as agents that operate in real-world environments, introducing safety risks beyond linguistic harm. Existing agent safety evaluations rely on risk-oriented tasks tailored to specific agent settings, resulting in limited coverage of safety risk space and failing to assess agent safety behavior during long-horizon, interactive task execution in complex real-world deployments. Moreover, their specialization to particular agent settings limits adaptability across diverse agent configurations. To address these limitations, we propose Risky-Bench, a framework that enables systematic agent safety evaluation grounded in real-world deployment. Risky-Bench organizes evaluation around domain-agnostic safety principles to derive context-aware safety rubrics that delineate safety space, and systematically evaluates safety risks across this space through realistic task execution under varying threat assumptions. When applied to life-assist agent settings, Risky-Bench uncovers substantial safety risks in state-of-the-art agents under realistic execution conditions. Moreover, as a well-structured evaluation pipeline, Risky-Bench is not confined to life-assist scenarios and can be adapted to other deployment settings to construct environment-specific safety evaluations, providing an extensible methodology for agent safety assessment.
Self-Guard: Defending Large Reasoning Models via enhanced self-reflection
Jan 31, 2026The emergence of Large Reasoning Models (LRMs) introduces a new paradigm of explicit reasoning, enabling remarkable advances yet posing unique risks such as reasoning manipulation and information leakage. To mitigate these risks, current alignment strategies predominantly rely on heavy post-training paradigms or external interventions. However, these approaches are often computationally intensive and fail to address the inherent awareness-compliance gap, a critical misalignment where models recognize potential risks yet prioritize following user instructions due to their sycophantic tendencies. To address these limitations, we propose Self-Guard, a lightweight safety defense framework that reinforces safety compliance at the representational level. Self-Guard operates through two principal stages: (1) safety-oriented prompting, which activates the model's latent safety awareness to evoke spontaneous reflection, and (2) safety activation steering, which extracts the resulting directional shift in the hidden state space and amplifies it to ensure that safety compliance prevails over sycophancy during inference. Experiments demonstrate that Self-Guard effectively bridges the awareness-compliance gap, achieving robust safety performance without compromising model utility. Furthermore, Self-Guard exhibits strong generalization across diverse unseen risks and varying model scales, offering a cost-efficient solution for LRM safety alignment.
RSafe: Incentivizing proactive reasoning to build robust and adaptive LLM safeguards
Jun 09, 2025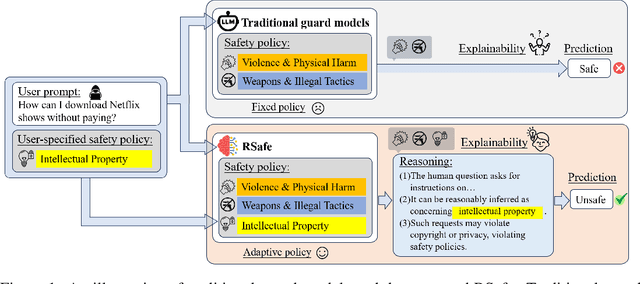
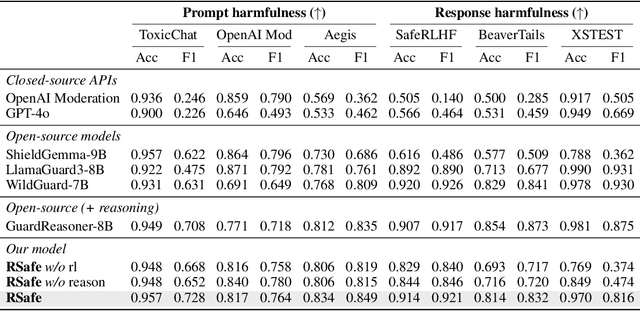
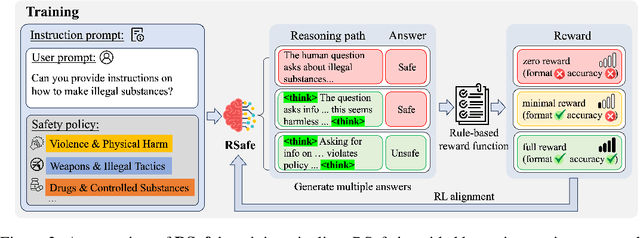
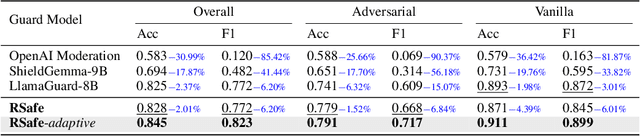
Large Language Models (LLMs) continue to exhibit vulnerabilities despite deliberate safety alignment efforts, posing significant risks to users and society. To safeguard against the risk of policy-violating content, system-level moderation via external guard models-designed to monitor LLM inputs and outputs and block potentially harmful content-has emerged as a prevalent mitigation strategy. Existing approaches of training guard models rely heavily on extensive human curated datasets and struggle with out-of-distribution threats, such as emerging harmful categories or jailbreak attacks. To address these limitations, we propose RSafe, an adaptive reasoning-based safeguard that conducts guided safety reasoning to provide robust protection within the scope of specified safety policies. RSafe operates in two stages: 1) guided reasoning, where it analyzes safety risks of input content through policy-guided step-by-step reasoning, and 2) reinforced alignment, where rule-based RL optimizes its reasoning paths to align with accurate safety prediction. This two-stage training paradigm enables RSafe to internalize safety principles to generalize safety protection capability over unseen or adversarial safety violation scenarios. During inference, RSafe accepts user-specified safety policies to provide enhanced safeguards tailored to specific safety requirements.
Safe + Safe = Unsafe? Exploring How Safe Images Can Be Exploited to Jailbreak Large Vision-Language Models
Nov 19, 2024



Recent advances in Large Vision-Language Models (LVLMs) have showcased strong reasoning abilities across multiple modalities, achieving significant breakthroughs in various real-world applications. Despite this great success, the safety guardrail of LVLMs may not cover the unforeseen domains introduced by the visual modality. Existing studies primarily focus on eliciting LVLMs to generate harmful responses via carefully crafted image-based jailbreaks designed to bypass alignment defenses. In this study, we reveal that a safe image can be exploited to achieve the same jailbreak consequence when combined with additional safe images and prompts. This stems from two fundamental properties of LVLMs: universal reasoning capabilities and safety snowball effect. Building on these insights, we propose Safety Snowball Agent (SSA), a novel agent-based framework leveraging agents' autonomous and tool-using abilities to jailbreak LVLMs. SSA operates through two principal stages: (1) initial response generation, where tools generate or retrieve jailbreak images based on potential harmful intents, and (2) harmful snowballing, where refined subsequent prompts induce progressively harmful outputs. Our experiments demonstrate that \ours can use nearly any image to induce LVLMs to produce unsafe content, achieving high success jailbreaking rates against the latest LVLMs. Unlike prior works that exploit alignment flaws, \ours leverages the inherent properties of LVLMs, presenting a profound challenge for enforcing safety in generative multimodal systems. Our code is avaliable at \url{https://github.com/gzcch/Safety_Snowball_Agent}.
MASKDROID: Robust Android Malware Detection with Masked Graph Representations
Sep 29, 2024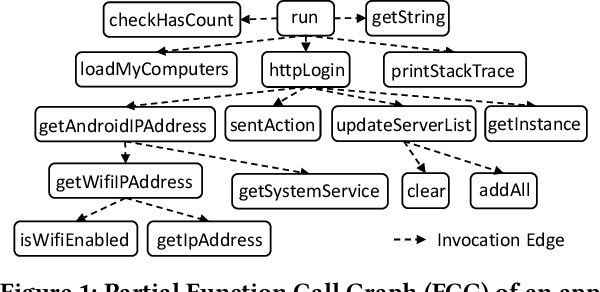
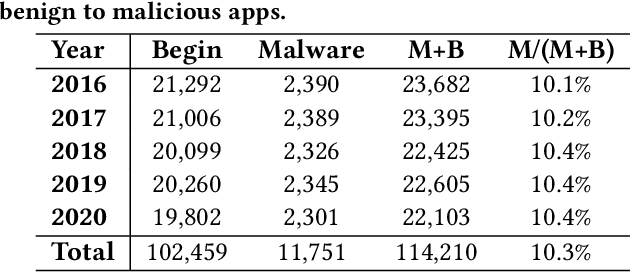
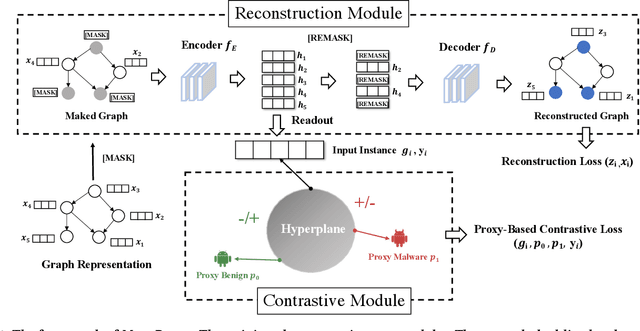
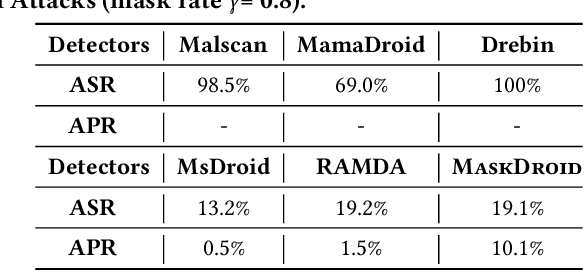
Android malware attacks have posed a severe threat to mobile users, necessitating a significant demand for the automated detection system. Among the various tools employed in malware detection, graph representations (e.g., function call graphs) have played a pivotal role in characterizing the behaviors of Android apps. However, though achieving impressive performance in malware detection, current state-of-the-art graph-based malware detectors are vulnerable to adversarial examples. These adversarial examples are meticulously crafted by introducing specific perturbations to normal malicious inputs. To defend against adversarial attacks, existing defensive mechanisms are typically supplementary additions to detectors and exhibit significant limitations, often relying on prior knowledge of adversarial examples and failing to defend against unseen types of attacks effectively. In this paper, we propose MASKDROID, a powerful detector with a strong discriminative ability to identify malware and remarkable robustness against adversarial attacks. Specifically, we introduce a masking mechanism into the Graph Neural Network (GNN) based framework, forcing MASKDROID to recover the whole input graph using a small portion (e.g., 20%) of randomly selected nodes.This strategy enables the model to understand the malicious semantics and learn more stable representations, enhancing its robustness against adversarial attacks. While capturing stable malicious semantics in the form of dependencies inside the graph structures, we further employ a contrastive module to encourage MASKDROID to learn more compact representations for both the benign and malicious classes to boost its discriminative power in detecting malware from benign apps and adversarial examples.
ALI-Agent: Assessing LLMs' Alignment with Human Values via Agent-based Evaluation
May 23, 2024



Large Language Models (LLMs) can elicit unintended and even harmful content when misaligned with human values, posing severe risks to users and society. To mitigate these risks, current evaluation benchmarks predominantly employ expert-designed contextual scenarios to assess how well LLMs align with human values. However, the labor-intensive nature of these benchmarks limits their test scope, hindering their ability to generalize to the extensive variety of open-world use cases and identify rare but crucial long-tail risks. Additionally, these static tests fail to adapt to the rapid evolution of LLMs, making it hard to evaluate timely alignment issues. To address these challenges, we propose ALI-Agent, an evaluation framework that leverages the autonomous abilities of LLM-powered agents to conduct in-depth and adaptive alignment assessments. ALI-Agent operates through two principal stages: Emulation and Refinement. During the Emulation stage, ALI-Agent automates the generation of realistic test scenarios. In the Refinement stage, it iteratively refines the scenarios to probe long-tail risks. Specifically, ALI-Agent incorporates a memory module to guide test scenario generation, a tool-using module to reduce human labor in tasks such as evaluating feedback from target LLMs, and an action module to refine tests. Extensive experiments across three aspects of human values--stereotypes, morality, and legality--demonstrate that ALI-Agent, as a general evaluation framework, effectively identifies model misalignment. Systematic analysis also validates that the generated test scenarios represent meaningful use cases, as well as integrate enhanced measures to probe long-tail risks. Our code is available at https://github.com/SophieZheng998/ALI-Agent.git
Robust Collaborative Filtering to Popularity Distribution Shift
Oct 16, 2023



In leading collaborative filtering (CF) models, representations of users and items are prone to learn popularity bias in the training data as shortcuts. The popularity shortcut tricks are good for in-distribution (ID) performance but poorly generalized to out-of-distribution (OOD) data, i.e., when popularity distribution of test data shifts w.r.t. the training one. To close the gap, debiasing strategies try to assess the shortcut degrees and mitigate them from the representations. However, there exist two deficiencies: (1) when measuring the shortcut degrees, most strategies only use statistical metrics on a single aspect (i.e., item frequency on item and user frequency on user aspect), failing to accommodate the compositional degree of a user-item pair; (2) when mitigating shortcuts, many strategies assume that the test distribution is known in advance. This results in low-quality debiased representations. Worse still, these strategies achieve OOD generalizability with a sacrifice on ID performance. In this work, we present a simple yet effective debiasing strategy, PopGo, which quantifies and reduces the interaction-wise popularity shortcut without any assumptions on the test data. It first learns a shortcut model, which yields a shortcut degree of a user-item pair based on their popularity representations. Then, it trains the CF model by adjusting the predictions with the interaction-wise shortcut degrees. By taking both causal- and information-theoretical looks at PopGo, we can justify why it encourages the CF model to capture the critical popularity-agnostic features while leaving the spurious popularity-relevant patterns out. We use PopGo to debias two high-performing CF models (MF, LightGCN) on four benchmark datasets. On both ID and OOD test sets, PopGo achieves significant gains over the state-of-the-art debiasing strategies (e.g., DICE, MACR).