 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Aligned Bidword Generation Model for E-commerce Search Advertising
Jun 04, 2025

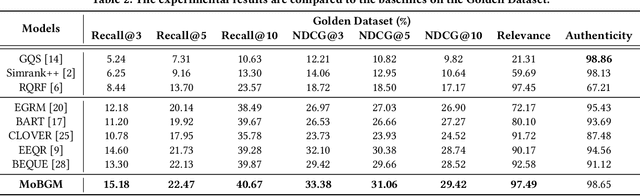

Retrieval systems primarily address the challenge of matching user queries with the most relevant advertisements, playing a crucial role in e-commerce search advertising. The diversity of user needs and expressions often produces massive long-tail queries that cannot be matched with merchant bidwords or product titles, which results in some advertisements not being recalled, ultimately harming user experience and search efficiency. Existing query rewriting research focuses on various methods such as query log mining, query-bidword vector matching, or generation-based rewriting. However, these methods often fail to simultaneously optimize the relevance and authenticity of the user's original query and rewrite and maximize the revenue potential of recalled ads. In this paper, we propose a Multi-objective aligned Bidword Generation Model (MoBGM), which is composed of a discriminator, generator, and preference alignment module, to address these challenges. To simultaneously improve the relevance and authenticity of the query and rewrite and maximize the platform revenue, we design a discriminator to optimize these key objectives. Using the feedback signal of the discriminator, we train a multi-objective aligned bidword generator that aims to maximize the combined effect of the three objectives. Extensive offline and online experiments show that our proposed algorithm significantly outperforms the state of the art. After deployment, the algorithm has created huge commercial value for the platform, further verifying its feasibility and robustness.
Generative Retrieval and Alignment Model: A New Paradigm for E-commerce Retrieval
Apr 02, 2025Traditional sparse and dense retrieval methods struggle to leverage general world knowledge and often fail to capture the nuanced features of queries and products. With the advent of large language models (LLMs), industrial search systems have started to employ LLMs to generate identifiers for product retrieval. Commonly used identifiers include (1) static/semantic IDs and (2) product term sets. The first approach requires creating a product ID system from scratch, missing out on the world knowledge embedded within LLMs. While the second approach leverages this general knowledge, the significant difference in word distribution between queries and products means that product-based identifiers often do not align well with user search queries, leading to missed product recalls. Furthermore, when queries contain numerous attributes, these algorithms generate a large number of identifiers, making it difficult to assess their quality, which results in low overall recall efficiency. To address these challenges, this paper introduces a novel e-commerce retrieval paradigm: the Generative Retrieval and Alignment Model (GRAM). GRAM employs joint training on text information from both queries and products to generate shared text identifier codes, effectively bridging the gap between queries and products. This approach not only enhances the connection between queries and products but also improves inference efficiency. The model uses a co-alignment strategy to generate codes optimized for maximizing retrieval efficiency. Additionally, it introduces a query-product scoring mechanism to compare product values across different codes, further boosting retrieval efficiency. Extensive offline and online A/B testing demonstrates that GRAM significantly outperforms traditional models and the latest generative retrieval models, confirming its effectiveness and practicality.
HGAMN: Heterogeneous Graph Attention Matching Network for Multilingual POI Retrieval at Baidu Maps
Sep 05, 2024



The increasing interest in international travel has raised the demand of retrieving point of interests in multiple languages. This is even superior to find local venues such as restaurants and scenic spots in unfamiliar languages when traveling abroad. Multilingual POI retrieval, enabling users to find desired POIs in a demanded language using queries in numerous languages, has become an indispensable feature of today's global map applications such as Baidu Maps. This task is non-trivial because of two key challenges: (1) visiting sparsity and (2) multilingual query-POI matching. To this end, we propose a Heterogeneous Graph Attention Matching Network (HGAMN) to concurrently address both challenges. Specifically, we construct a heterogeneous graph that contains two types of nodes: POI node and query node using the search logs of Baidu Maps. To alleviate challenge \#1, we construct edges between different POI nodes to link the low-frequency POIs with the high-frequency ones, which enables the transfer of knowledge from the latter to the former. To mitigate challenge \#2, we construct edges between POI and query nodes based on the co-occurrences between queries and POIs, where queries in different languages and formulations can be aggregated for individual POIs. Moreover, we develop an attention-based network to jointly learn node representations of the heterogeneous graph and further design a cross-attention module to fuse the representations of both types of nodes for query-POI relevance scoring. Extensive experiments conducted on large-scale real-world datasets from Baidu Maps demonstrate the superiority and effectiveness of HGAMN. In addition, HGAMN has already been deployed in production at Baidu Maps, and it successfully keeps serving hundreds of millions of requests every day.
A Semi-supervised Multi-channel Graph Convolutional Network for Query Classification in E-commerce
Aug 04, 2024
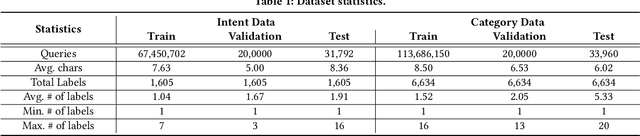


Query intent classification is an essential module for customers to find desired products on the e-commerce application quickly. Most existing query intent classification methods rely on the users' click behavior as a supervised signal to construct training samples. However, these methods based entirely on posterior labels may lead to serious category imbalance problems because of the Matthew effect in click samples. Compared with popular categories, it is difficult for products under long-tail categories to obtain traffic and user clicks, which makes the models unable to detect users' intent for products under long-tail categories. This in turn aggravates the problem that long-tail categories cannot obtain traffic, forming a vicious circle. In addition, due to the randomness of the user's click, the posterior label is unstable for the query with similar semantics, which makes the model very sensitive to the input, leading to an unstable and incomplete recall of categories. In this paper, we propose a novel Semi-supervised Multi-channel Graph Convolutional Network (SMGCN) to address the above problems from the perspective of label association and semi-supervised learning. SMGCN extends category information and enhances the posterior label by utilizing the similarity score between the query and categories. Furthermore, it leverages the co-occurrence and semantic similarity graph of categories to strengthen the relations among labels and weaken the influence of posterior label instability. We conduct extensive offline and online A/B experiments, and the experimental results show that SMGCN significantly outperforms the strong baselines, which shows its effectiveness and practicality.
A Multi-Granularity Matching Attention Network for Query Intent Classification in E-commerce Retrieval
Mar 28, 2023



Query intent classification, which aims at assisting customers to find desired products, has become an essential component of the e-commerce search. Existing query intent classification models either design more exquisite models to enhance the representation learning of queries or explore label-graph and multi-task to facilitate models to learn external information. However, these models cannot capture multi-granularity matching features from queries and categories, which makes them hard to mitigate the gap in the expression between informal queries and categories. This paper proposes a Multi-granularity Matching Attention Network (MMAN), which contains three modules: a self-matching module, a char-level matching module, and a semantic-level matching module to comprehensively extract features from the query and a query-category interaction matrix. In this way, the model can eliminate the difference in expression between queries and categories for query intent classification. We conduct extensive offline and online A/B experiments, and the results show that the MMAN significantly outperforms the strong baselines, which shows the superiority and effectiveness of MMAN. MMAN has been deployed in production and brings great commercial value for our company.
GEDIT: Geographic-Enhanced and Dependency-Guided Tagging for Joint POI and Accessibility Extraction at Baidu Maps
Aug 20, 2021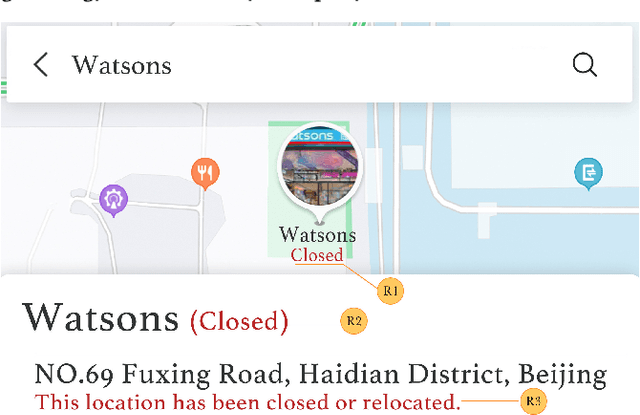

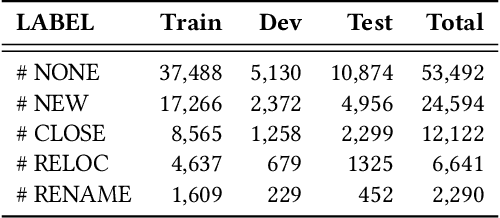

Providing timely accessibility reminders of a point-of-interest (POI) plays a vital role in improving user satisfaction of finding places and making visiting decisions. However, it is difficult to keep the POI database in sync with the real-world counterparts due to the dynamic nature of business changes. To alleviate this problem, we formulate and present a practical solution that jointly extracts POI mentions and identifies their coupled accessibility labels from unstructured text. We approach this task as a sequence tagging problem, where the goal is to produce <POI name, accessibility label> pairs from unstructured text. This task is challenging because of two main issues: (1) POI names are often newly-coined words so as to successfully register new entities or brands and (2) there may exist multiple pairs in the text, which necessitates dealing with one-to-many or many-to-one mapping to make each POI coupled with its accessibility label. To this end, we propose a Geographic-Enhanced and Dependency-guIded sequence Tagging (GEDIT) model to concurrently address the two challenges. First, to alleviate challenge #1, we develop a geographic-enhanced pre-trained model to learn the text representations. Second, to mitigate challenge #2, we apply a relational graph convolutional network to learn the tree node representations from the parsed dependency tree. Finally, we construct a neural sequence tagging model by integrating and feeding the previously pre-learned representations into a CRF layer. Extensive experiments conducted on a real-world dataset demonstrate the superiority and effectiveness of GEDIT. In addition, it has already been deployed in production at Baidu Maps. Statistics show that the proposed solution can save significant human effort and labor costs to deal with the same amount of documents, which confirms that it is a practical way for POI accessibility maintenance.
SRLF: A Stance-aware Reinforcement Learning Framework for Content-based Rumor Detection on Social Media
May 10, 2021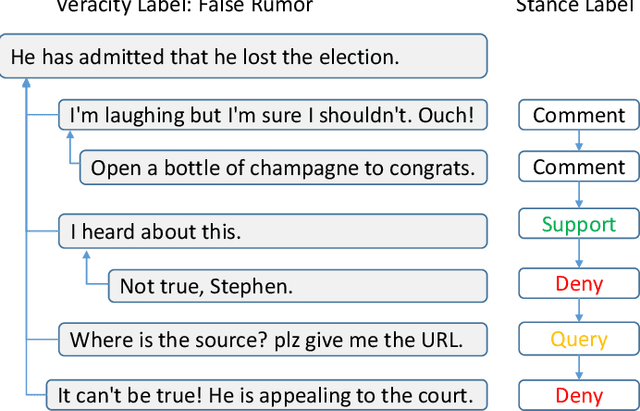
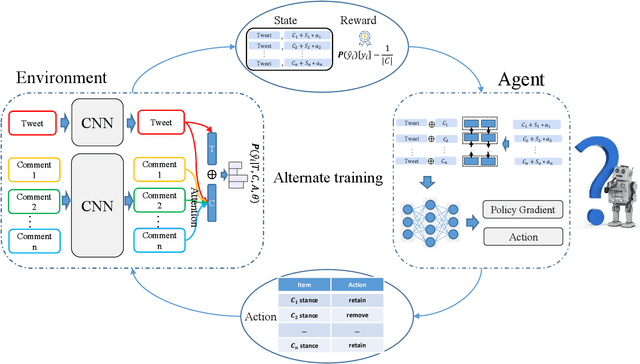
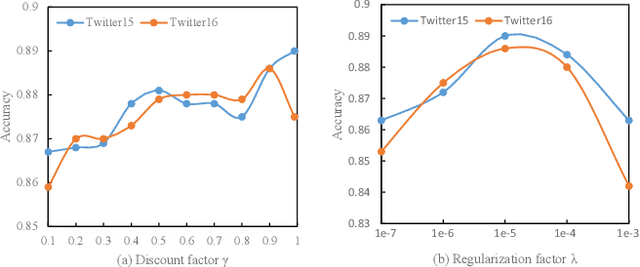
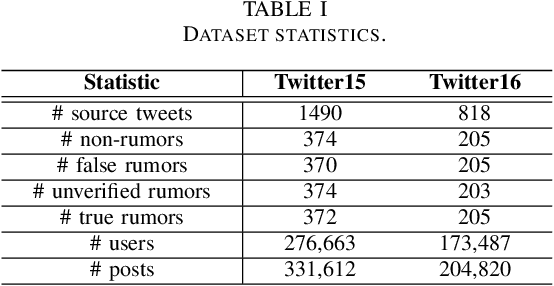
The rapid development of social media changes the lifestyle of people and simultaneously provides an ideal place for publishing and disseminating rumors, which severely exacerbates social panic and triggers a crisis of social trust. Early content-based methods focused on finding clues from the text and user profiles for rumor detection. Recent studies combine the stances of users' comments with news content to capture the difference between true and false rumors. Although the user's stance is effective for rumor detection, the manual labeling process is time-consuming and labor-intensive, which limits the application of utilizing it to facilitate rumor detection. In this paper, we first finetune a pre-trained BERT model on a small labeled dataset and leverage this model to annotate weak stance labels for users' comment data to overcome the problem mentioned above. Then, we propose a novel Stance-aware Reinforcement Learning Framework (SRLF) to select high-quality labeled stance data for model training and rumor detection. Both the stance selection and rumor detection tasks are optimized simultaneously to promote both tasks mutually. We conduct experiments on two commonly used real-world datasets. The experimental results demonstrate that our framework outperforms the state-of-the-art models significantly, which confirms the effectiveness of the proposed framework.
Early Detection of Fake News by Utilizing the Credibility of News, Publishers, and Users Based on Weakly Supervised Learning
Dec 14, 2020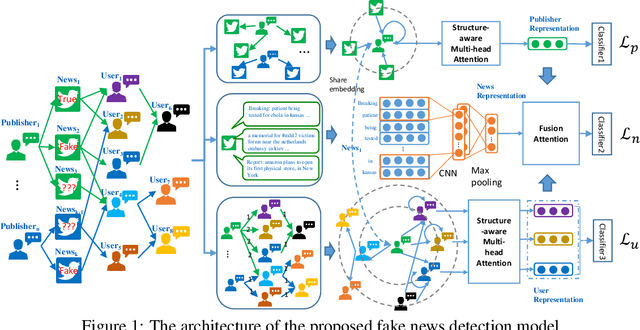
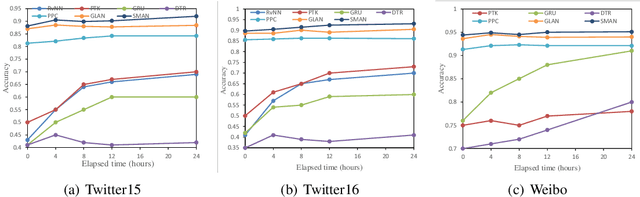
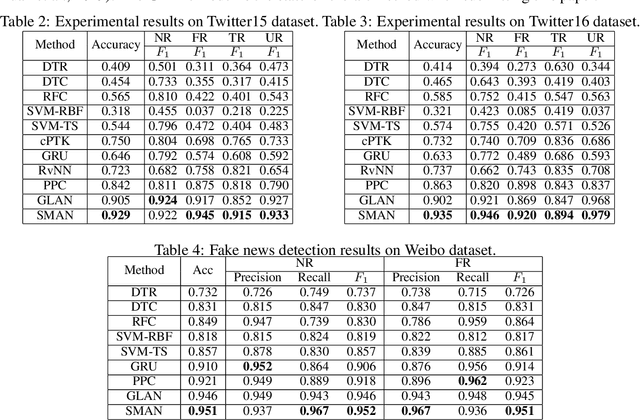
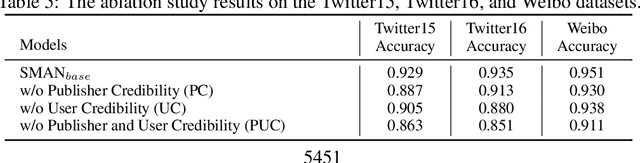
The dissemination of fake news significantly affects personal reputation and public trust. Recently, fake news detection has attracted tremendous attention, and previous studies mainly focused on finding clues from news content or diffusion path. However, the required features of previous models are often unavailable or insufficient in early detection scenarios, resulting in poor performance. Thus, early fake news detection remains a tough challenge. Intuitively, the news from trusted and authoritative sources or shared by many users with a good reputation is more reliable than other news. Using the credibility of publishers and users as prior weakly supervised information, we can quickly locate fake news in massive news and detect them in the early stages of dissemination. In this paper, we propose a novel Structure-aware Multi-head Attention Network (SMAN), which combines the news content, publishing, and reposting relations of publishers and users, to jointly optimize the fake news detection and credibility prediction tasks. In this way, we can explicitly exploit the credibility of publishers and users for early fake news detection. We conducted experiments on three real-world datasets, and the results show that SMAN can detect fake news in 4 hours with an accuracy of over 91%, which is much faster than the state-of-the-art models.
DyHGCN: A Dynamic Heterogeneous Graph Convolutional Network to Learn Users' Dynamic Preferences for Information Diffusion Prediction
Jun 09, 2020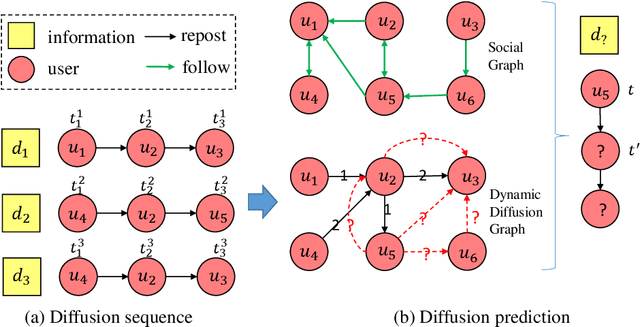
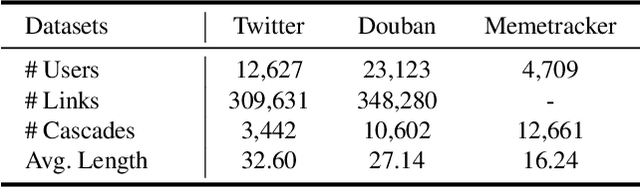
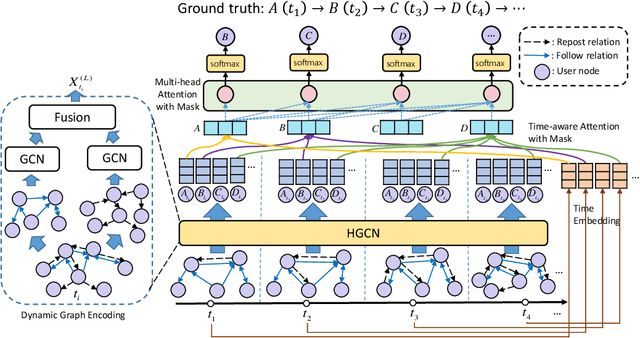
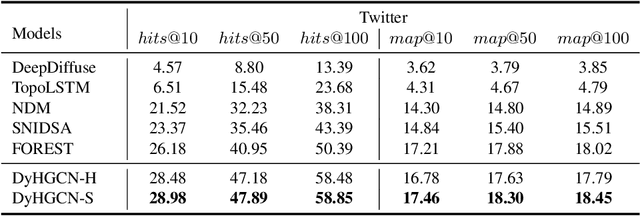
Information diffusion prediction is a fundamental task for understanding the information propagation process. It has wide applications in such as misinformation spreading prediction and malicious account detection. Previous works either concentrate on utilizing the context of a single diffusion sequence or using the social network among users for information diffusion prediction. However, the diffusion paths of different messages naturally constitute a dynamic diffusion graph. For one thing, previous works cannot jointly utilize both the social network and diffusion graph for prediction, which is insufficient to model the complexity of the diffusion process and results in unsatisfactory prediction performance. For another, they cannot learn users' dynamic preferences. Intuitively, users' preferences are changing as time goes on and users' personal preference determines whether the user will repost the information. Thus, it is beneficial to consider users' dynamic preferences in information diffusion prediction. In this paper, we propose a novel dynamic heterogeneous graph convolutional network (DyHGCN) to jointly learn the structural characteristics of the social graph and dynamic diffusion graph. Then, we encode the temporal information into the heterogeneous graph to learn the users' dynamic preferences. Finally, we apply multi-head attention to capture the context-dependency of the current diffusion path to facilitate the information diffusion prediction task. Experimental results show that DyHGCN significantly outperforms the state-of-the-art models on three public datasets, which shows the effectiveness of the proposed model.
Beyond Statistical Relations: Integrating Knowledge Relations into Style Correlations for Multi-Label Music Style Classification
Nov 09, 2019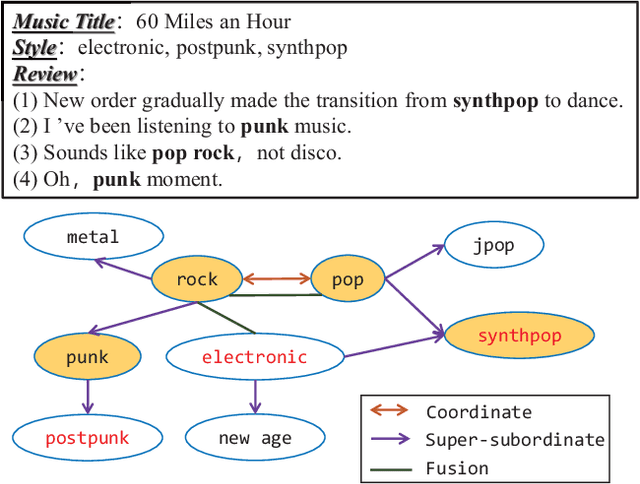
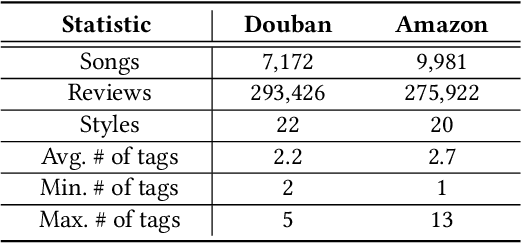
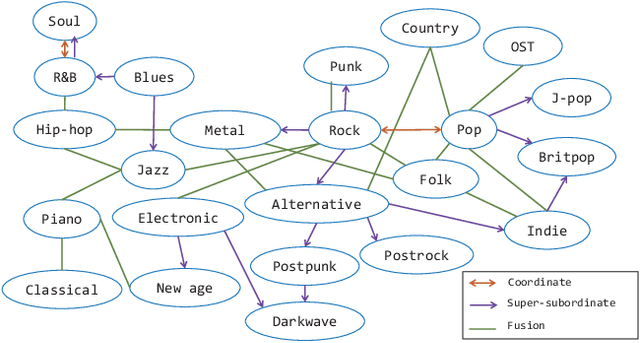
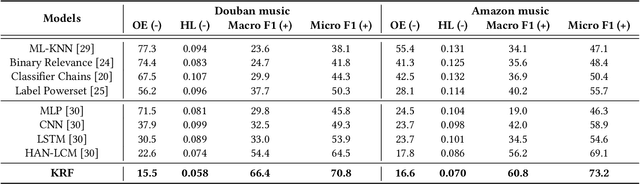
Automatically labeling multiple styles for every song is a comprehensive application in all kinds of music websites. Recently, some researches explore review-driven multi-label music style classification and exploit style correlations for this task. However, their methods focus on mining the statistical relations between different music styles and only consider shallow style relations. Moreover, these statistical relations suffer from the underfitting problem because some music styles have little training data. To tackle these problems, we propose a novel knowledge relations integrated framework (KRF) to capture the complete style correlations, which jointly exploits the inherent relations between music styles according to external knowledge and their statistical relations. Based on the two types of relations, we use graph convolutional network to learn the deep correlations between styles automatically. Experimental results show that our framework significantly outperforms state-of-the-art methods. Further studies demonstrate that our framework can effectively alleviate the underfitting problem and learn meaningful style correlations.