 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAHSD: Bridging the Long-tail Gap via Adaptive Distillation in Black-box Sequential Recommendation
Jun 04, 2026Sequential recommendation systems are widely adopted but often deployed as black-box APIs, which has driven recent interest in model extraction to replicate their capabilities locally. However, the long-tail distribution induces severe signal heterogeneity: dense head sequences trigger the solidification of teacher preference, biasing extraction toward local patterns, while sparse tail sequences yield flat, noisy predictions. Existing one-size-fits-all extraction overlooks this disparity, resulting in noise overfitting and suboptimal knowledge transfer. We propose BAHSD, a black-box adaptive distillation framework that handles signal heterogeneity via a multi-scale consistency probing mechanism to implicitly quantify signal reliability. Based on this, an adaptive hierarchical objective is designed: dynamic-temperature KL divergence mitigates preference solidification for high-confidence signals, while ranking consistency and InfoNCE contrastive learning provide noise-robust enhancement for low-confidence signals. BAHSD consistently outperforms baselines, achieving up to 4.98\% gain over the teacher and 80\%+ improvement on tail users, offering a plug-and-play solution for high-fidelity black-box recommendation extraction.
Towards Efficient and Evidence-grounded Mobility Prediction with LLM-Driven Agent
Jun 03, 2026Individual-level mobility prediction is central to urban simulation, transportation planning, and policy analysis. Supervised sequence models achieve strong accuracy but require task-specific training and offer limited decision-level transparency. Recent LLM-based methods improve interpretability, yet mostly rely on static prompts and single-pass inference, limiting their ability to seek additional evidence when mobility signals are weak or conflicting. We propose \method{}, a training-free LLM-driven agent framework that formulates next-location prediction as adaptive evidence-controlled decision making. \method{} resolves routine cases through a fast path based on historical regularity, while ambiguous cases trigger iterative tool use over recent trajectories, historical behavior, stay-move likelihood, and geographical evidence. Across three mobility datasets, AgentMob achieves the strongest overall performance among training-free LLM-based methods, with GPT-5.4 reaching 71.42\% Acc@1 on BW, 33.14\% on YJMob100K, and 33.50\% on Shanghai ISP. On BW non-fast-path cases, the LLM controller improves Acc@1 from 30.65\% to 48.62\% over a same-tool statistical baseline, showing that its main benefit lies in resolving ambiguous predictions through adaptive evidence gathering. Our code is available at https://github.com/Unknown-zoo/AgentMob.
RecBundle: A Next-Generation Geometric Paradigm for Explainable Recommender Systems
Mar 17, 2026Recommender systems are inherently dynamic feedback loops where prolonged local interactions accumulate into macroscopic structural degradation such as information cocoons. Existing representation learning paradigms are universally constrained by the assumption of a single flat space, forcing topologically grounded user associations and semantically driven historical interactions to be fitted within the same vector space. This excessive coupling of heterogeneous information renders it impossible for researchers to mechanistically distinguish and identify the sources of systemic bias. To overcome this theoretical bottleneck, we introduce Fiber Bundle from modern differential geometry and propose a novel geometric analysis paradigm for recommender systems. This theory naturally decouples the system space into two hierarchical layers: the base manifold formed by user interaction networks, and the fibers attached to individual user nodes that carry their dynamic preferences. Building upon this, we construct RecBundle, a framework oriented toward next-generation recommender systems that formalizes user collaboration as geometric connection and parallel transport on the base manifold, while mapping content evolution to holonomy transformations on fibers. From this foundation, we identify future application directions encompassing quantitative mechanisms for information cocoons and evolutionary bias, geometric meta-theory for adaptive recommendation, and novel inference architectures integrating large language models (LLMs). Empirical analysis on real-world MovieLens and Amazon Beauty datasets validates the effectiveness of this geometric framework.
Towards Efficient and Generalizable Retrieval: Adaptive Semantic Quantization and Residual Knowledge Transfer
Feb 27, 2026While semantic ID-based generative retrieval enables efficient end-to-end modeling in industrial applications, these methods face a persistent trade-off: head items are susceptible to ID collisions that negatively impact downstream tasks, whereas data-sparse tail items, including cold-start items, exhibit limited generalization. To address this issue, we propose the Anchored Curriculum with Sequential Adaptive Quantization (SA^2CRQ) framework. The framework introduces Sequential Adaptive Residual Quantization (SARQ) to dynamically allocate code lengths based on item path entropy, assigning longer, discriminative IDs to head items and shorter, generalizable IDs to tail items. To mitigate data sparsity, the Anchored Curriculum Residual Quantization (ACRQ) component utilizes a frozen semantic manifold learned from head items to regularize and accelerate the representation learning of tail items. Experimental results from a large-scale industrial search system and multiple public datasets indicate that SA^2CRQ yields consistent improvements over existing baselines, particularly in cold-start retrieval scenarios.
RAD-DPO: Robust Adaptive Denoising Direct Preference Optimization for Generative Retrieval in E-commerce
Feb 27, 2026Generative Retrieval (GR) has emerged as a powerful paradigm in e-commerce search, retrieving items via autoregressive decoding of Semantic IDs (SIDs). However, aligning GR with complex user preferences remains challenging. While Direct Preference Optimization (DPO) offers an efficient alignment solution, its direct application to structured SIDs suffers from three limitations: (i) it penalizes shared hierarchical prefixes, causing gradient conflicts; (ii) it is vulnerable to noisy pseudo-negatives from implicit feedback; and (iii) in multi-label queries with multiple relevant items, it exacerbates a probability "squeezing effect" among valid candidates. To address these issues, we propose RAD-DPO, which introduces token-level gradient detachment to protect prefix structures, similarity-based dynamic reward weighting to mitigate label noise, and a multi-label global contrastive objective integrated with global SFT loss to explicitly expand positive coverage. Extensive offline experiments and online A/B testing on a large-scale e-commerce platform demonstrate significant improvements in ranking quality and training efficiency.
A Cognitive Distribution and Behavior-Consistent Framework for Black-Box Attacks on Recommender Systems
Feb 12, 2026With the growing deployment of sequential recommender systems in e-commerce and other fields, their black-box interfaces raise security concerns: models are vulnerable to extraction and subsequent adversarial manipulation. Existing black-box extraction attacks primarily rely on hard labels or pairwise learning, often ignoring the importance of ranking positions, which results in incomplete knowledge transfer. Moreover, adversarial sequences generated via pure gradient methods lack semantic consistency with real user behavior, making them easily detectable. To overcome these limitations, this paper proposes a dual-enhanced attack framework. First, drawing on primacy effects and position bias, we introduce a cognitive distribution-driven extraction mechanism that maps discrete rankings into continuous value distributions with position-aware decay, thereby advancing from order alignment to cognitive distribution alignment. Second, we design a behavior-aware noisy item generation strategy that jointly optimizes collaborative signals and gradient signals. This ensures both semantic coherence and statistical stealth while effectively promoting target item rankings. Extensive experiments on multiple datasets demonstrate that our approach significantly outperforms existing methods in both attack success rate and evasion rate, validating the value of integrating cognitive modeling and behavioral consistency for secure recommender systems.
Boundary-Aware Multi-Behavior Dynamic Graph Transformer for Sequential Recommendation
Feb 11, 2026In the landscape of contemporary recommender systems, user-item interactions are inherently dynamic and sequential, often characterized by various behaviors. Prior research has explored the modeling of user preferences through sequential interactions and the user-item interaction graph, utilizing advanced techniques such as graph neural networks and transformer-based architectures. However, these methods typically fall short in simultaneously accounting for the dynamic nature of graph topologies and the sequential pattern of interactions in user preference models. Moreover, they often fail to adequately capture the multiple user behavior boundaries during model optimization. To tackle these challenges, we introduce a boundary-aware Multi-Behavioral Dynamic Graph Transformer (MB-DGT) model that dynamically refines the graph structure to reflect the evolving patterns of user behaviors and interactions. Our model involves a transformer-based dynamic graph aggregator for user preference modeling, which assimilates the changing graph structure and the sequence of user behaviors. This integration yields a more comprehensive and dynamic representation of user preferences. For model optimization, we implement a user-specific multi-behavior loss function that delineates the interest boundaries among different behaviors, thereby enriching the personalized learning of user preferences. Comprehensive experiments across three datasets indicate that our model consistently delivers remarkable recommendation performance.
A Simple and Effective Framework for Symmetric Consistent Indexing in Large-Scale Dense Retrieval
Dec 15, 2025Dense retrieval has become the industry standard in large-scale information retrieval systems due to its high efficiency and competitive accuracy. Its core relies on a coarse-to-fine hierarchical architecture that enables rapid candidate selection and precise semantic matching, achieving millisecond-level response over billion-scale corpora. This capability makes it essential not only in traditional search and recommendation scenarios but also in the emerging paradigm of generative recommendation driven by large language models, where semantic IDs-themselves a form of coarse-to-fine representation-play a foundational role. However, the widely adopted dual-tower encoding architecture introduces inherent challenges, primarily representational space misalignment and retrieval index inconsistency, which degrade matching accuracy, retrieval stability, and performance on long-tail queries. These issues are further magnified in semantic ID generation, ultimately limiting the performance ceiling of downstream generative models. To address these challenges, this paper proposes a simple and effective framework named SCI comprising two synergistic modules: a symmetric representation alignment module that employs an innovative input-swapping mechanism to unify the dual-tower representation space without adding parameters, and an consistent indexing with dual-tower synergy module that redesigns retrieval paths using a dual-view indexing strategy to maintain consistency from training to inference. The framework is systematic, lightweight, and engineering-friendly, requiring minimal overhead while fully supporting billion-scale deployment. We provide theoretical guarantees for our approach, with its effectiveness validated by results across public datasets and real-world e-commerce datasets.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
pEBR: A Probabilistic Approach to Embedding Based Retrieval
Oct 25, 2024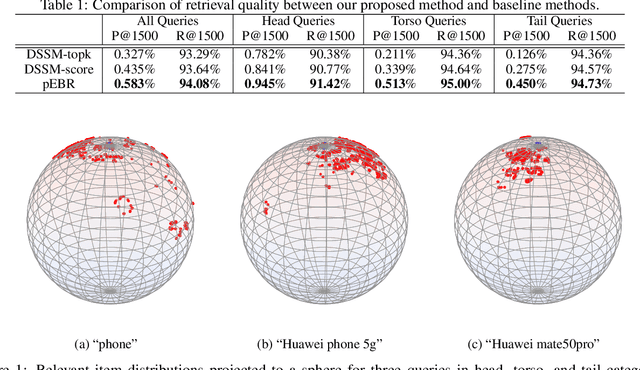
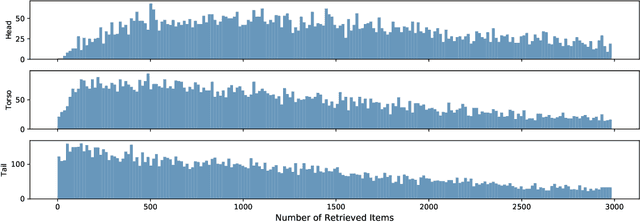

Embedding retrieval aims to learn a shared semantic representation space for both queries and items, thus enabling efficient and effective item retrieval using approximate nearest neighbor (ANN) algorithms. In current industrial practice, retrieval systems typically retrieve a fixed number of items for different queries, which actually leads to insufficient retrieval (low recall) for head queries and irrelevant retrieval (low precision) for tail queries. Mostly due to the trend of frequentist approach to loss function designs, till now there is no satisfactory solution to holistically address this challenge in the industry. In this paper, we move away from the frequentist approach, and take a novel \textbf{p}robabilistic approach to \textbf{e}mbedding \textbf{b}ased \textbf{r}etrieval (namely \textbf{pEBR}) by learning the item distribution for different queries, which enables a dynamic cosine similarity threshold calculated by the probabilistic cumulative distribution function (CDF) value. The experimental results show that our approach improves both the retrieval precision and recall significantly. Ablation studies also illustrate how the probabilistic approach is able to capture the differences between head and tail queries.