 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeMi: When Imbalanced Semi-Supervised Learning Meets Mining Hard Examples
Jan 10, 2025



Semi-Supervised Learning (SSL) can leverage abundant unlabeled data to boost model performance. However, the class-imbalanced data distribution in real-world scenarios poses great challenges to SSL, resulting in performance degradation. Existing class-imbalanced semi-supervised learning (CISSL) methods mainly focus on rebalancing datasets but ignore the potential of using hard examples to enhance performance, making it difficult to fully harness the power of unlabeled data even with sophisticated algorithms. To address this issue, we propose a method that enhances the performance of Imbalanced Semi-Supervised Learning by Mining Hard Examples (SeMi). This method distinguishes the entropy differences among logits of hard and easy examples, thereby identifying hard examples and increasing the utility of unlabeled data, better addressing the imbalance problem in CISSL. In addition, we maintain a class-balanced memory bank with confidence decay for storing high-confidence embeddings to enhance the pseudo-labels' reliability. Although our method is simple, it is effective and seamlessly integrates with existing approaches. We perform comprehensive experiments on standard CISSL benchmarks and experimentally demonstrate that our proposed SeMi outperforms existing state-of-the-art methods on multiple benchmarks, especially in reversed scenarios, where our best result shows approximately a 54.8\% improvement over the baseline methods.
Breaking the Hourglass Phenomenon of Residual Quantization: Enhancing the Upper Bound of Generative Retrieval
Jul 31, 2024



Generative retrieval (GR) has emerged as a transformative paradigm in search and recommender systems, leveraging numeric-based identifier representations to enhance efficiency and generalization. Notably, methods like TIGER employing Residual Quantization-based Semantic Identifiers (RQ-SID), have shown significant promise in e-commerce scenarios by effectively managing item IDs. However, a critical issue termed the "\textbf{Hourglass}" phenomenon, occurs in RQ-SID, where intermediate codebook tokens become overly concentrated, hindering the full utilization of generative retrieval methods. This paper analyses and addresses this problem by identifying data sparsity and long-tailed distribution as the primary causes. Through comprehensive experiments and detailed ablation studies, we analyze the impact of these factors on codebook utilization and data distribution. Our findings reveal that the "Hourglass" phenomenon substantially impacts the performance of RQ-SID in generative retrieval. We propose effective solutions to mitigate this issue, thereby significantly enhancing the effectiveness of generative retrieval in real-world E-commerce applications.
Pretraining Chinese BERT for Detecting Word Insertion and Deletion Errors
Apr 26, 2022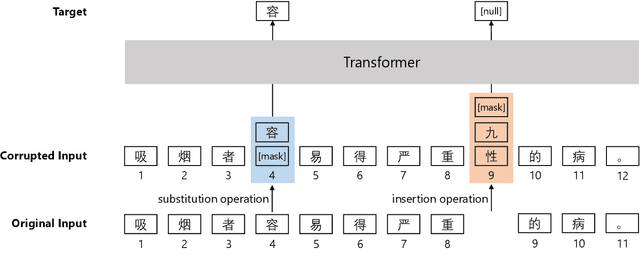

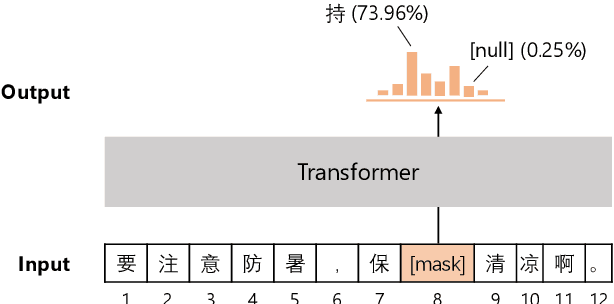

Chinese BERT models achieve remarkable progress in dealing with grammatical errors of word substitution. However, they fail to handle word insertion and deletion because BERT assumes the existence of a word at each position. To address this, we present a simple and effective Chinese pretrained model. The basic idea is to enable the model to determine whether a word exists at a particular position. We achieve this by introducing a special token \texttt{[null]}, the prediction of which stands for the non-existence of a word. In the training stage, we design pretraining tasks such that the model learns to predict \texttt{[null]} and real words jointly given the surrounding context. In the inference stage, the model readily detects whether a word should be inserted or deleted with the standard masked language modeling function. We further create an evaluation dataset to foster research on word insertion and deletion. It includes human-annotated corrections for 7,726 erroneous sentences. Results show that existing Chinese BERT performs poorly on detecting insertion and deletion errors. Our approach significantly improves the F1 scores from 24.1\% to 78.1\% for word insertion and from 26.5\% to 68.5\% for word deletion, respectively.