 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Analysis of Performance Drop in DeepSeek Model Quantization
May 05, 2025Recently, there is a high demand for deploying DeepSeek-R1 and V3 locally, possibly because the official service often suffers from being busy and some organizations have data privacy concerns. While single-machine deployment offers infrastructure simplicity, the models' 671B FP8 parameter configuration exceeds the practical memory limits of a standard 8-GPU machine. Quantization is a widely used technique that helps reduce model memory consumption. However, it is unclear what the performance of DeepSeek-R1 and V3 will be after being quantized. This technical report presents the first quantitative evaluation of multi-bitwidth quantization across the complete DeepSeek model spectrum. Key findings reveal that 4-bit quantization maintains little performance degradation versus FP8 while enabling single-machine deployment on standard NVIDIA GPU devices. We further propose DQ3_K_M, a dynamic 3-bit quantization method that significantly outperforms traditional Q3_K_M variant on various benchmarks, which is also comparable with 4-bit quantization (Q4_K_M) approach in most tasks. Moreover, DQ3_K_M supports single-machine deployment configurations for both NVIDIA H100/A100 and Huawei 910B. Our implementation of DQ3\_K\_M is released at https://github.com/UnicomAI/DeepSeek-Eval, containing optimized 3-bit quantized variants of both DeepSeek-R1 and DeepSeek-V3.
Inferflow: an Efficient and Highly Configurable Inference Engine for Large Language Models
Jan 16, 2024We present Inferflow, an efficient and highly configurable inference engine for large language models (LLMs). With Inferflow, users can serve most of the common transformer models by simply modifying some lines in corresponding configuration files, without writing a single line of source code. Compared with most existing inference engines, Inferflow has some key features. First, by implementing a modular framework of atomic build-blocks and technologies, Inferflow is compositionally generalizable to new models. Second, 3.5-bit quantization is introduced in Inferflow as a tradeoff between 3-bit and 4-bit quantization. Third, hybrid model partitioning for multi-GPU inference is introduced in Inferflow to better balance inference speed and throughput than the existing partition-by-layer and partition-by-tensor strategies.
RobustGEC: Robust Grammatical Error Correction Against Subtle Context Perturbation
Oct 11, 2023



Grammatical Error Correction (GEC) systems play a vital role in assisting people with their daily writing tasks. However, users may sometimes come across a GEC system that initially performs well but fails to correct errors when the inputs are slightly modified. To ensure an ideal user experience, a reliable GEC system should have the ability to provide consistent and accurate suggestions when encountering irrelevant context perturbations, which we refer to as context robustness. In this paper, we introduce RobustGEC, a benchmark designed to evaluate the context robustness of GEC systems. RobustGEC comprises 5,000 GEC cases, each with one original error-correct sentence pair and five variants carefully devised by human annotators. Utilizing RobustGEC, we reveal that state-of-the-art GEC systems still lack sufficient robustness against context perturbations. In addition, we propose a simple yet effective method for remitting this issue.
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Sep 03, 2023



While large language models (LLMs) have demonstrated remarkable capabilities across a range of downstream tasks, a significant concern revolves around their propensity to exhibit hallucinations: LLMs occasionally generate content that diverges from the user input, contradicts previously generated context, or misaligns with established world knowledge. This phenomenon poses a substantial challenge to the reliability of LLMs in real-world scenarios. In this paper, we survey recent efforts on the detection, explanation, and mitigation of hallucination, with an emphasis on the unique challenges posed by LLMs. We present taxonomies of the LLM hallucination phenomena and evaluation benchmarks, analyze existing approaches aiming at mitigating LLM hallucination, and discuss potential directions for future research.
Effidit: Your AI Writing Assistant
Aug 04, 2022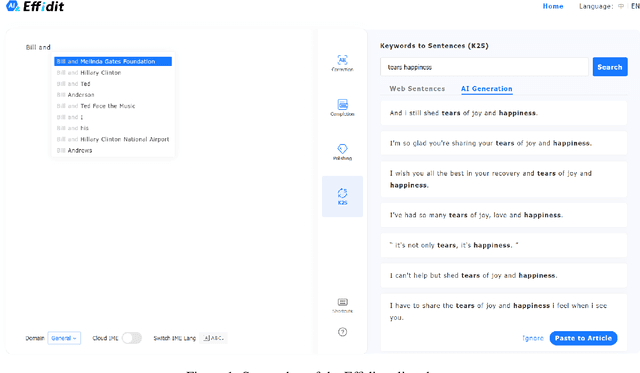
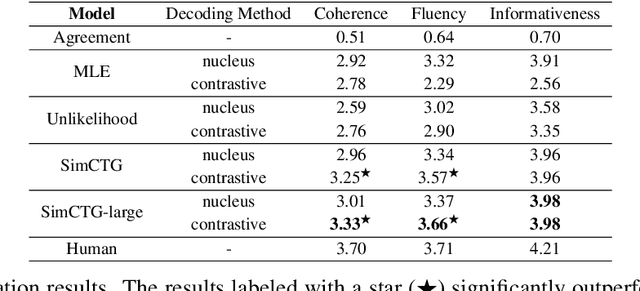
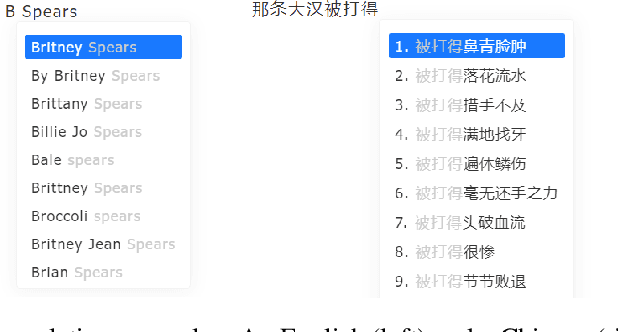

In this technical report, we introduce Effidit (Efficient and Intelligent Editing), a digital writing assistant that facilitates users to write higher-quality text more efficiently by using artificial intelligence (AI) technologies. Previous writing assistants typically provide the function of error checking (to detect and correct spelling and grammatical errors) and limited text-rewriting functionality. With the emergence of large-scale neural language models, some systems support automatically completing a sentence or a paragraph. In Effidit, we significantly expand the capacities of a writing assistant by providing functions in five categories: text completion, error checking, text polishing, keywords to sentences (K2S), and cloud input methods (cloud IME). In the text completion category, Effidit supports generation-based sentence completion, retrieval-based sentence completion, and phrase completion. In contrast, many other writing assistants so far only provide one or two of the three functions. For text polishing, we have three functions: (context-aware) phrase polishing, sentence paraphrasing, and sentence expansion, whereas many other writing assistants often support one or two functions in this category. The main contents of this report include major modules of Effidit, methods for implementing these modules, and evaluation results of some key methods.
Pretraining Chinese BERT for Detecting Word Insertion and Deletion Errors
Apr 26, 2022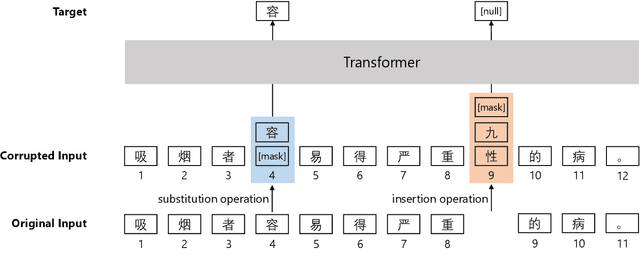

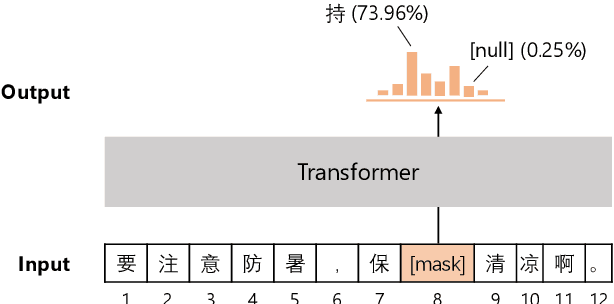

Chinese BERT models achieve remarkable progress in dealing with grammatical errors of word substitution. However, they fail to handle word insertion and deletion because BERT assumes the existence of a word at each position. To address this, we present a simple and effective Chinese pretrained model. The basic idea is to enable the model to determine whether a word exists at a particular position. We achieve this by introducing a special token \texttt{[null]}, the prediction of which stands for the non-existence of a word. In the training stage, we design pretraining tasks such that the model learns to predict \texttt{[null]} and real words jointly given the surrounding context. In the inference stage, the model readily detects whether a word should be inserted or deleted with the standard masked language modeling function. We further create an evaluation dataset to foster research on word insertion and deletion. It includes human-annotated corrections for 7,726 erroneous sentences. Results show that existing Chinese BERT performs poorly on detecting insertion and deletion errors. Our approach significantly improves the F1 scores from 24.1\% to 78.1\% for word insertion and from 26.5\% to 68.5\% for word deletion, respectively.
"Is Whole Word Masking Always Better for Chinese BERT?": Probing on Chinese Grammatical Error Correction
Mar 02, 2022
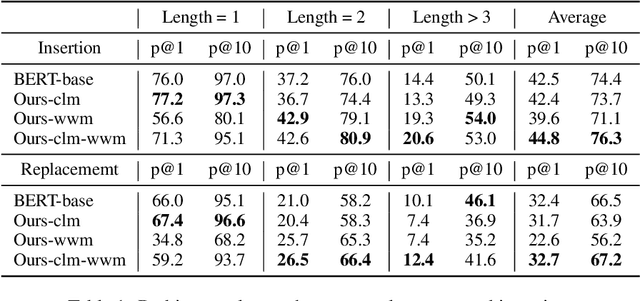

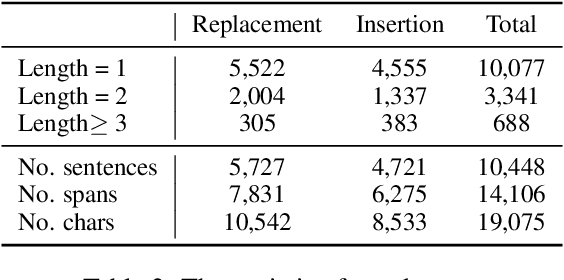
Whole word masking (WWM), which masks all subwords corresponding to a word at once, makes a better English BERT model. For the Chinese language, however, there is no subword because each token is an atomic character. The meaning of a word in Chinese is different in that a word is a compositional unit consisting of multiple characters. Such difference motivates us to investigate whether WWM leads to better context understanding ability for Chinese BERT. To achieve this, we introduce two probing tasks related to grammatical error correction and ask pretrained models to revise or insert tokens in a masked language modeling manner. We construct a dataset including labels for 19,075 tokens in 10,448 sentences. We train three Chinese BERT models with standard character-level masking (CLM), WWM, and a combination of CLM and WWM, respectively. Our major findings are as follows: First, when one character needs to be inserted or replaced, the model trained with CLM performs the best. Second, when more than one character needs to be handled, WWM is the key to better performance. Finally, when being fine-tuned on sentence-level downstream tasks, models trained with different masking strategies perform comparably.
TexSmart: A Text Understanding System for Fine-Grained NER and Enhanced Semantic Analysis
Dec 31, 2020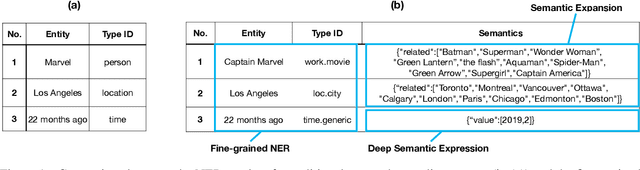


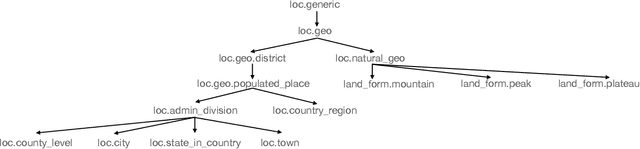
This technique report introduces TexSmart, a text understanding system that supports fine-grained named entity recognition (NER) and enhanced semantic analysis functionalities. Compared to most previous publicly available text understanding systems and tools, TexSmart holds some unique features. First, the NER function of TexSmart supports over 1,000 entity types, while most other public tools typically support several to (at most) dozens of entity types. Second, TexSmart introduces new semantic analysis functions like semantic expansion and deep semantic representation, that are absent in most previous systems. Third, a spectrum of algorithms (from very fast algorithms to those that are relatively slow but more accurate) are implemented for one function in TexSmart, to fulfill the requirements of different academic and industrial applications. The adoption of unsupervised or weakly-supervised algorithms is especially emphasized, with the goal of easily updating our models to include fresh data with less human annotation efforts. The main contents of this report include major functions of TexSmart, algorithms for achieving these functions, how to use the TexSmart toolkit and Web APIs, and evaluation results of some key algorithms.