 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining Chinese BERT for Detecting Word Insertion and Deletion Errors
Paper and Code
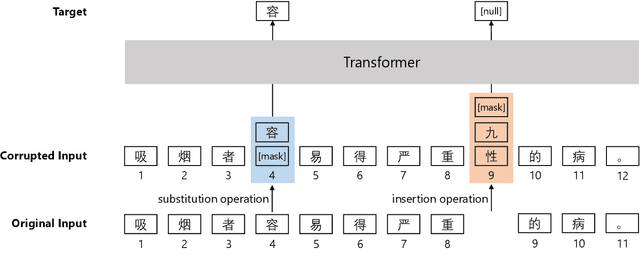

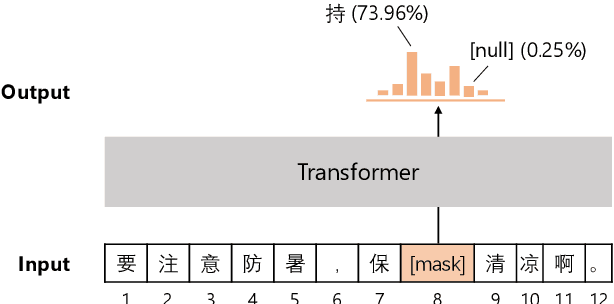

Chinese BERT models achieve remarkable progress in dealing with grammatical errors of word substitution. However, they fail to handle word insertion and deletion because BERT assumes the existence of a word at each position. To address this, we present a simple and effective Chinese pretrained model. The basic idea is to enable the model to determine whether a word exists at a particular position. We achieve this by introducing a special token \texttt{[null]}, the prediction of which stands for the non-existence of a word. In the training stage, we design pretraining tasks such that the model learns to predict \texttt{[null]} and real words jointly given the surrounding context. In the inference stage, the model readily detects whether a word should be inserted or deleted with the standard masked language modeling function. We further create an evaluation dataset to foster research on word insertion and deletion. It includes human-annotated corrections for 7,726 erroneous sentences. Results show that existing Chinese BERT performs poorly on detecting insertion and deletion errors. Our approach significantly improves the F1 scores from 24.1\% to 78.1\% for word insertion and from 26.5\% to 68.5\% for word deletion, respectively.