 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuity of Topic, Interaction, and Query: Learning to Quote in Online Conversations
Jun 18, 2021
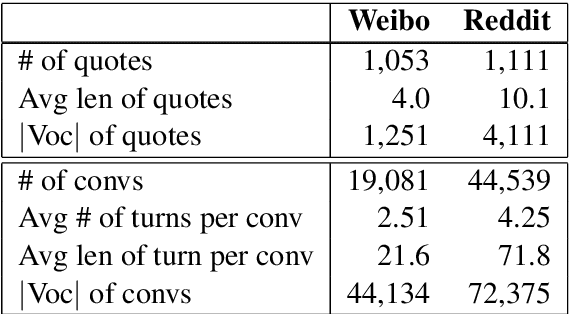
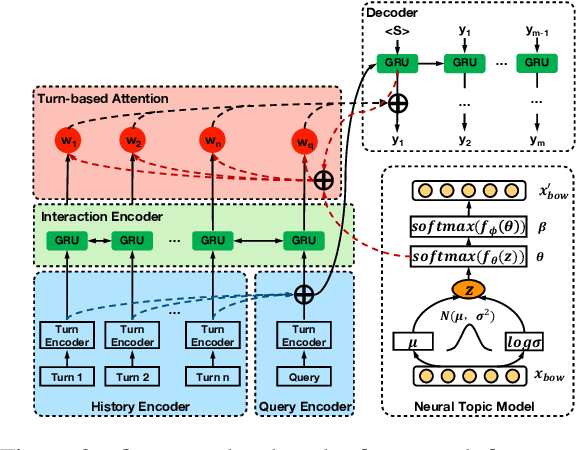
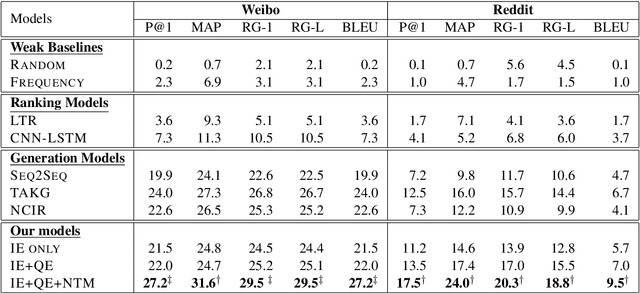
Quotations are crucial for successful explanations and persuasions in interpersonal communications. However, finding what to quote in a conversation is challenging for both humans and machines. This work studies automatic quotation generation in an online conversation and explores how language consistency affects whether a quotation fits the given context. Here, we capture the contextual consistency of a quotation in terms of latent topics, interactions with the dialogue history, and coherence to the query turn's existing content. Further, an encoder-decoder neural framework is employed to continue the context with a quotation via language generation. Experiment results on two large-scale datasets in English and Chinese demonstrate that our quotation generation model outperforms the state-of-the-art models. Further analysis shows that topic, interaction, and query consistency are all helpful to learn how to quote in online conversations.
Domain-Adaptive Pretraining Methods for Dialogue Understanding
May 28, 2021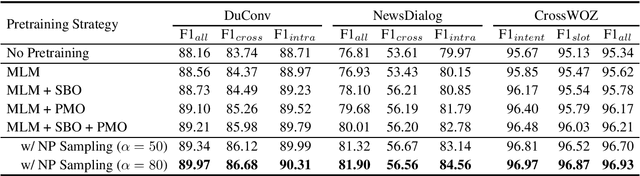
Language models like BERT and SpanBERT pretrained on open-domain data have obtained impressive gains on various NLP tasks. In this paper, we probe the effectiveness of domain-adaptive pretraining objectives on downstream tasks. In particular, three objectives, including a novel objective focusing on modeling predicate-argument relations, are evaluated on two challenging dialogue understanding tasks. Experimental results demonstrate that domain-adaptive pretraining with proper objectives can significantly improve the performance of a strong baseline on these tasks, achieving the new state-of-the-art performances.
Conversational Semantic Role Labeling
Apr 11, 2021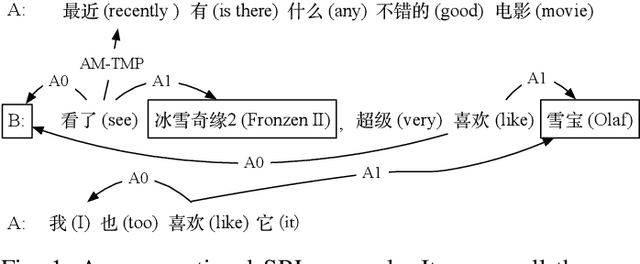
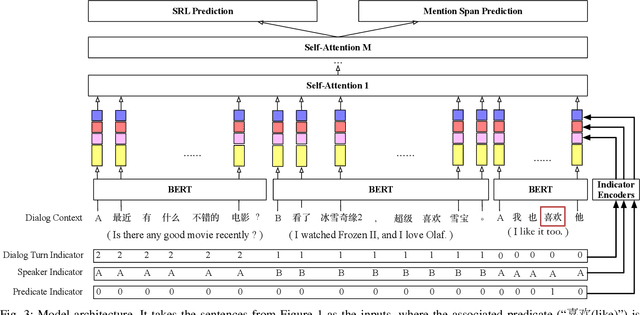


Semantic role labeling (SRL) aims to extract the arguments for each predicate in an input sentence. Traditional SRL can fail to analyze dialogues because it only works on every single sentence, while ellipsis and anaphora frequently occur in dialogues. To address this problem, we propose the conversational SRL task, where an argument can be the dialogue participants, a phrase in the dialogue history or the current sentence. As the existing SRL datasets are in the sentence level, we manually annotate semantic roles for 3,000 chit-chat dialogues (27,198 sentences) to boost the research in this direction. Experiments show that while traditional SRL systems (even with the help of coreference resolution or rewriting) perform poorly for analyzing dialogues, modeling dialogue histories and participants greatly helps the performance, indicating that adapting SRL to conversations is very promising for universal dialogue understanding. Our initial study by applying CSRL to two mainstream conversational tasks, dialogue response generation and dialogue context rewriting, also confirms the usefulness of CSRL.
TexSmart: A Text Understanding System for Fine-Grained NER and Enhanced Semantic Analysis
Dec 31, 2020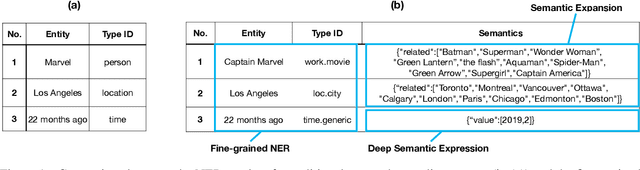


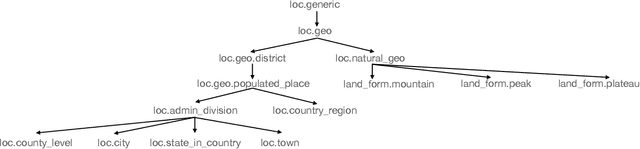
This technique report introduces TexSmart, a text understanding system that supports fine-grained named entity recognition (NER) and enhanced semantic analysis functionalities. Compared to most previous publicly available text understanding systems and tools, TexSmart holds some unique features. First, the NER function of TexSmart supports over 1,000 entity types, while most other public tools typically support several to (at most) dozens of entity types. Second, TexSmart introduces new semantic analysis functions like semantic expansion and deep semantic representation, that are absent in most previous systems. Third, a spectrum of algorithms (from very fast algorithms to those that are relatively slow but more accurate) are implemented for one function in TexSmart, to fulfill the requirements of different academic and industrial applications. The adoption of unsupervised or weakly-supervised algorithms is especially emphasized, with the goal of easily updating our models to include fresh data with less human annotation efforts. The main contents of this report include major functions of TexSmart, algorithms for achieving these functions, how to use the TexSmart toolkit and Web APIs, and evaluation results of some key algorithms.
Semantic Role Labeling Guided Multi-turn Dialogue ReWriter
Oct 03, 2020

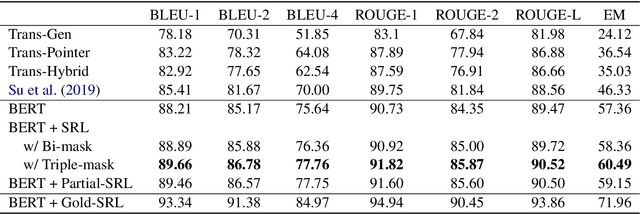
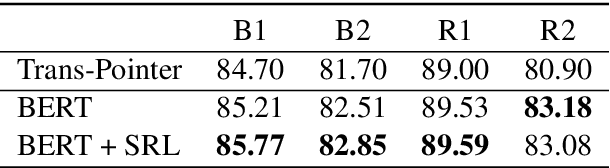
For multi-turn dialogue rewriting, the capacity of effectively modeling the linguistic knowledge in dialog context and getting rid of the noises is essential to improve its performance. Existing attentive models attend to all words without prior focus, which results in inaccurate concentration on some dispensable words. In this paper, we propose to use semantic role labeling (SRL), which highlights the core semantic information of who did what to whom, to provide additional guidance for the rewriter model. Experiments show that this information significantly improves a RoBERTa-based model that already outperforms previous state-of-the-art systems.
Rigid Formats Controlled Text Generation
Apr 17, 2020
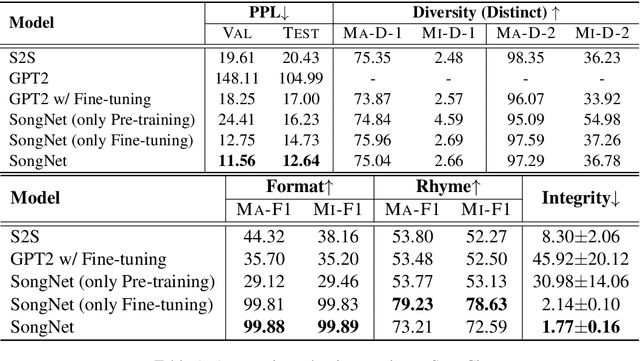
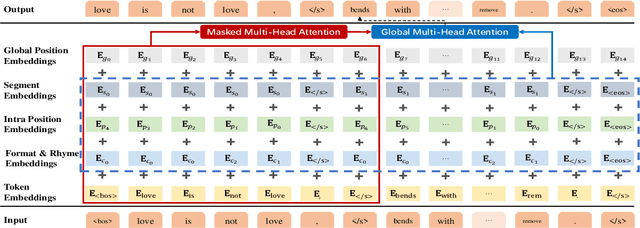
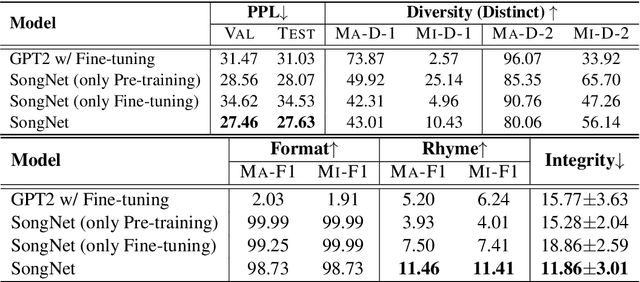
Neural text generation has made tremendous progress in various tasks. One common characteristic of most of the tasks is that the texts are not restricted to some rigid formats when generating. However, we may confront some special text paradigms such as Lyrics (assume the music score is given), Sonnet, SongCi (classical Chinese poetry of the Song dynasty), etc. The typical characteristics of these texts are in three folds: (1) They must comply fully with the rigid predefined formats. (2) They must obey some rhyming schemes. (3) Although they are restricted to some formats, the sentence integrity must be guaranteed. To the best of our knowledge, text generation based on the predefined rigid formats has not been well investigated. Therefore, we propose a simple and elegant framework named SongNet to tackle this problem. The backbone of the framework is a Transformer-based auto-regressive language model. Sets of symbols are tailor-designed to improve the modeling performance especially on format, rhyme, and sentence integrity. We improve the attention mechanism to impel the model to capture some future information on the format. A pre-training and fine-tuning framework is designed to further improve the generation quality. Extensive experiments conducted on two collected corpora demonstrate that our proposed framework generates significantly better results in terms of both automatic metrics and the human evaluation.
CASE: Context-Aware Semantic Expansion
Dec 31, 2019
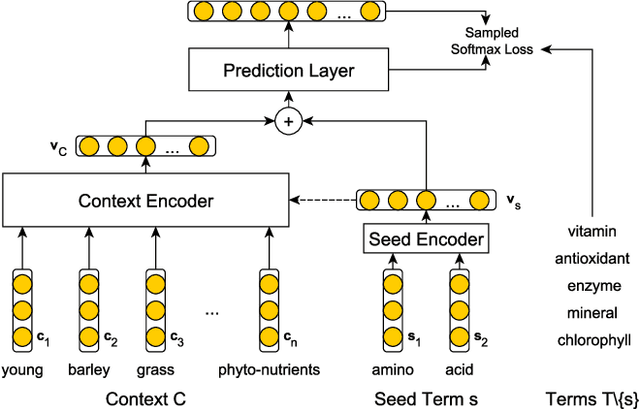
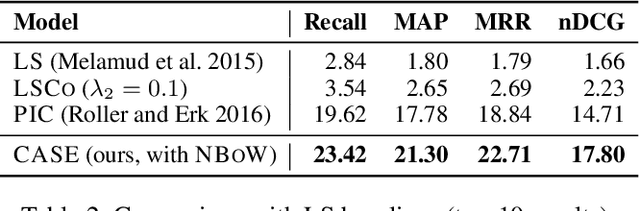
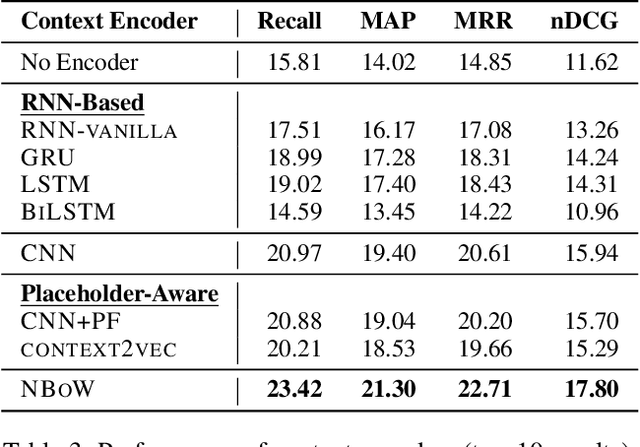
In this paper, we define and study a new task called Context-Aware Semantic Expansion (CASE). Given a seed term in a sentential context, we aim to suggest other terms that well fit the context as the seed. CASE has many interesting applications such as query suggestion, computer-assisted writing, and word sense disambiguation, to name a few. Previous explorations, if any, only involve some similar tasks, and all require human annotations for evaluation. In this study, we demonstrate that annotations for this task can be harvested at scale from existing corpora, in a fully automatic manner. On a dataset of 1.8 million sentences thus derived, we propose a network architecture that encodes the context and seed term separately before suggesting alternative terms. The context encoder in this architecture can be easily extended by incorporating seed-aware attention. Our experiments demonstrate that competitive results are achieved with appropriate choices of context encoder and attention scoring function.
A Manually Annotated Chinese Corpus for Non-task-oriented Dialogue Systems
May 15, 2018
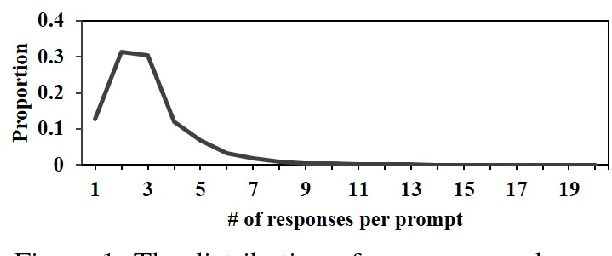
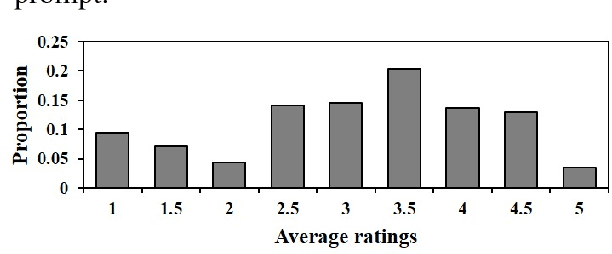
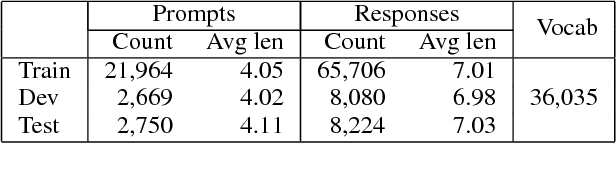
This paper presents a large-scale corpus for non-task-oriented dialogue response selection, which contains over 27K distinct prompts more than 82K responses collected from social media. To annotate this corpus, we define a 5-grade rating scheme: bad, mediocre, acceptable, good, and excellent, according to the relevance, coherence, informativeness, interestingness, and the potential to move a conversation forward. To test the validity and usefulness of the produced corpus, we compare various unsupervised and supervised models for response selection. Experimental results confirm that the proposed corpus is helpful in training response selection models.
hyperdoc2vec: Distributed Representations of Hypertext Documents
May 10, 2018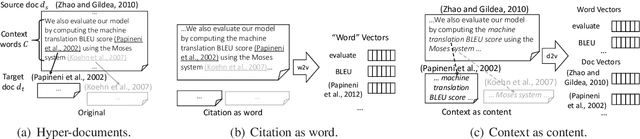

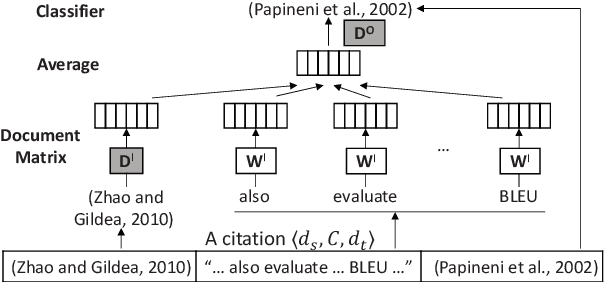
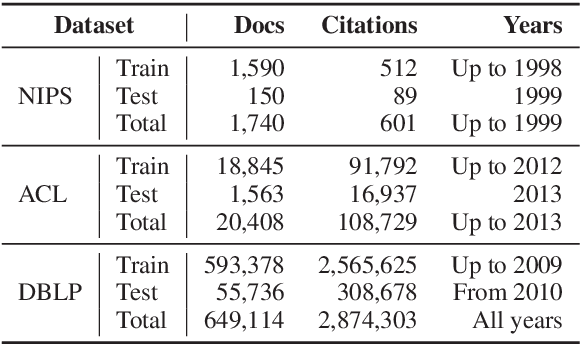
Hypertext documents, such as web pages and academic papers, are of great importance in delivering information in our daily life. Although being effective on plain documents, conventional text embedding methods suffer from information loss if directly adapted to hyper-documents. In this paper, we propose a general embedding approach for hyper-documents, namely, hyperdoc2vec, along with four criteria characterizing necessary information that hyper-document embedding models should preserve. Systematic comparisons are conducted between hyperdoc2vec and several competitors on two tasks, i.e., paper classification and citation recommendation, in the academic paper domain. Analyses and experiments both validate the superiority of hyperdoc2vec to other models w.r.t. the four criteria.