 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSherry: Hardware-Efficient 1.25-Bit Ternary Quantization via Fine-grained Sparsification
Jan 12, 2026The deployment of Large Language Models (LLMs) on resource-constrained edge devices is increasingly hindered by prohibitive memory and computational requirements. While ternary quantization offers a compelling solution by reducing weights to {-1, 0, +1}, current implementations suffer from a fundamental misalignment with commodity hardware. Most existing methods must choose between 2-bit aligned packing, which incurs significant bit wastage, or 1.67-bit irregular packing, which degrades inference speed. To resolve this tension, we propose Sherry, a hardware-efficient ternary quantization framework. Sherry introduces a 3:4 fine-grained sparsity that achieves a regularized 1.25-bit width by packing blocks of four weights into five bits, restoring power-of-two alignment. Furthermore, we identify weight trapping issue in sparse ternary training, which leads to representational collapse. To address this, Sherry introduces Arenas, an annealing residual synapse mechanism that maintains representational diversity during training. Empirical evaluations on LLaMA-3.2 across five benchmarks demonstrate that Sherry matches state-of-the-art ternary performance while significantly reducing model size. Notably, on an Intel i7-14700HX CPU, our 1B model achieves zero accuracy loss compared to SOTA baselines while providing 25% bit savings and 10% speed up. The code is available at https://github.com/Tencent/AngelSlim .
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Parallel Speculative Decoding with Adaptive Draft Length
Aug 13, 2024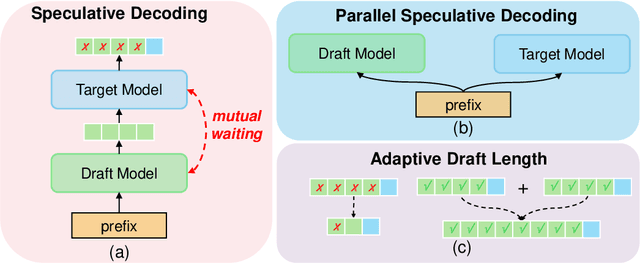

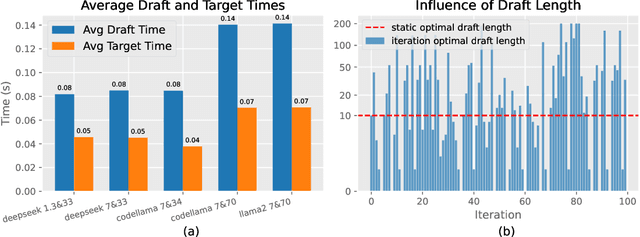

Speculative decoding (SD), where an extra draft model is employed to provide multiple \textit{draft} tokens first and then the original target model verifies these tokens in parallel, has shown great power for LLM inference acceleration. However, existing SD methods suffer from the mutual waiting problem, i.e., the target model gets stuck when the draft model is \textit{guessing} tokens, and vice versa. This problem is directly incurred by the asynchronous execution of the draft model and the target model, and is exacerbated due to the fixed draft length in speculative decoding. To address these challenges, we propose a conceptually simple, flexible, and general framework to boost speculative decoding, namely \textbf{P}arallel sp\textbf{E}culative decoding with \textbf{A}daptive d\textbf{R}aft \textbf{L}ength (PEARL). Specifically, PEARL proposes \textit{pre-verify} to verify the first draft token in advance during the drafting phase, and \textit{post-verify} to generate more draft tokens during the verification phase. PEARL parallels the drafting phase and the verification phase via applying the two strategies, and achieves adaptive draft length for different scenarios, which effectively alleviates the mutual waiting problem. Moreover, we theoretically demonstrate that the mean accepted tokens of PEARL is more than existing \textit{draft-then-verify} works. Experiments on various text generation benchmarks demonstrate the effectiveness of our \name, leading to a superior speedup performance up to \textbf{3.79$\times$} and \textbf{1.52$\times$}, compared to auto-regressive decoding and vanilla speculative decoding, respectively.
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
Active RIS-Aided Massive MIMO With Imperfect CSI and Phase Noise
May 06, 2024



Active reconfigurable intelligent surface (RIS) has attracted significant attention as a recently proposed RIS architecture. Owing to its capability to amplify the incident signals, active RIS can mitigate the multiplicative fading effect inherent in the passive RIS-aided system. In this paper, we consider an active RIS-aided uplink multi-user massive multiple-input multiple-output (MIMO) system in the presence of phase noise at the active RIS. Specifically, we employ a two-timescale scheme, where the beamforming at the base station (BS) is adjusted based on the instantaneous aggregated channel state information (CSI) and the statistical CSI serves as the basis for designing the phase shifts at the active RIS, so that the feedback overhead and computational complexity can be significantly reduced. The aggregated channel composed of the cascaded and direct channels is estimated by utilizing the linear minimum mean square error (LMMSE) technique. Based on the estimated channel, we derive the analytical closed-form expression of a lower bound of the achievable rate. The power scaling laws in the active RIS-aided system are investigated based on the theoretical expressions. When the transmit power of each user is scaled down by the number of BS antennas M or reflecting elements N, we find that the thermal noise will cause the lower bound of the achievable rate to approach zero, as the number of M or N increases to infinity. Moreover, an optimization approach based on genetic algorithms (GA) is introduced to tackle the phase shift optimization problem. Numerical results reveal that the active RIS can greatly enhance the performance of the considered system under various settings.