 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
E-Sparse: Boosting the Large Language Model Inference through Entropy-based N:M Sparsity
Oct 24, 2023



Traditional pruning methods are known to be challenging to work in Large Language Models (LLMs) for Generative AI because of their unaffordable training process and large computational demands. For the first time, we introduce the information entropy of hidden state features into a pruning metric design, namely E-Sparse, to improve the accuracy of N:M sparsity on LLM. E-Sparse employs the information richness to leverage the channel importance, and further incorporates several novel techniques to put it into effect: (1) it introduces information entropy to enhance the significance of parameter weights and input feature norms as a novel pruning metric, and performs N:M sparsity without modifying the remaining weights. (2) it designs global naive shuffle and local block shuffle to quickly optimize the information distribution and adequately cope with the impact of N:M sparsity on LLMs' accuracy. E-Sparse is implemented as a Sparse-GEMM on FasterTransformer and runs on NVIDIA Ampere GPUs. Extensive experiments on the LLaMA family and OPT models show that E-Sparse can significantly speed up the model inference over the dense model (up to 1.53X) and obtain significant memory saving (up to 43.52%), with acceptable accuracy loss.
RPTQ: Reorder-based Post-training Quantization for Large Language Models
Apr 25, 2023Large-scale language models (LLMs) have demonstrated outstanding performance on various tasks, but their deployment poses challenges due to their enormous model size. In this paper, we identify that the main challenge in quantizing LLMs stems from the different activation ranges between the channels, rather than just the issue of outliers.We propose a novel reorder-based quantization approach, RPTQ, that addresses the issue of quantizing the activations of LLMs. RPTQ rearranges the channels in the activations and then quantizing them in clusters, thereby reducing the impact of range difference of channels. In addition, we reduce the storage and computation overhead by avoiding explicit reordering. By implementing this approach, we achieved a significant breakthrough by pushing LLM models to 3 bit activation for the first time.
Improving Post-Training Quantization on Object Detection with Task Loss-Guided Lp Metric
Apr 25, 2023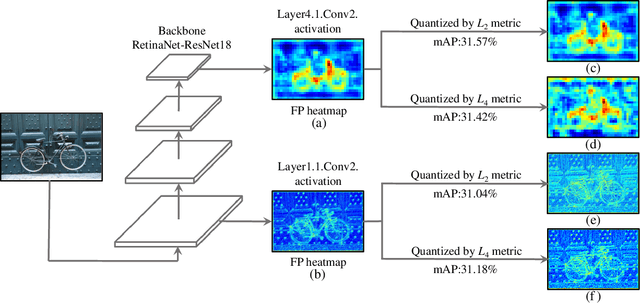

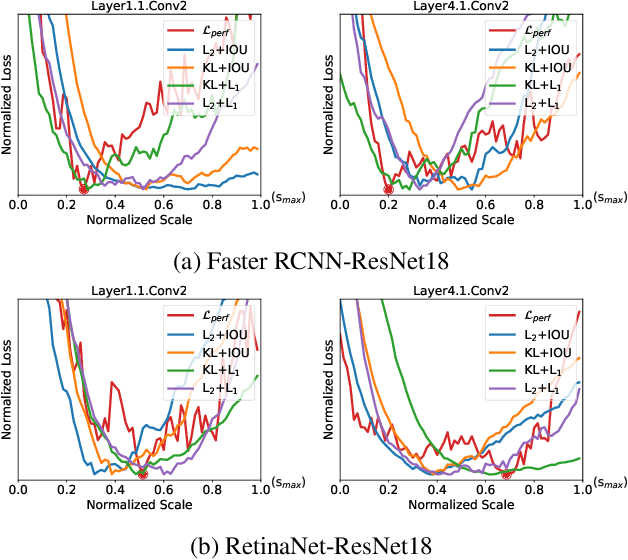

Efficient inference for object detection networks is a major challenge on edge devices. Post-Training Quantization (PTQ), which transforms a full-precision model into low bit-width directly, is an effective and convenient approach to reduce model inference complexity. But it suffers severe accuracy drop when applied to complex tasks such as object detection. PTQ optimizes the quantization parameters by different metrics to minimize the perturbation of quantization. The p-norm distance of feature maps before and after quantization, Lp, is widely used as the metric to evaluate perturbation. For the specialty of object detection network, we observe that the parameter p in Lp metric will significantly influence its quantization performance. We indicate that using a fixed hyper-parameter p does not achieve optimal quantization performance. To mitigate this problem, we propose a framework, DetPTQ, to assign different p values for quantizing different layers using an Object Detection Output Loss (ODOL), which represents the task loss of object detection. DetPTQ employs the ODOL-based adaptive Lp metric to select the optimal quantization parameters. Experiments show that our DetPTQ outperforms the state-of-the-art PTQ methods by a significant margin on both 2D and 3D object detectors. For example, we achieve 31.1/31.7(quantization/full-precision) mAP on RetinaNet-ResNet18 with 4-bit weight and 4-bit activation.
PD-Quant: Post-Training Quantization based on Prediction Difference Metric
Dec 14, 2022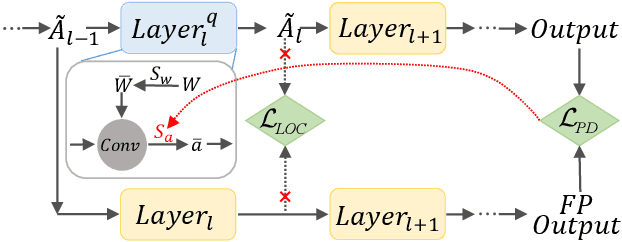
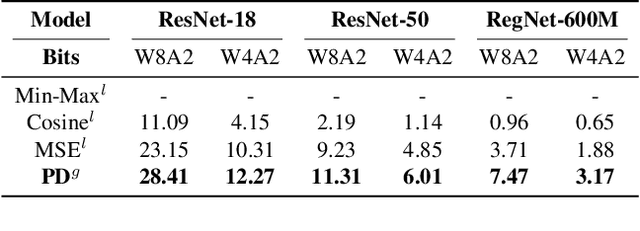

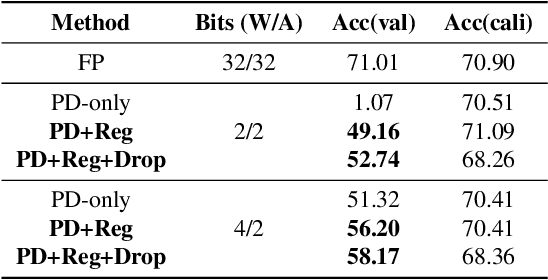
As a neural network compression technique, post-training quantization (PTQ) transforms a pre-trained model into a quantized model using a lower-precision data type. However, the prediction accuracy will decrease because of the quantization noise, especially in extremely low-bit settings. How to determine the appropriate quantization parameters (e.g., scaling factors and rounding of weights) is the main problem facing now. Many existing methods determine the quantization parameters by minimizing the distance between features before and after quantization. Using this distance as the metric to optimize the quantization parameters only considers local information. We analyze the problem of minimizing local metrics and indicate that it would not result in optimal quantization parameters. Furthermore, the quantized model suffers from overfitting due to the small number of calibration samples in PTQ. In this paper, we propose PD-Quant to solve the problems. PD-Quant uses the information of differences between network prediction before and after quantization to determine the quantization parameters. To mitigate the overfitting problem, PD-Quant adjusts the distribution of activations in PTQ. Experiments show that PD-Quant leads to better quantization parameters and improves the prediction accuracy of quantized models, especially in low-bit settings. For example, PD-Quant pushes the accuracy of ResNet-18 up to 53.08% and RegNetX-600MF up to 40.92% in weight 2-bit activation 2-bit. The code will be released at https://github.com/hustvl/PD-Quant.